為什么使用數字表比使用遞回 CTE 即時生成它們要快得多?
在我的機器上,給定一個包含從 1 到 100000 的數字numbers的單列n(主鍵)的表,以下查詢:
select n from numbers;
大約需要 400 毫秒才能完成。
使用遞回 CTE 生成數字 1 到 100000:
with u as (
select 1 as n
union all
select n 1
from u
where n < 100000
)
select n
from u
option(maxrecursion 0);
大約需要 900 毫秒才能完成,均在 SQL Server 2019 上。
我的問題是,為什么第二個選項比第一個選項慢這么多?第一個不是從磁盤獲取結果,因此應該更慢嗎?
不然有什么辦法可以讓CTE跑得更快?因為在我看來,它是比在資料庫中存盤數字串列更優雅的解決方案。
uj5u.com熱心網友回復:
第一個不是從磁盤獲取結果,因此應該更慢嗎?
100,000 個整數將適合大約 161 個資料頁(假設沒有使用壓縮)——每行將是 11 個位元組,并在槽陣列中消耗 2 個位元組。
當您運行測驗時,資料可能已經在快取中。即使沒有在快取中,也很可能幾乎所有頁面在需要它們之前已經通過預讀機制讀入快取,因此 IO 等待時間最少,并且它再次只是一個 CPU 系結操作。(您可以使用SET STATISTICS IO ON查看實際需要多少物理讀取和預讀讀取)
從快取中的資料頁讀取行當然是 SQL Server 擅長的。從執行計劃的角度來看,根本沒有復雜性。正確的行可以從索引查找運算子(理想情況下或掃描運算子否則)回傳,并直接輸出到客戶端,無需額外的運算子。
遞回 CTE 功能是一種通用方法,它始終使用基本相同的執行計劃。來自錨點部分的行被添加到堆疊線軸,然后從線軸彈出(洗掉)以饋入嵌套回圈運算子,該運算子計算其內部子樹上的遞回部分并將值向上傳遞到執行計劃樹被添加到堆疊假脫機(用于進一步遞回)并回傳給客戶端。
所有這些執行計劃操作都需要時間。我10,000,000在我的本地機器上嘗試了數字。整個查詢持續時間為 2m 6s(其中 38 秒花費在 9,999,999 次PAGELATCH_SH等待tempdbspool 上)
這些閂鎖等待的原因在此處的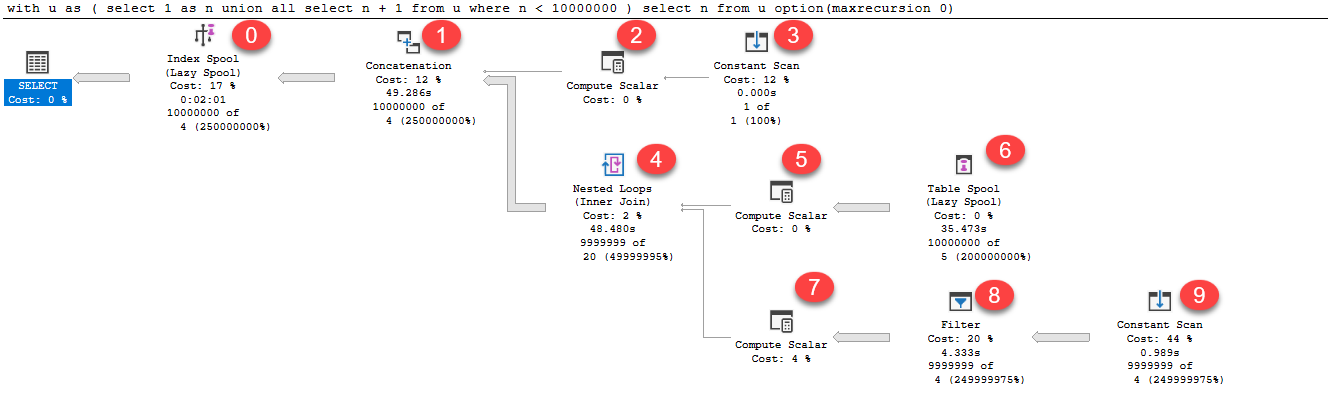
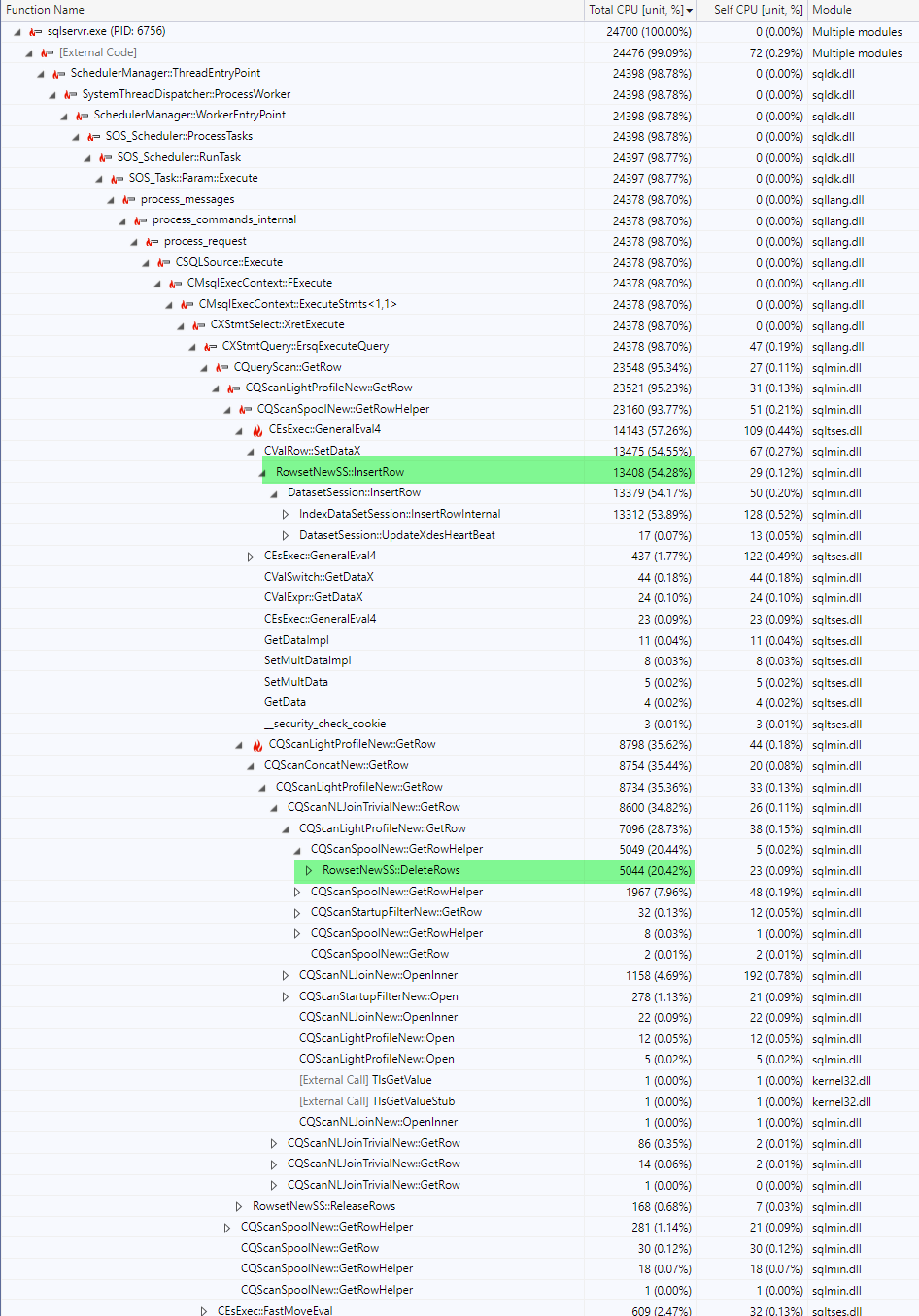
Certainly it would be possible to provide a function like the Postgres generate_series one that is entirely CPU based and just dedicated to the task of supplying incrementing values and this could outperform the disc based table approach but as yet no