我有兩個陣列。
org_df = [2732.64, 2296.35, 1262.28, 567.6, 436.29, 262.98, 238.74, 210.38,19]
calc_df = [19, 2296.34, 436.3, 2732.64]
我想比較這些陣列并創建一個具有相同元素和 0.01 容差的新陣列。
new_list = [2732.64, 2296.35 ,436.29,19]
我添加了代碼但它不起作用:
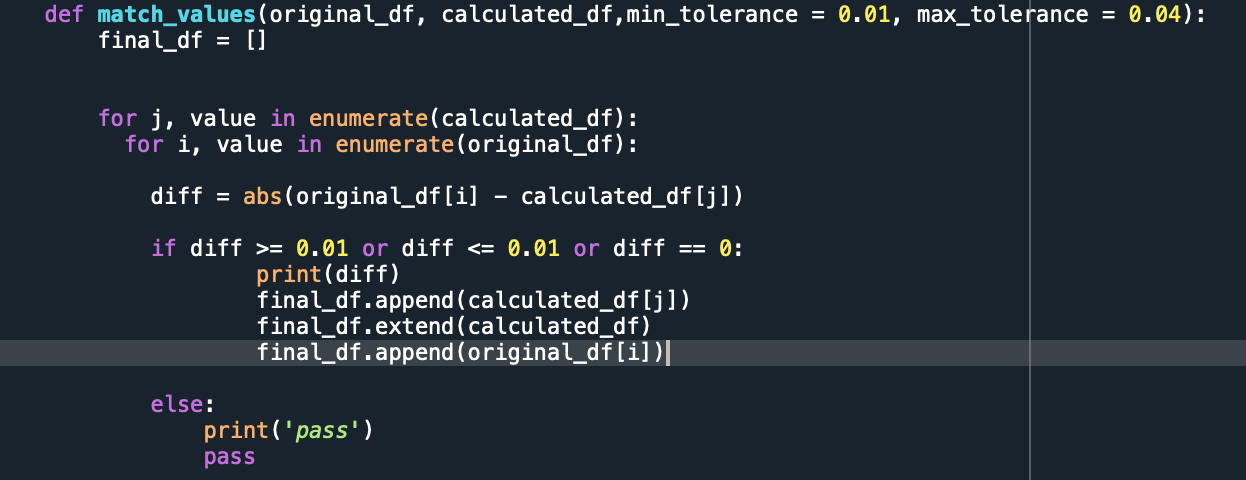
uj5u.com熱心網友回復:
您可以使用numpy模塊的isclose功能來做到這一點。
new_list = [i for i in org_df if np.any(np.isclose(i, calc_df, atol=0.01))]
uj5u.com熱心網友回復:
如果您使用numpy:
org_df = np.array([2732.64, 2296.35, 1262.28, 567.6, 436.29, 262.98, 238.74, 210.38,19])
calc_df = np.array([19, 2296.34, 436.3, 2732.64])
new_list = org_df[np.any(np.abs(org_df - calc_df[:, None]) <= 0.01, axis=0)]
print(new_list)
# Output:
array([2732.64, 2296.35, 436.29, 19. ])
uj5u.com熱心網友回復:
如果你不想使用像 numpy 這樣的依賴項,你可以使用串列理解和 python 的范圍比較來做到這一點。Python 非常適合這個!
diff = abs(tolerance)
new_list = [y for x in org_df for y in calc_df if (y-diff <= x <= y diff)]
給出準確的結果。雖然它可能比 numpy 陣列慢。
uj5u.com熱心網友回復:
為了避免添加像 numpy 這樣的依賴項,您需要遍歷兩個串列并執行如下操作:
new_list = []
for a in org_df:
for b in calc_df:
if -0.01 < a - b < 0.01:
new_list.append(a)
如果您想改用串列理解,請使用以下一行代碼:
new_list = [a for a in org_df for b in calc_df if -0.01 < a - b < 0.01]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/368753.html
上一篇:如何在numpy中填充大陣列?
下一篇:在GoogleScript中使用worksheet.getrange.setvalues時出錯。我有兩個看起來相同的陣列。一個按預期作業,但另一個失敗