我試圖了解我的 AWS Elasticsearch 垃圾收集時間是否有問題,但我發現的所有與記憶體相關的問題都與記憶體壓力有關,這似乎還不錯。
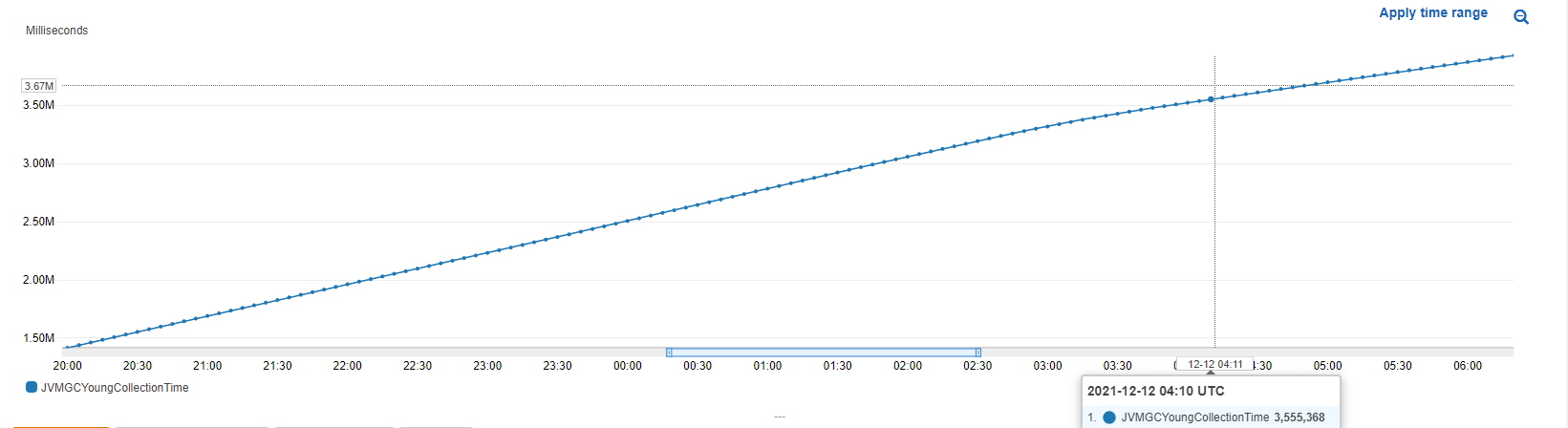
因此,當我在環境上運行負載測驗時,我觀察到所有 GC 收集時間指標不斷上升,例如:
但是在查看記憶體壓力時,我發現我沒有超過 75% 的標記(但接近..),
所以我擔心一旦我添加更多負載或運行更長的測驗,我可能會開始看到會對我的環境產生影響的實際問題。那么,我這里有問題嗎?當我無法進行記憶體轉儲并查看發生了什么時,我應該如何處理上升的 GC 時間?
uj5u.com熱心網友回復:
頂部圖表報告聚合 GC 收集時間,這是GarbageCollectorMXBean 提供的。它繼續增加,因為每個年輕代收藏都增加了它。在底部的圖表中,你可以看到很多年輕代的收集正在發生。
任何網路應用程式(OpenSearch 集群就是這樣)中都需要年輕代集合:您不斷地發出請求(查詢或更新),而這些請求會產生垃圾。
我建議查看主要的收集統計資料。根據我使用 OpenSearch 的經驗,當您執行大量更新(可能是合并索引的結果)時,會發生這種情況。但是,除非您經常更新集群,否則它們應該很少出現。
如果確實遇到記憶體壓力,唯一真正的解決方案是移動到更大的節點大小。由于索引跨節點分片的方式,添加節點可能無濟于事。
uj5u.com熱心網友回復:
我向 AWS 技術支持發送了一個查詢,與任何直觀行為相反,Elasticsearch 中 Young 和 Old Collection 時間和計數的值是累積的。這意味著這個值會不斷增加并且不會下降到值 0,直到有節點洗掉或節點重新啟動
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/393224.html