目錄
Series
DataFrame
DataFrame常用的方法
loc:可以通過行索引查看一行資料
讀取檔案(.csv)的方法
洗掉一行或者一列的資料
查看dataframe引數
布爾索引篩選資料
groupby 和 count
reset_index() :重置索引
rename() :修改列的索引名稱
sort_values('列名') 根據列中值的大小,從小到大排序
截取前n行資料 :切片
關聯操作join()
drop() 洗掉一列的資料
排名rank()
pandas提供了使我們能夠快速便捷地處理大量結構化資料, pandas兼具NumPy高性能的陣列計算功能以及電子表格和關系型資料庫靈活的資料處理功能
Series
Series 類似表格中的一個列(column),類似于一維陣列,可以保存任何資料型別,
Series 由索引(index)和列組成,既然有索引就可以通過索引查找對應的值
如果我們只傳入了值,會自動生從0開始的索引
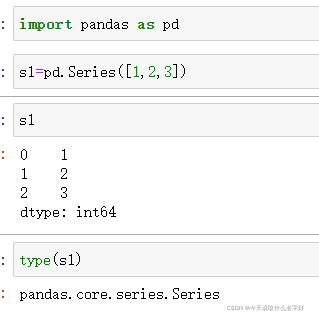
也可以通過手動傳入索引
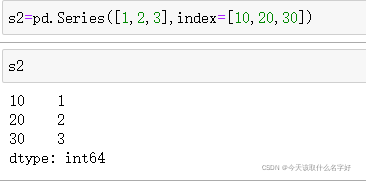
numpy中的大部分函式也是可以使用的,比如最大值max()和平均數mean()
DataFrame
DataFrame 是一個表格型的資料結構,它含有多個列,DataFrame 既有行索引也有列索引,它可以被看做由 Series 組成的字典(一個列的資料共同用一個列索引),
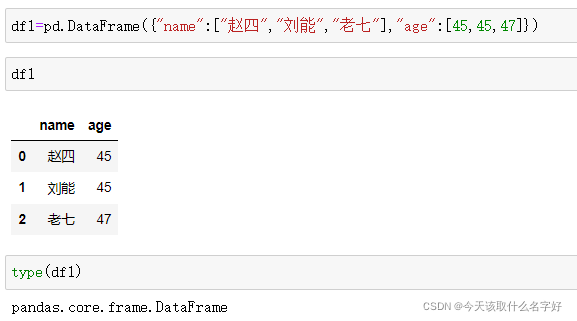
為什么說是由Series組成的字典呢?
我們單獨取出一個列的資料看看,他的型別果然是Series

取出2個列的資料看看型別,果然開始變成DataFrame了,所以他們的差別就是資料是不是只有一列
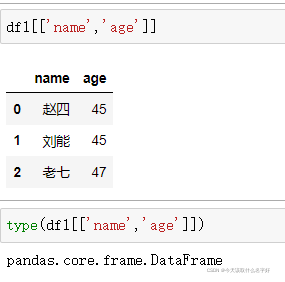
所以我們可以通過Series構建DataFrame
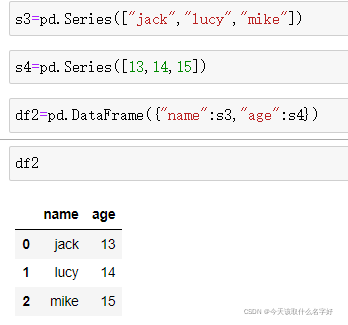
DataFrame常用的方法
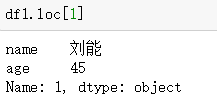
loc:可以通過行索引查看一行資料
還是使用上面的df1物件
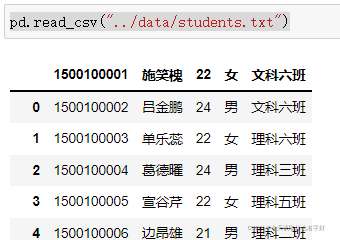
讀取檔案(.csv)的方法
csv檔案是用逗號作為分隔符的檔案
格式read_csv(檔案路徑)
但是這樣是有問題的,他把我們的第一行資料當成了列的索引,所以我們需要重新給他傳一個索引
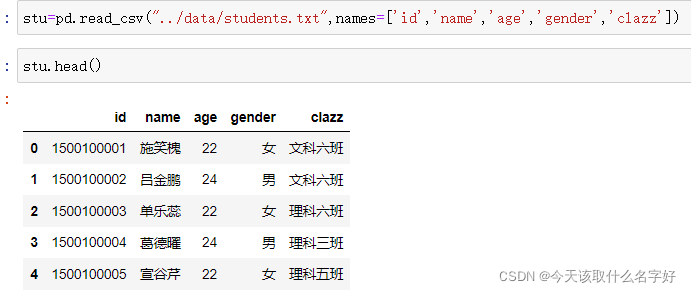
在上面的基礎上,加上 : 用names=[傳入的索引內容...]
