如何找到有付款的賣家數量,其中連續時間少于1分鐘,哪些賣家連續執行至少3次?(答案是 2 個賣家)以及如何計算此類付款的數量?(答案是10付)貌似這樣的問題可以用視窗函式解決,不過我沒遇到過這種問題
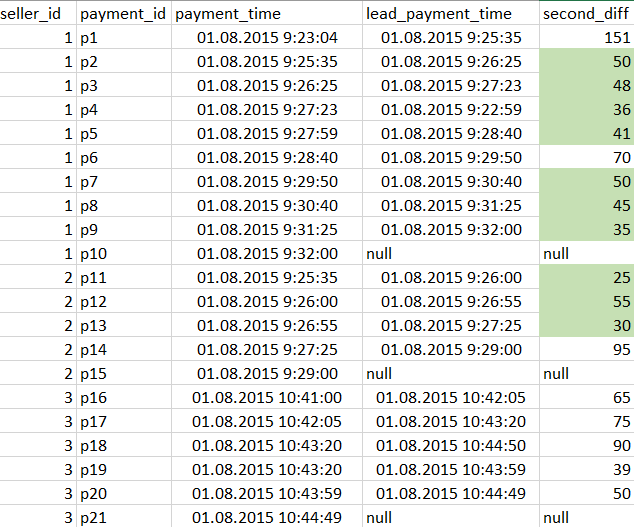
CREATE TABLE T (seller_id int, payment_id varchar(3), payment_time timestamp, second_diff int);
INSERT INTO T (seller_id, payment_id, payment_time, second_diff)
VALUES
(1, 'pl', '2015-01-08 09:23:04', 151),
(1, 'p2', '2015-01-08 09:25:35', 50),
(1, 'p3', '2015-01-08 09:26:25', 48),
(1, 'p4', '2015-01-08 09:27:23', 36),
(1, 'p5', '2015-01-08 09:27:59', 41),
(1, 'p6', '2015-01-08 09:28:40', 70),
(1, 'p7', '2015-01-08 09:29:50', 50),
(1, 'p8', '2015-01-08 09:30:40', 45),
(1, 'p9', '2015-01-08 09:31:25', 35),
(1, 'p10', '2015-01-08 09:32:00', null),
(2, 'pll', '2015-01-08 09:25:35', 25),
(2, 'p12', '2015-01-08 09:26:00', 55),
(2, 'p13', '2015-01-08 09:26:55', 30),
(2, 'p14', '2015-01-08 09:27:25', 95),
(2, 'p15', '2015-01-08 09:29:00', null),
(3, 'p16', '2015-01-08 10:41:00', 65),
(3, 'p17', '2015-01-08 10:42:05', 75),
(3, 'p18', '2015-01-08 10:43:20', 90),
(3, 'p19', '2015-01-08 10:43:20', 39),
(3, 'p20', '2015-01-08 10:43:59', 50),
(3, 'p21', '2015-01-08 10:44:49', null);
uj5u.com熱心網友回復:
使用帶有 OVER 子句的聚合函式,該子句包含一個整數除以 60,然后對該除法進行過濾以獲得結果 0
WITH T AS
(
SELECT ... COUNT(*) OVER(PARTITION BY second_diff / 60) AS CNT, second_diff / 60 AS GRP
FROM ....
)
SELECT * FROM T
WHERE GRP = 0
uj5u.com熱心網友回復:
with A as (
select seller_id, payment_time, second_diff,
case when
lag(case when second_diff < 60 then 1 else 0 end)
over (partition by seller_id order by payment_time)
= case when second_diff < 60 then 1 else 0 end
then 0 else 1 end as transition
from T
), B as (
select *,
sum(transition)
over (partition by seller_id order by payment_time) as grp
from A
), C as (
select seller_id, count(*) as p
from B
where second_diff < 60
group by seller_id, grp
having count(*) >= 3
)
select count(distinct seller_id) as sellers, sum(p) as payments
from C;
這種方法尋找值中的轉換,并將它們計數。case只要它們匹配,內部運算式的輸出值并不重要。
https://dbfiddle.uk/?rdbms=postgres_9.6&fiddle=606b796d793248336a95637f02ce117b
以下是主題的一些變化:
選項#1b:
with A as (
select seller_id, payment_time, second_diff,
case when
lag(case when second_diff < 60 then 1 else 0 end)
over (partition by seller_id order by payment_time)
= case when second_diff < 60 then 1 else 0 end
then 0 else 1 end as transition
from T
), B as (
select *,
sum(transition)
over (partition by seller_id order by payment_time) as grp
from A
)
select
dense_rank() over (order by seller_id)
dense_rank() over (order by seller_id desc) - 1 as sellers,
sum(count(*)) over () as payments
from B
where second_diff < 60
group by seller_id, grp
having count(*) >= 3
limit 1;
This is just a different way to do the count(distinct) in one step.
Option #2:
with A as (
select seller_id, payment_time, second_diff,
row_number() over (partition by seller_id order by payment_time) as rn
from T
), B as (
select *,
rn - row_number() over (partition by seller_id order by payment_time) as grp
from A
where second_diff < 60
), C as (
select seller_id, count(*) as p
from B
group by seller_id, grp
having count(*) >= 3
)
select count(distinct seller_id) as sellers, sum(p) as payments
from C;
This method uses row numbering pre- and post-filtering find breaks in the series.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/358144.html
標籤:sql PostgreSQL的 窗函数 青梅 分析的
上一篇:Sqlsum值不同的id
下一篇:結束日期為空值:db2-sql