我想stacked bar plot用seaborn或繪制一個matplotlib。我想獲得所有需要的資訊,.pivot_table然后我只想過濾計數最多的三個社區。但是有一個KeyError: 'neighbourhood'因為鄰域是 df_new 中的索引。
我怎么能從我的df_new(df.pivot_table必須是)一個只有前三個街區的堆積條形圖生成?
d = {'host_id': [1, 1, 2, 3, 3],
'listing_id': [1, 2, 3, 4, 5],
'neighbourhood': ['Sofia', 'New York', 'Berlin', 'London', 'London'],
'price': [50.0, 60.0, 50.0, 80.0, 90.0],
'room_type': ['Private', 'Private', 'Shared', 'Private', 'Shared']}
df = pd.DataFrame(data=d)
print(df)
[OUT]
host_id listing_id neighbourhood price room_type
0 1 1 Sofia 50.0 Private
1 1 2 New York 60.0 Private
2 2 3 Berlin 50.0 Shared
3 3 4 London 80.0 Private
4 3 5 London 90.0 Shared
df_new = df.pivot_table(index='neighbourhood', columns='room_type',
values='price', aggfunc='mean',
fill_value=0.0)
print(df_new)
[OUT]
room_type Private Shared
neighbourhood
Berlin 0 50
London 80 90
New York 60 0
Sofia 50 0
df_Best = df.groupby(["neighbourhood"])["room_type"].count().reset_index(
name="count").sort_values(
by=['count'], ascending=False).head(3)
print(df_Best)
[OUT]
neighbourhood count
1 London 2
0 Berlin 1
2 New York 1
df_new.loc[df_new['neighbourhood'].isin(df_Best['neighbourhood'].head(1).values[0])]
print(df_new)
[OUT]
KeyError: 'neighbourhood'
# Because neighbourhood is index in df_new
最后我想要類似的東西
uj5u.com熱心網友回復:
您可以使用 的"neighbourhood"列df_Best直接索引df_new. 例如df_new.loc[df_Best['neighbourhood'].head(1)]。
from matplotlib import pyplot as plt
import pandas as pd
d = {'host_id': [1, 1, 2, 3, 3],
'listing_id': [1, 2, 3, 4, 5],
'neighbourhood': ['Sofia', 'New York', 'Berlin', 'London', 'London'],
'price': [50.0, 60.0, 50.0, 80.0, 90.0],
'room_type': ['Private', 'Private', 'Shared', 'Private', 'Shared']}
df = pd.DataFrame(data=d)
df_new = df.pivot_table(index='neighbourhood', columns='room_type',
values='price', aggfunc='mean',
fill_value=0.0)
df_Best = df.groupby(["neighbourhood"])["room_type"].count().reset_index(
name="count").sort_values(
by=['count'], ascending=False).head(3)
df_new.loc[df_Best['neighbourhood']].plot.bar(stacked=True, rot=0)
plt.show()
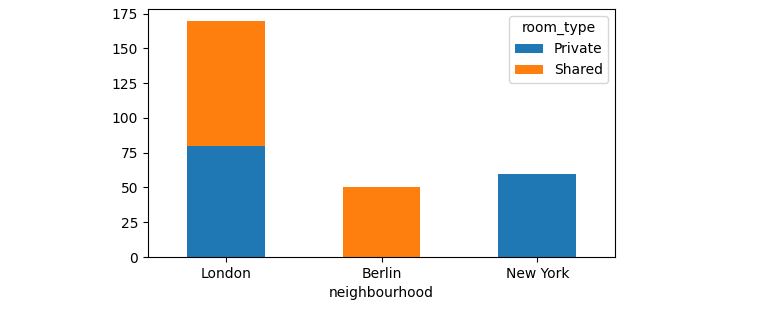
請注意,它df_new是通過df.pivot_table(...). 如果您真的想純粹從 中創建繪圖df.pivot_table,那么可讀性較差的形式是:
df.pivot_table(index='neighbourhood', columns='room_type', values='price', aggfunc='mean',
fill_value=0.0).loc[
df.groupby(["neighbourhood"])["room_type"].count().sort_values(ascending=False).head(3).index]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/353583.html
標籤:Python 熊猫 数据框 matplotlib 海生
上一篇:為什么Seaborn線圖“大小”爭論最終成為傳奇藝術家?
下一篇:如何將串列的資料框列繪制為水平線