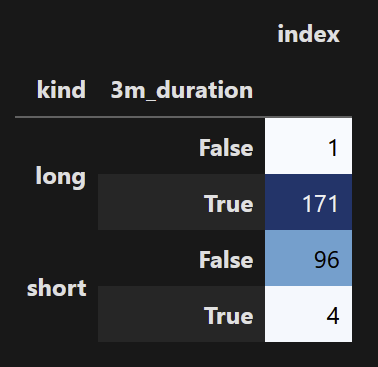
我可以在多索引上做熊貓樣式的熱圖沒問題:
df = sns.load_dataset('geyser').reset_index()
df['3m_duration'] = df.duration > 3
group_cols = ['kind', '3m_duration']
count_gpby = df[
group_cols ['index']
].groupby(
group_cols
)
count_gpby.count().style.background_gradient(cmap ='Blues')
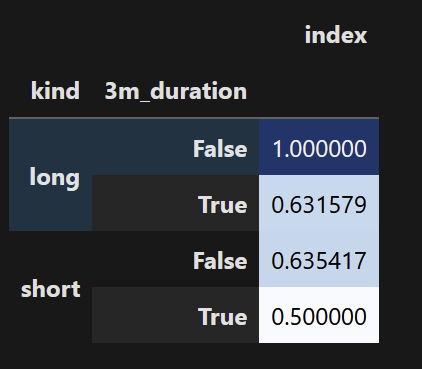
我還可以將子集 groupby 除以總 groupby 以獲得每組的比較比率/比率:
df['binary'] = 'A'
df.loc[100:, 'binary'] = 'B'
subset_gpby = df[
group_cols ['index']
].loc[df.binary=='B'].groupby(
group_cols
).count()
(subset_gpby / gpby).style.background_gradient(cmap ='Blues')
但隨后我嘗試將這兩個“視圖”組合為同一多索引資料框中的兩列,以便我可以同時查看原始計數和比較比率。這沒有問題列印:

但是由于“非唯一索引”,它無法與 Pandas 樣式的熱圖背景漸變一起顯示:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-275-f82cbb6545e2> in <module>
----> 1 pd.concat([(subset_gpby / gpby), gpby], axis=1).style.background_gradient(cmap ='Blues')
C:\ProgramData\Anaconda3\envs\venv\lib\site-packages\pandas\core\frame.py in style(self)
959 from pandas.io.formats.style import Styler
960
--> 961 return Styler(self)
962
963 _shared_docs[
C:\ProgramData\Anaconda3\envs\venv\lib\site-packages\pandas\io\formats\style.py in __init__(self, data, precision, table_styles, uuid, caption, table_attributes, cell_ids, na_rep, uuid_len)
161 data = data.to_frame()
162 if not data.index.is_unique or not data.columns.is_unique:
--> 163 raise ValueError("style is not supported for non-unique indices.")
164
165 self.data = data
ValueError: style is not supported for non-unique indices.
然而,
pd.concat([(subset_gpby / gpby), gpby], axis=1).index.value_counts()
> (short, False) 1
> (short, True) 1
> (long, True) 1
> (long, False) 1
> dtype: int64
顯示每個索引只有一個實體,并且該索引等于之前渲染沒有問題的索引:
pd.concat([(subset_gpby / gpby), gpby], axis=1).index == (subset_gpby / gpby).index
> array([ True, True, True, True])
為什么會出現這個錯誤?
uj5u.com熱心網友回復:
在熊貓中,“索引”和“列”都是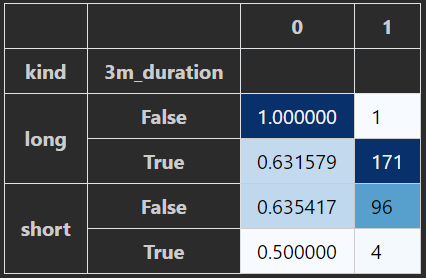
使用的設定:
import pandas as pd
import seaborn as sns
# Setup Data
df = sns.load_dataset('geyser').reset_index()
group_cols = ['kind', '3m_duration']
df['3m_duration'] = df['duration'].gt(3)
subset_df = df[[*group_cols, 'index']].copy()
# Build Count DataFrames
gpby = subset_df.groupby(group_cols).count()
subset_gpby = subset_df.loc[100:, :].groupby(group_cols).count()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/369439.html
上一篇:比較兩個資料幀中的資料