在這里,我試圖獲取圖片中顯示的表中每一列的值(對于三個不同的頁面)并將它們存盤在 Pandas 資料框中。我已經收集了資料,現在我有了一個串列串列,但是當我嘗試將它們添加到字典時,我得到了空字典。任何人都可以幫助我我做錯了什么或建議另一種方法來創建 3 個資料框,每個表一個?
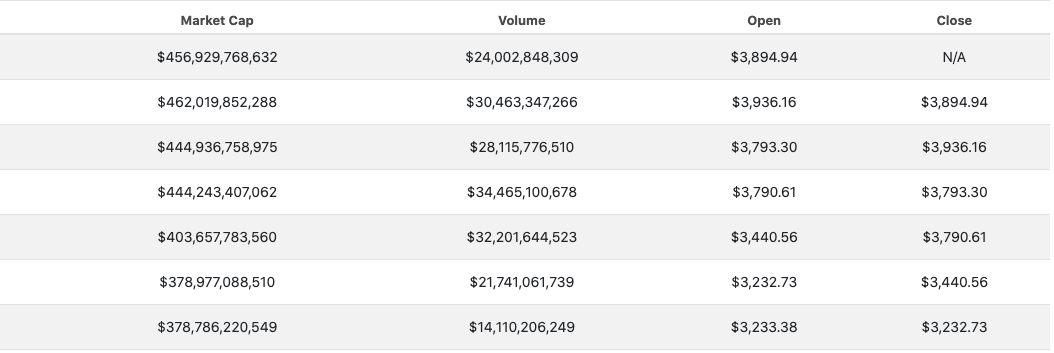
這是我的代碼:
import numpy as np
import pandas as pd
from datetime import datetime
import pytz
import requests
import json
from bs4 import BeautifulSoup
url_list = ['https://www.coingecko.com/en/coins/ethereum/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/cardano/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/chainlink/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel']
results = []
for url in url_list:
response = requests.get(url)
src = response.content
soup = BeautifulSoup(response.text , 'html.parser')
results.append(soup.find_all( "td",class_= "text-center"))
collected_data = dict()
for result in results:
for r in result:
datas = r.find_all("td", title=True)
for data in datas:
collected_data.setdefault(data.text)
collected_data
uj5u.com熱心網友回復:
發生什么了?
在您的第一個中,for loop您只將結果集附加soup.find_all( "td",class_= "text-center")到results。
所以你不會找到你要找的東西 datas = r.find_all("td", title=True)
還要注意,列標題不放在<td>而是在<th>。
怎么修?
您可以選擇更具體的,都<tr>在<tbody>遍歷:
for row in soup.select('tbody tr'):
在迭代時選擇<th>和<td>和zip()它dict()與列標題串列:
data.append(
dict(zip([x.text for x in soup.select('thead th')], [x.text.strip() for x in row.select('th,td')]))
)
例子
import pandas as pd
import requests
from bs4 import BeautifulSoup
url_list = ['https://www.coingecko.com/en/coins/ethereum/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/cardano/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel',
'https://www.coingecko.com/en/coins/chainlink/historical_data/usd?start_date=2021-08-06&end_date=2021-09-05#panel']
data = []
for url in url_list:
response = requests.get(url)
src = response.content
soup = BeautifulSoup(response.text , 'html.parser')
for row in soup.select('tbody tr'):
data.append(
dict(zip([x.text for x in soup.select('thead th')], [x.text.strip() for x in row.select('th,td')]))
)
pd.DataFrame(data)
輸出
| 日期 | 市值 | 體積 | 打開 | 關閉 |
|---|---|---|---|---|
| 2021-09-05 | 456,929,768,632 美元 | 24,002,848,309 美元 | 3,894.94 美元 | 不適用 |
| 2021-09-04 | 462,019,852,288 美元 | 30,463,347,266 美元 | 3,936.16 美元 | 3,894.94 美元 |
| 2021-09-03 | 444,936,758,975 美元 | 28,115,776,510 美元 | 3,793.30 美元 | 3,936.16 美元 |
編輯
要獲取每個 url 的資料幀,您可以將代碼更改為以下內容 - 它將幀附加到串列中,以便您可以迭代執行操作。
注意 這是基于您的評論,如果合適,可以。我建議將硬幣提供者也存盤為列,這樣您就可以對所有提供者進行過濾、分組……但如果重要的話,應該在新問題中提出這一問題。
dfList = []
for url in url_list:
response = requests.get(url)
src = response.content
soup = BeautifulSoup(response.text , 'html.parser')
data = []
coin = url.split("/")[5].upper()
for row in soup.select('tbody tr'):
data.append(
dict(zip([f'{x.text}_{coin}' for x in soup.select('thead th')], [x.text.strip() for x in row.select('th,td')]))
)
# if you like to save directly as csv... change next line to -> pd.DataFrame(data).to_csv(f'{coin}.csv')
dfList.append(pd.DataFrame(data))
輸出
例如,按串列索引選擇資料框 dfList[0]
| 日期_以太坊 | 市值_以太坊 | 體積_以太坊 | 打開_以太坊 | 關閉_以太坊 |
|---|---|---|---|---|
| 2021-09-05 | 456,929,768,632 美元 | 24,002,848,309 美元 | 3,894.94 美元 | 不適用 |
| 2021-09-04 | 462,019,852,288 美元 | 30,463,347,266 美元 | 3,936.16 美元 | 3,894.94 美元 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/373940.html