head()顯示前5行資料,tail()顯示后5條資料
(head()里面也可以傳入int型別數值,但是最多就顯示20條)
洗掉一行或者一列的資料
#如果是洗掉一列元素要指定axis是1
stu.drop('name',axis = 1,inplace = True)
#洗掉行資料,傳入行的的索引范圍
stu.drop([0,1],inplace = True)
#洗掉行資料,可以自由選擇行數
stu.drop(index = [1,3,5],inplace = True)查看dataframe引數
info:顯所有資料的型別

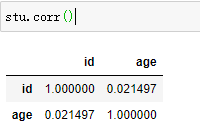
corr():查看列之間相關程度(首先得是數值型別)
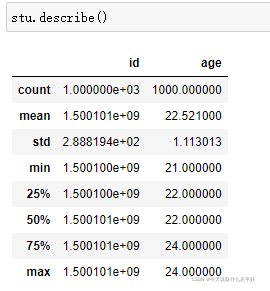
describe():查看列值的在統計方面的部分參考值
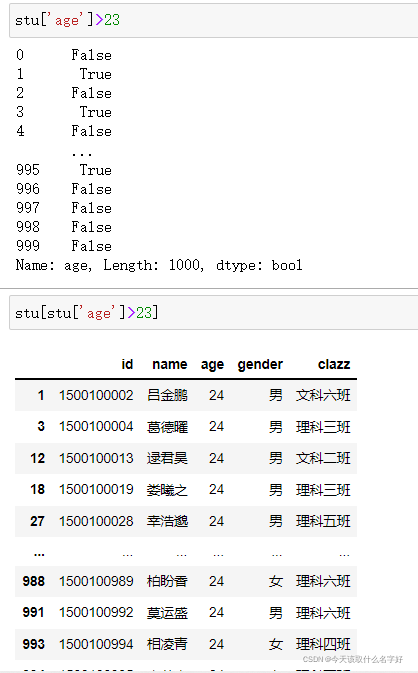
布爾索引篩選資料
類似numpy,我們也可以使用布爾索引來篩選資料
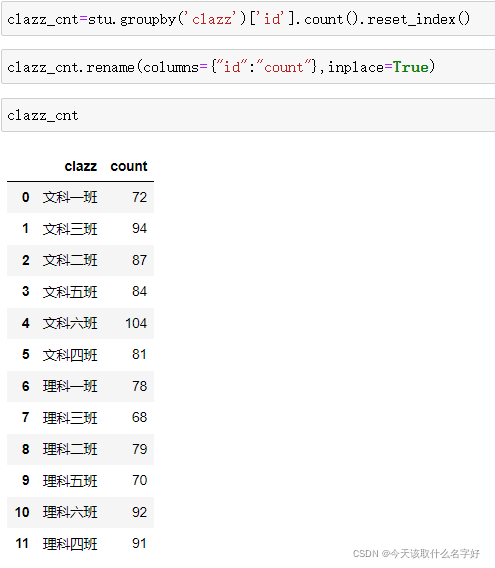
groupby 和 count
求每個班級的人數,首先可以直接使用gruop by 分組,取出任意一列元素進行count
沒有出現粗字體說明這是Series型別,我們可以給他重新設定一個索引,釋放clazz列

reset_index() :重置索引

rename() :修改列的索引名稱
格式:rename(columns={"原來的列名:新的列名"})
但是這個修改并不會對資料本身進行修改,我們還需要設定inplace=True,讓我們做出的改動作用在這個資料本身
