我目前正在研究一個資料集,其中包含有關每個產品 ID 和產品子類別的總銷售額的資訊。例如,讓我們考慮有三個產品 1、2 和 3。有三個產品子類別 - A、B、C,其中一個或兩個或全部可能包含產品 1、2 和 3。例如,我在下面包含了一個示例表:
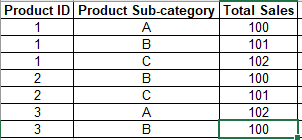
現在,我想添加一個標志列“Flag”,它可以根據該產品 id 是否包含產品子類別“C”的記錄為每個產品 id 分配 1 或 0。如果它確實包含“C”,則將 1 分配給標志列。否則,分配 0。以下是所需的輸出。
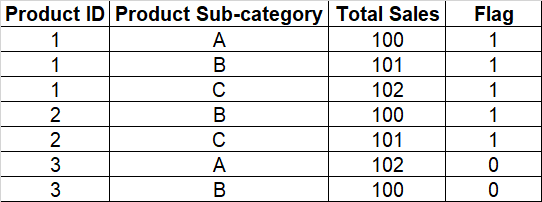
我目前無法在熊貓中做到這一點。你能幫我嗎?太感謝了!
uj5u.com熱心網友回復:
使用熊貓變換和包含。transform 將 lambda 函式應用于資料幀中的所有行。
txt="""ID,Sub-category,Sales
1,A,100
1,B,101
1,C,102
2,B,100
2,C,101
3,A,102
3,B,100"""
df = pd.read_table(StringIO(txt), sep=',')
#print(df)
list_id=list(df[df['Sub-category'].str.contains('C')]['ID'])
df['flag']=df['ID'].apply(lambda x: 1 if x in list_id else 0 )
print(df)
輸出:
ID Sub-category Sales flag
0 1 A 100 1
1 1 B 101 1
2 1 C 102 1
3 2 B 100 1
4 2 C 101 1
5 3 A 102 0
6 3 B 100 0
uj5u.com熱心網友回復:
試試這個:
Flag = [ ]
for i in dataFrame["Product sub-category]:
if i == "C":
Flag.append(1)
else:
Flag.append(0)
所以你有一個名為“Flag”的串列,可以將它添加到你的資料框中。
uj5u.com熱心網友回復:
您可以添加一個臨時列,isC以檢查您的狀況。然后檢查isC每個“產品 ID”組中的's數量(帶有.groupby(...).transform)。
check = (
df.assign(isC=lambda df: df["Product Sub-category"] == "C")
.groupby("Product Id").isC.transform("sum")
)
df["Flag"] = (check > 0).astype(int)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/383051.html
上一篇:將資料幀從時間戳轉換為時間間隔