我在使用熊貓時遇到了一些困難..
我有 2 個資料幀(命名為bru和bru2),它們都來自幾乎同一個檔案。這兩個檔案之間的唯一區別是我添加了一個額外的行并將單元格值從“4”更改為“50000”以進行測驗。
我現在想做的是尋找更改的單元格和新行。
但首先,我正在檢查兩個資料幀是否相同,這樣當兩個檔案具有完全相同的資料時,我就不必尋找更改。
當我嘗試比較它們 (bru == bru2) 時,出現錯誤:Can only compare identically-labeled DataFrame objects.
我正在匯入這樣的檔案,我還洗掉了一些我不需要的列,以完全相同的順序重新排列兩個檔案的列并重命名一些以供優先:
bru = pd.read_csv("file1.csv", dtype={"street_id": "string", "address_id": "string"})
bru = bru.fillna('')
bru = bru.drop(columns=["EPSG:31370_x", "EPSG:31370_y", "EPSG:4326_lat", "EPSG:4326_lon", "postname_fr", "postname_nl", "streetname_de"])
bru = bru.rename(columns={"postcode": "pkancode"})
bru = bru.reindex(columns=["address_id", "box_number", "house_number", "municipality_id", "municipality_name_de", "municipality_name_fr", "municipality_name_nl", "pkancode", "street_id", "streetname_nl", "streetname_fr", "region_code", "status"])
bru2 = pd.read_csv("file2.csv", dtype={"street_id": "string", "address_id": "string"})
bru2 = bru2.fillna('')
bru2 = bru2.drop(columns=["EPSG:31370_x", "EPSG:31370_y", "EPSG:4326_lat", "EPSG:4326_lon", "postname_fr", "postname_nl", "streetname_de"])
bru2 = bru2.rename(columns={"postcode": "pkancode"})
bru2 = bru2.reindex(columns=["address_id", "box_number", "house_number", "municipality_id", "municipality_name_de", "municipality_name_fr", "municipality_name_nl", "pkancode", "street_id", "streetname_nl", "streetname_fr", "region_code", "status"])
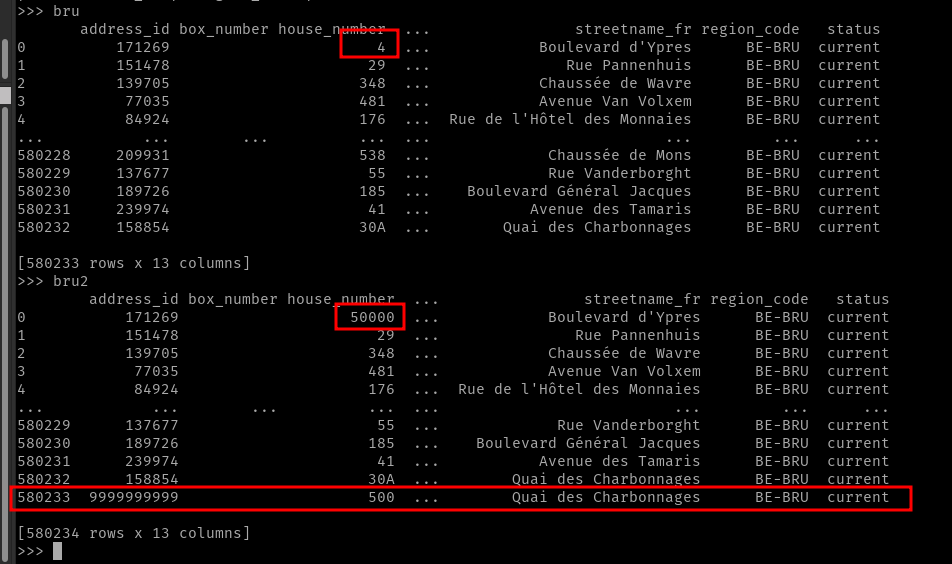
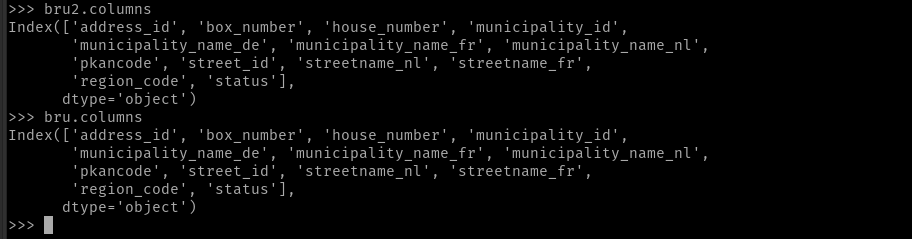
我究竟做錯了什么?
我已經嘗試了堆疊中的其他解決方案,但由于某種原因對我來說失敗了:
錯誤:只能比較標記相同的 DataFrame 物件
Pandas“只能比較標記相同的 DataFrame 物件”錯誤
uj5u.com熱心網友回復:
您可以使用reindex_like使 bru2 具有與 bru 相同的索引,然后比較資料幀。
bru2.reindex_like(bru).compare(bru)
您可以使用pd.Index.difference來查找 bru2 中 bru 中的行或列。
bru.index.difference(bru2.index) #and like wise with bru.columns and bru2.columns
uj5u.com熱心網友回復:
一種解決方案是首先按照本答案中的指示對索引進行排序。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/370800.html
上一篇:如何僅將字典值中的第一個字母大寫