sort_values('列名') 根據列中值的大小,從小到大排序
如果想要從大到小排序,在上面的基礎上再設定: ascending=False
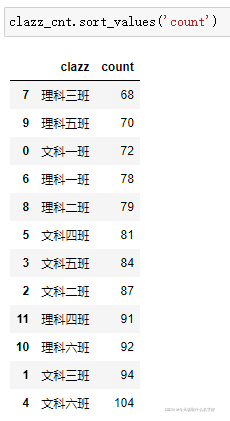
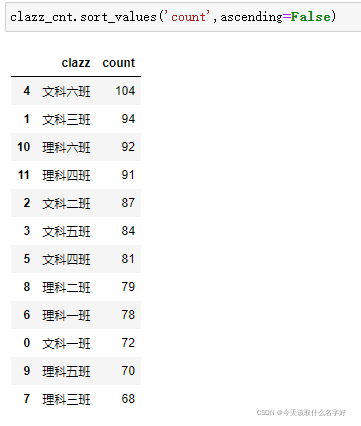
截取前n行資料 :切片
可以通過切片實作截取資料
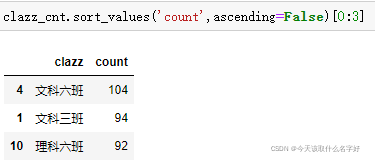
關聯操作join()
現在我再次讀取一張score表,給列加上索引, 不要讓他我們的第一行資料當成索引 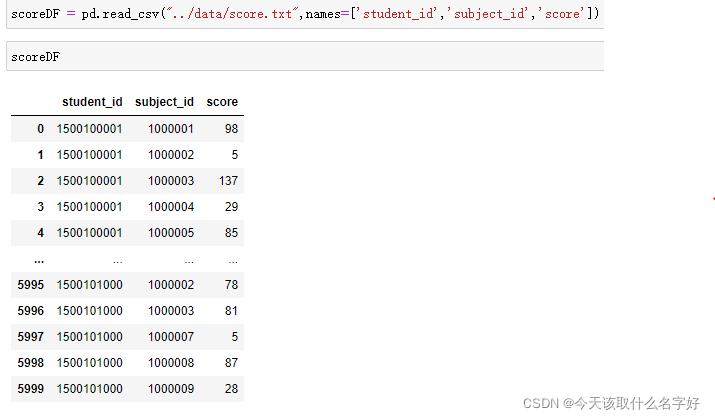
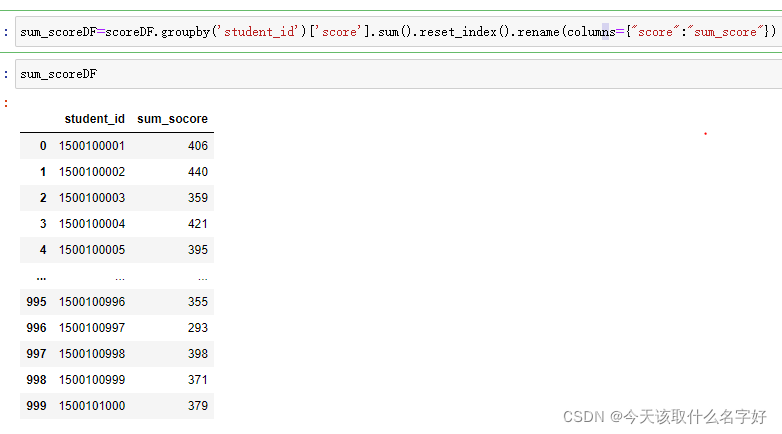
上面的資料里面還包含了每一科目的成績,太多了,我們把總分算出來方便后面關聯,再把score列的索引改變一下變成sum_score
用一個變數sum_scoreDF把上面的表接收一下 ,
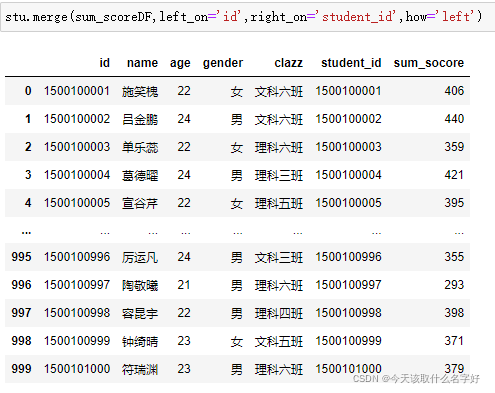
stu 和 sum_score DF現在我關聯這2張表,使用id 和student_id 連接
格式:表1.merge(表2,left_on='表1中的關聯欄位',right_on='表2中的關聯欄位',how='連接方式可以選擇:left,right,inner')
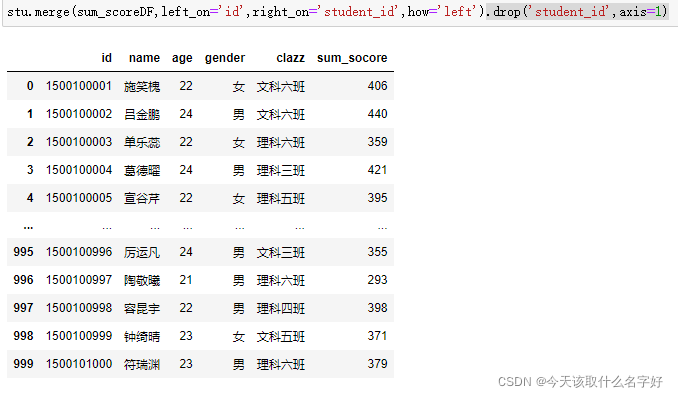
drop() 洗掉一列的資料
上面的表連接后出現了重復欄位,我們可以從上面的表中把列一個一個挑出來,不過那樣太麻煩了,可以直接洗掉一列drop('索引',axsi='0或者1'),0軸和1軸是numpy中使用坐標的時候也用到的,我們可以看成是一個第四象限的坐標,橫向是1軸,縱向是0軸
