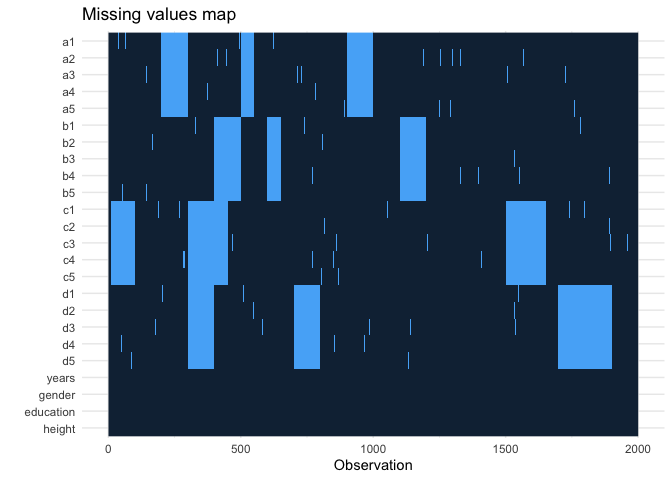
我有一個 100 行、200 個變數的資料集(主要是李克特規模的調查資料作為因子,但也有一些數字資料)。我在下面附上了一個具有類似缺失資料模式的reprex;一些空白單元格是零星的,但對于某些行,整個比例尺都是空白的。
我想在子尺度計算之前使用mice包的多重插補,但是對因子密集型資料集進行多重插補是不切實際的。但是,我需要在計算子尺度總計之前解決零星缺失的單元格,因為如果尺度中的一項是,那么子尺度總計也將是。NANA
我的目標是對偶發缺失的因子單元格進行單一/平均插補,然后計算子尺度總計,然后對數字子尺度總計變數進行多重插補,這將針對剩余的大差距。
我希望用個人剩余尺度變數的平均值來估算零星缺失的值。例如,如果一個人缺失,df$c2那么該缺失值將被估算為 c1、c3、c4 和 c5 的平均值。
如何根據每行中的缺失模式對資料子集進行單一/均值插補?
library(reprex)
library(tidyverse)
library(missMethods)
library(finalfit)
library(mice)
set.seed(1234)
a1 <- sample(1:3, 2000, replace=TRUE)
a2 <- sample(1:3, 2000, replace=TRUE)
a3 <- sample(1:3, 2000, replace=TRUE)
a4 <- sample(1:3, 2000, replace=TRUE)
a5 <- sample(1:3, 2000, replace=TRUE)
b1 <- sample(1:3, 2000, replace=TRUE)
b2 <- sample(1:3, 2000, replace=TRUE)
b3 <- sample(1:3, 2000, replace=TRUE)
b4 <- sample(1:3, 2000, replace=TRUE)
b5 <- sample(1:3, 2000, replace=TRUE)
c1 <- sample(1:3, 2000, replace=TRUE)
c2 <- sample(1:3, 2000, replace=TRUE)
c3 <- sample(1:3, 2000, replace=TRUE)
c4 <- sample(1:3, 2000, replace=TRUE)
c5 <- sample(1:3, 2000, replace=TRUE)
d1 <- sample(1:3, 2000, replace=TRUE)
d2 <- sample(1:3, 2000, replace=TRUE)
d3 <- sample(1:3, 2000, replace=TRUE)
d4 <- sample(1:3, 2000, replace=TRUE)
d5 <- sample(1:3, 2000, replace=TRUE)
years <- sample(18:70, 2000, replace=TRUE)
gender <- sample(c("male","female"), 2000, replace=TRUE, prob=c(0.5, 0.5))
education <- sample(c("highschool","college", "gradschool"), 2000, replace=TRUE, prob=c(1/3, 1/3, 1/3))
height <- sample(60:75, 2000, replace=TRUE)
df <- data.frame(a1, a2, a3, a4, a5,
b1, b2, b3, b4, b5,
c1, c2, c3, c4, c5,
d1, d2, d3, d4, d5,
years, gender, education, height)
facts <- df %>% select(contains("gender") | contains ("education")) %>% colnames()
cols <- df %>% select(ends_with("1") |
ends_with("2") |
ends_with("3") |
ends_with("4") |
ends_with("5")) %>% colnames()
