我正在嘗試使用 firebase 作為我的 NoSQL 后端創建一個約會應用程式。但是,由于我是 NoSQL 概念的新手,因此我遇到了幾個問題,其中包括有關檔案大小和查詢的優化。
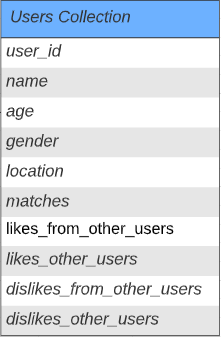
users:
user_id
name
age
gender
location
matches: [user1_id, user2_id, ...]
likes_from_other_users: [user1_id, user2_id, ...]
likes_other_users: [user1_id, user2_id, ...]
dislikes_from_other_users: [user1_id, user2_id, ...]
dislikes_other_users: [user1_id, user2_id, ...]
假設名為UserA 的用戶有很多來自其他用戶的喜歡,因此陣列 likes_from_other_users 的大小將達到超過檔案的最大大小 (1 MB) 的程度。這個例子可以應用于其他陣列。
我應該如何進行?
我正在考慮將這些大陣列提取到新集合中。
在所有喜歡(假設 userA 有 N 個來自其他用戶的喜歡)到userA 的情況下,將有 n 個檔案,其中每個檔案的欄位“到”設定為userA id,“來自”欄位設定為每個特定用戶喜歡用戶A。
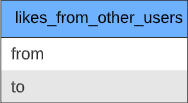
這將解決巨大陣列大小的問題,但可能會增加查詢特定用戶的復雜性。
這是正確的方法嗎?(我必須制作 5 個額外的集合:likes_from_other_users、likes_other_users、dislikes_from_other_users、dislikes_other_users 和matches)并且可能很慢。
此外,matches 集合將包含一對(陣列)用戶,因此要查詢特定用戶的匹配項,我需要檢查此集合中的所有檔案并找到包含我正在查詢的特定用戶的檔案

這是正確的方法嗎?
uj5u.com熱心網友回復:
我正在考慮將這些大陣列提取到新集合中。
這是唯一可擴展的解決方案。陣列根本不可擴展;集合中的單個檔案在 Firestore 中可以無限擴展。這甚至不是“正確”解決方案的問題,它是使用 Firestore 時唯一可擴展的解決方案。
請注意,Firestore 并不總是適合給定應用程式的最佳資料庫。如果您擔心針對給定問題的解決方案的成本或效率,那么 Firestore 可能并不是真正的最佳解決方案。每個資料庫都有其優勢,NoSQL 資料庫通常不擅長表達 SQL 資料庫那樣的復雜關系。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/391905.html