我怕們指定axis,就是在垂直水平方向切一刀
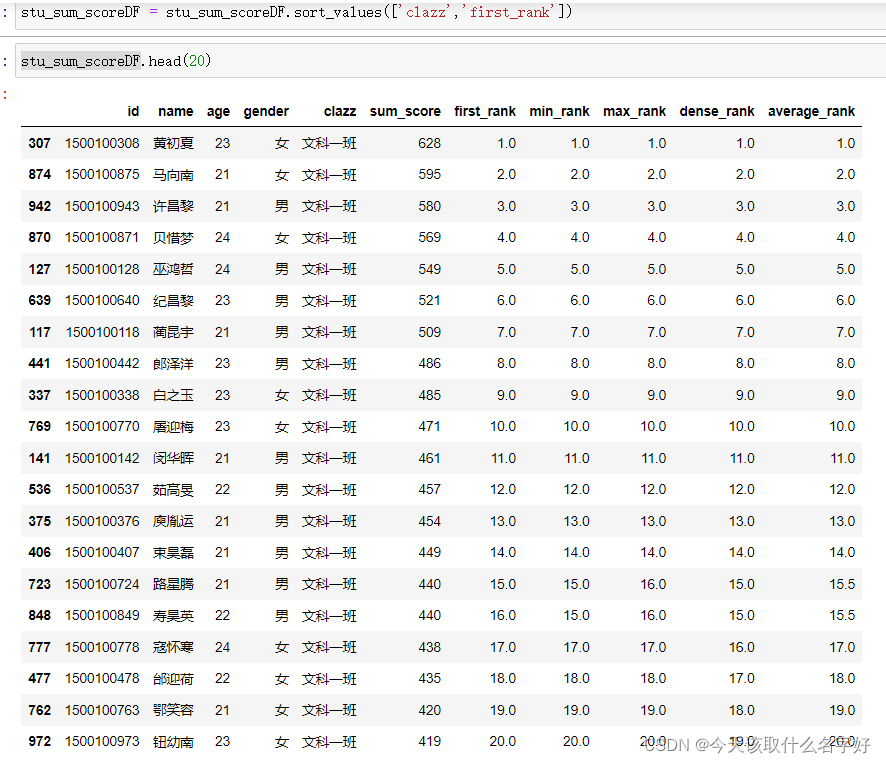
排名rank()
rank方法通常要傳的引數:method可以選擇排名方法(與hive中的一樣)
默認是升序排序,我們求topn問題就需要排序是降序:acending=False,是開啟值從大到小排序
stu_sum_scoreDF['first_rank'] = stu_sum_scoreDF.groupby('clazz')['sum_score'].rank(method='first',ascending=False)
stu_sum_scoreDF['min_rank'] = stu_sum_scoreDF.groupby('clazz')['sum_score'].rank(method='min',ascending=False)
stu_sum_scoreDF['max_rank'] = stu_sum_scoreDF.groupby('clazz')['sum_score'].rank(method='max',ascending=False)
stu_sum_scoreDF['dense_rank'] = stu_sum_scoreDF.groupby('clazz')['sum_score'].rank(method='dense',ascending=False)
stu_sum_scoreDF['average_rank'] = stu_sum_scoreDF.groupby('clazz')['sum_score'].rank(method='average',ascending=False)first:從1開始到最后每有排名重復的