df <- delete_MCAR(df, p = 0.01, cols_mis = cols) %>%
dplyr::mutate(across(all_of(facts), factor))
df[c(200:300, 500:550, 900:1000), 1:5] <- NA
df[c(400:500, 600:650, 1100:1200), 6:10] <- NA
df[c(10:100, 300:450, 1500:1650), 11:15] <- NA
df[c(300:400, 700:800, 1700:1900), 16:20] <- NA
## I think mean imputation of the sporadically-missing cells would occur here
missing_plot(df)
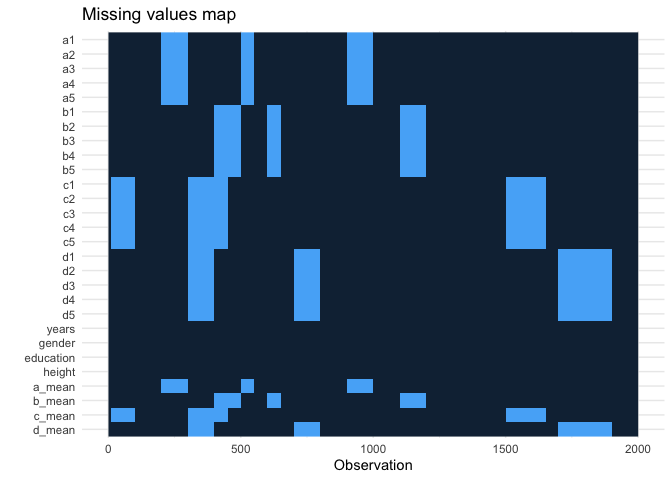
df <- df %>%
rowwise() %>%
mutate(a_mean = mean(c(a1, a2, a3, a4, a5))) %>%
mutate(b_mean = mean(c(b1, b2, b3, b4, b5))) %>%
mutate(c_mean = mean(c(c1, c2, c3, c4, c5))) %>%
mutate(d_mean = mean(c(d1, d2, d3, d4, d5)))
df <- df %>%
select(ends_with("mean") | contains("years") | contains("gender") | contains("education") | contains("height"))
imp_df <- mice::mice(df, m = 5, print = FALSE)
com <- mice::complete(imp_df)
uj5u.com熱心網友回復:
我是否理解正確,您只是想mean對每個a1...d5單獨進行處理,僅在偶爾丟失缺失值的情況下?然后我們可以定義一個函式,通過篩選來識別NA小于特定長度的連續值。我的方法基于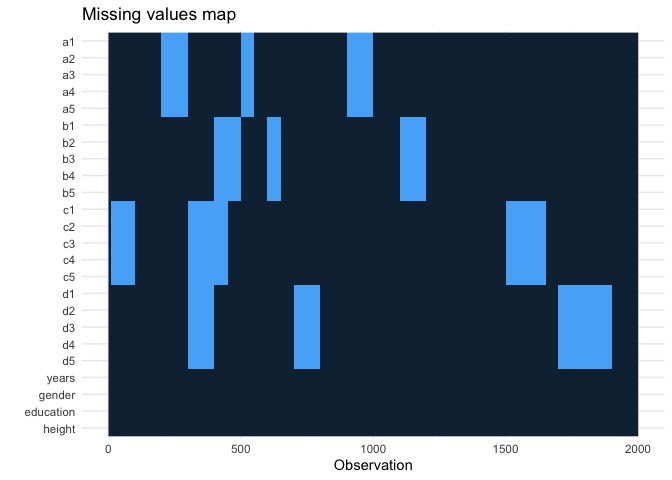
填充其他尺度變數的平均值
如果我們想填充其他尺度變數,我們采用類似的方法。只是一些注意事項:
- 我們需要從
rowwise()比例均值中洗掉缺失值,否則它就是NA我們有缺失值的任何地方,無論如何我們都無法進行任何插補。 - 我們應該總是
ungroup()在使用后rowwise()否則很容易忘記并回傳奇怪的結果。 - 我們將使用 的一些功能
across()來訪問cur_column()名稱,對字母進行子集化,并x_mean在.data. - 定義一個
infill_fun()來做上面的包裝na_search()。
df <- df %>%
rowwise() %>%
mutate(a_mean = mean(c(a1, a2, a3, a4, a5), na.rm = T)) %>%
mutate(b_mean = mean(c(b1, b2, b3, b4, b5), na.rm = T)) %>%
mutate(c_mean = mean(c(c1, c2, c3, c4, c5), na.rm = T)) %>%
mutate(d_mean = mean(c(d1, d2, d3, d4, d5), na.rm = T)) %>%
ungroup()
infill_fun <- function(x, threshold, df, cur_col) {
mean_col <- paste0(substr(cur_col, 1, 1), "_mean")
ifelse(na_search(x, threshold),
df[[mean_col]],
x)
}
df %>%
mutate(across(
matches("[a-z][1-9]"),
~ infill_fun(
.x,
threshold = 5,
df = .data,
cur_col = cur_column()
)
)) %>%
missing_plot()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/378697.html