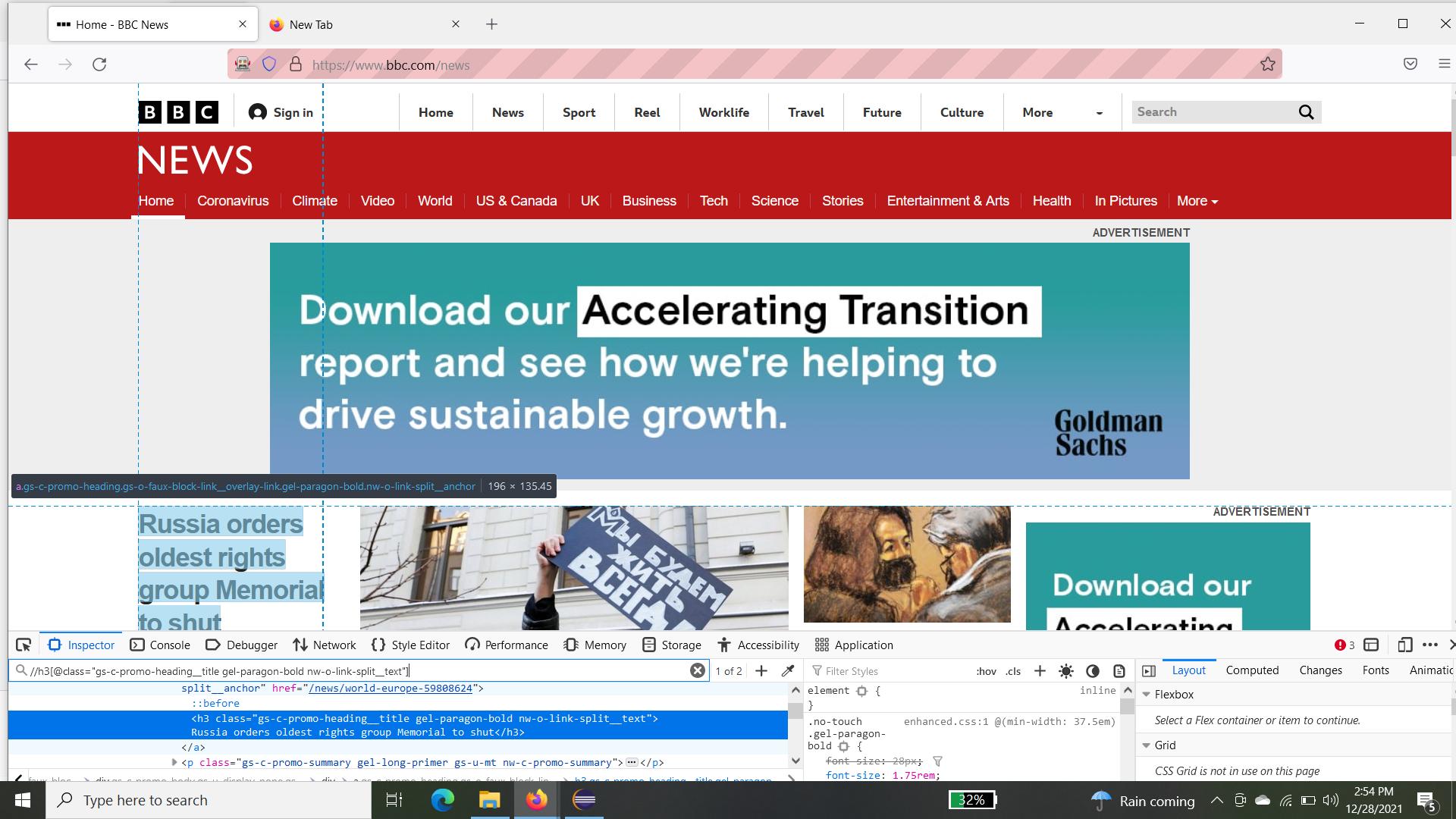
我正在嘗試導航到每個鏈接并在頁面上獲取他們的第一個新聞。但無法為所有頁面的標題資訊獲取唯一的 xpath
請參閱附圖,它顯示了 2 個元素。我怎樣才能使它成為唯一的,只獲取標題/標題新聞。
uj5u.com熱心網友回復:
您可以使用父元素的第一個子元素僅選擇第一個元素,然后指向子元素,例如:
//div/div[1]/div/a/h3[@]
[1] 等于 :first-child
uj5u.com熱心網友回復:
要檢索的第一條新聞的標題,你需要引起WebDriverWait的visibilityOfElementLocated(),你可以使用以下的定位策略:
Java和xpath以及
getText():System.out.println(new WebDriverWait(driver, 20).until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//div[contains(@class, 'gs-u-display-inline-block@m')]//h3[@class='gs-c-promo-heading__title gel-paragon-bold nw-o-link-split__text']"))).getText());Python和css_selector和text屬性:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div[class*='gs-u-display-inline-block@m'] h3.gs-c-promo-heading__title.gel-paragon-bold.nw-o-link-split__text"))).text)控制臺輸出:
Russia orders oldest rights group Memorial to shut注意:對于Python客戶端,您必須添加以下匯入:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
uj5u.com熱心網友回復:
該頁面上有許多標題,并且它們正在更改。我的意思是一些新聞即將從該頁面中洗掉。
如果您想獲取所有新聞標題文本,您可以獲取所有標題元素,然后遍歷它們并提取它們的文本。
像這樣的東西:
List<WebElement> headers = driver.findElements(By.xpath("//h3[@class='gs-c-promo-heading__title gel-pica-bold nw-o-link-split__text']"));
for (WebElement header : headers){
((JavascriptExecutor) driver).executeScript("arguments[0].scrollIntoView(true);", header);
System.out.println(header.getText());
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/397005.html