min:排名有重復,如果值相等按照小的寫
max:排名有重復,如果值相等按照大的寫
dense:和min一樣排名有重復,如果值相等按照小的寫
average:排名有重復,如果值相等按照重復位置的排名平均數的寫
還是不太清楚的可以看看這張圖
篩選first_rank<3的,完成分組求topn問題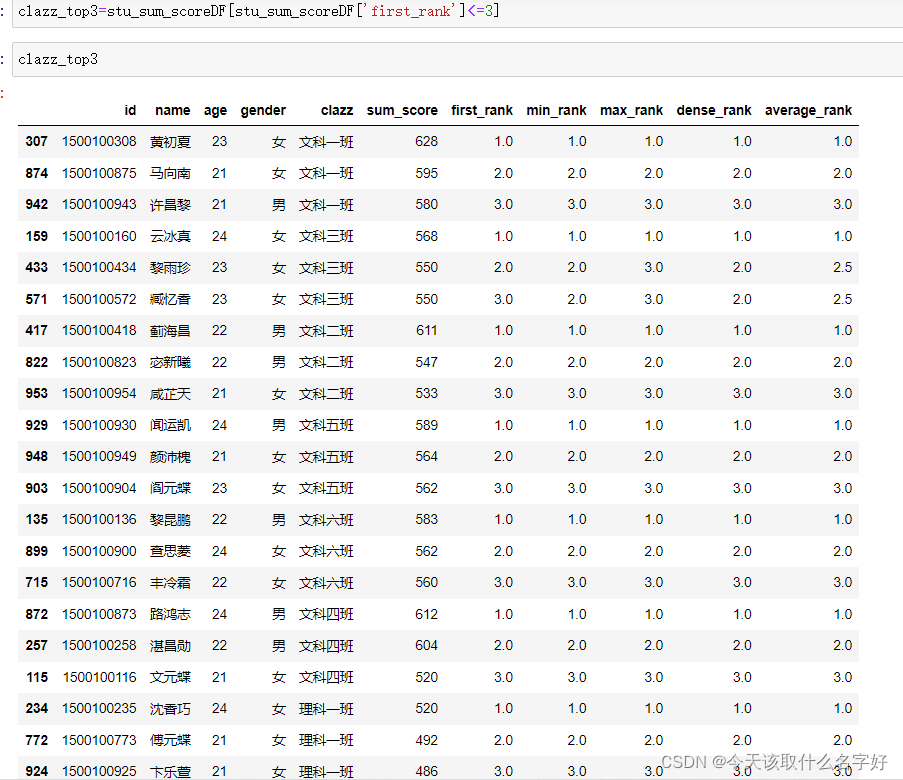
import seaborn as sns
import matplotlib.pyplot as plt
# windows解決中文亂碼
plt.rcParams['font.sans-serif']=['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus']=False # 用來正常顯示負號
plt.figure(figsize=(16,8))#設定畫布的大小
plt.title("班級總分TOP3")#設定標題
sns.barplot(x="clazz", y="sum_score", hue="first_rank",data=clazz_top3)
plt.xlabel("班級") //設定x軸的標簽
plt.ylabel("總成績") //設定y軸的標簽
plt.ylim(400,650) //截取y軸的長度
plt.show() //關閉日志資訊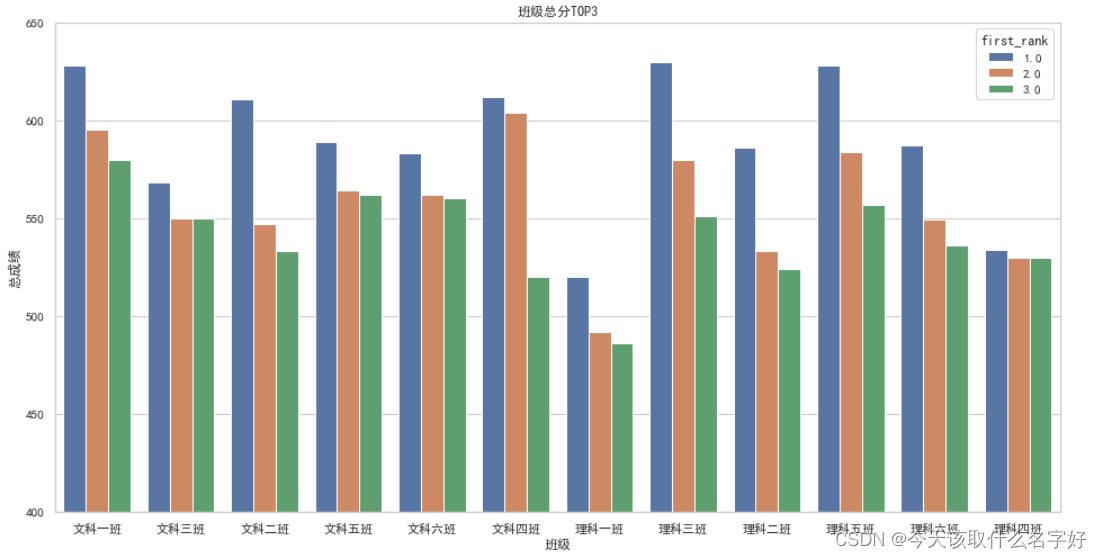
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/389826.html
標籤:區塊鏈