such dedicated function has been implemented in the product. Until such time the current "state of the art" approach to produce numbers without a numbers table is probably the one mentioned first in this page.
uj5u.com熱心網友回復:
遞回 CTE 是一項 CPU 開銷很大的操作,因為 SQL Server 在到達行上“回圈”。物化數字表或基于集合的 CTE 將執行得更快。請注意SET STATISTICS TIME ON我的作業站 (YMMV) 上報告的 CPU 和運行時間。
數字表:
SELECT * FROM dbo.numbers;
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 231 ms.
遞回 CTE:
with u as (
select 1 as n
union all
select n 1
from u
where n < 100000
)
select n
from u
option(maxrecursion 0);
SQL Server Execution Times:
CPU time = 375 ms, elapsed time = 529 ms.
基于集合的 CTE:
WITH
t10 AS (SELECT n FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t(n))
,t1k AS (SELECT 0 AS n FROM t10 AS a CROSS JOIN t10 AS b CROSS JOIN t10 AS c)
,t100k AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 0)) AS n FROM t1k AS a CROSS JOIN t10 AS b CROSS JOIN t10 AS c)
SELECT n
FROM t100k;
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 223 ms.
數字表的一個優點是可以利用唯一索引來優化某些查詢,盡管這里不適用。
uj5u.com熱心網友回復:
當您將一列宣告為主鍵時,SQL Server 會創建一個聚集索引,這意味著如果您使用主鍵查詢該表,SQL Server 查詢優化器就會準確地知道該列的位置。換句話說,這個查詢盡可能高效,CPU 時間和邏輯讀取最少。要查看這兩種方法之間差異的詳細視圖,請啟用執行計劃 WITHCtrl m運行查詢并比較兩個執行計劃。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/395681.html
標籤:sql sql-server 查询语句
下一篇:存盤程序沒有設定變數