我有2個dataframesdf1并df2在其中df1只包含0。我們不妨將套列df1,并df2通過col1和col2分別。對于 in 的每個列名col2,如果它屬于col1,我會將對應的列 in 替換為對應的df1in df2。
在我的例子中,df1是
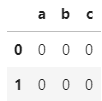
并且df2是
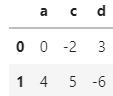
然后我想要的結果是
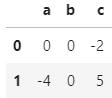
為此,我使用回圈遍歷col2. 但是,Python 回傳警告
性能警告:DataFrame 高度分散。這通常是
frame.insert多次呼叫的結果,性能較差。考慮使用 pd.concat(axis=1) 一次連接所有列。要獲得碎片整理的幀,請使用newframe = frame.copy()
你能詳細說明一個更有效的方法嗎?
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.array([[0, 0, 0], [0, 0, 0]]),
columns=['a', 'b', 'c'])
df2 = pd.DataFrame(np.array([[0, -2, 3], [4, 5, -6]]),
columns=['a', 'c', 'd'])
for c in df2.columns:
if c in df1.columns:
df1[c] = df2[c]
uj5u.com熱心網友回復:
您可以使用DataFrame.update更新現有的資料框。因為,df2沒有額外的列也會df1 DataFrame.update添加它們。要僅更新正確的列/索引,我們可以pd.Index.intersection在此處使用。
cols = df2.columns.intersection(df1.columns)
idx = df2.index.intersection(df1.index)
df1.update(df2.loc[idx, cols])
print(df1)
a b c
0 0 0 -2
1 4 0 5
uj5u.com熱心網友回復:
我相信通過替換
df1[c] = df2[c]
和
df1[c][:] = df2[c]
您可以確保就地覆寫列,而不是插入具有相同名稱的新列并洗掉原始列。這應該可以防止碎片化。這只適用于所有資料都具有相同型別的情況。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/369411.html