Cassandra 論文總結
- 前言
- 一、Overview
- 二、Data Model
- 二、Partitioning
- 三、Replication
- 四、Consistency
- 五、Persistence
- 參考
前言
??前段時間寫了一篇關于Dynamo 的論文筆記,最近兩天看了看何其不少類似的Cassandra 論文,在此做個總結,希望可以便人便己,
ps:因為這篇論文內容比較少,而且很多知識和Dynamo略有重復,所以大體的框架將不再采用和論文條目一樣的格式,而是采用總結對比的形式,闡述重點內容,
一、Overview

??從某種程度上來說,Cassandra是dynamo的一個開源實作,聽說是從aws跳槽到facebook的兩名工程師做的,所以其設計和實作上和dynamo有很多類似的地方,
??總的來說,cassandra是一個松散的分布式存盤系統,其設計的目標在于實作Inbox Search ,旨在提供一個scaled storage system以解決快速增長的資料問題,也就是可以處理高吞吐量,滿足可拓展性以及高可用性,
二、Data Model
??對于dynamo來說,其是一個KV資料庫,資料模型比較簡單,采用的是key-value pair store,對于cassandra來說,雖然從某種程度上來說,它也是一個kv資料庫,但是其資料模型是有點類似bigtable的column oriented key-value store, 它們的存盤結構如下圖一和下圖二所示,
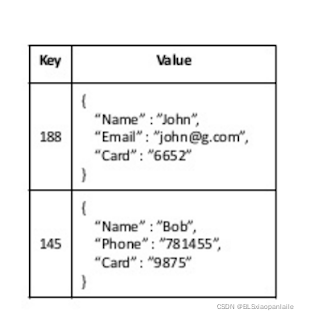
圖一 dynamo的資料模型示意圖
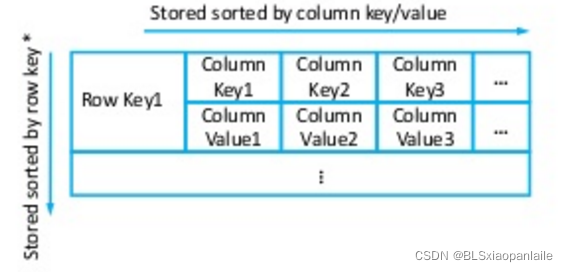
圖二 cassandra的資料模型示意圖
?
??從上面的示意圖中可以看出來,dynamo是普通的kv存盤,其對應的映射是key->value, 而cassandra 算是一個半結構化的kv存盤,其對應的映射是(key+columnName)->column value, 雖然說cassandra有結構化的特性,但是其schema并不是向結構化sql資料庫那樣提前定義好的,而是可以隨時添加變動(nosql 的特性也可以從這里看出來),
??抽象的看,可以把cassandra的資料模型定義如下:
??Map<RowKey, SortedMap<ColumnKey, ColumnValue>>
??cassandra的這種資料模型和時序資料庫influxDB是很相像的,后者的資料模型是
??Map<Key,SortedMap<timestamp,value>>,
??和cassandra 的抽象定義是不是很像? 只不過后者的Key其實還包括serieskey+fieldKey,看起來更復雜些,
二、Partitioning
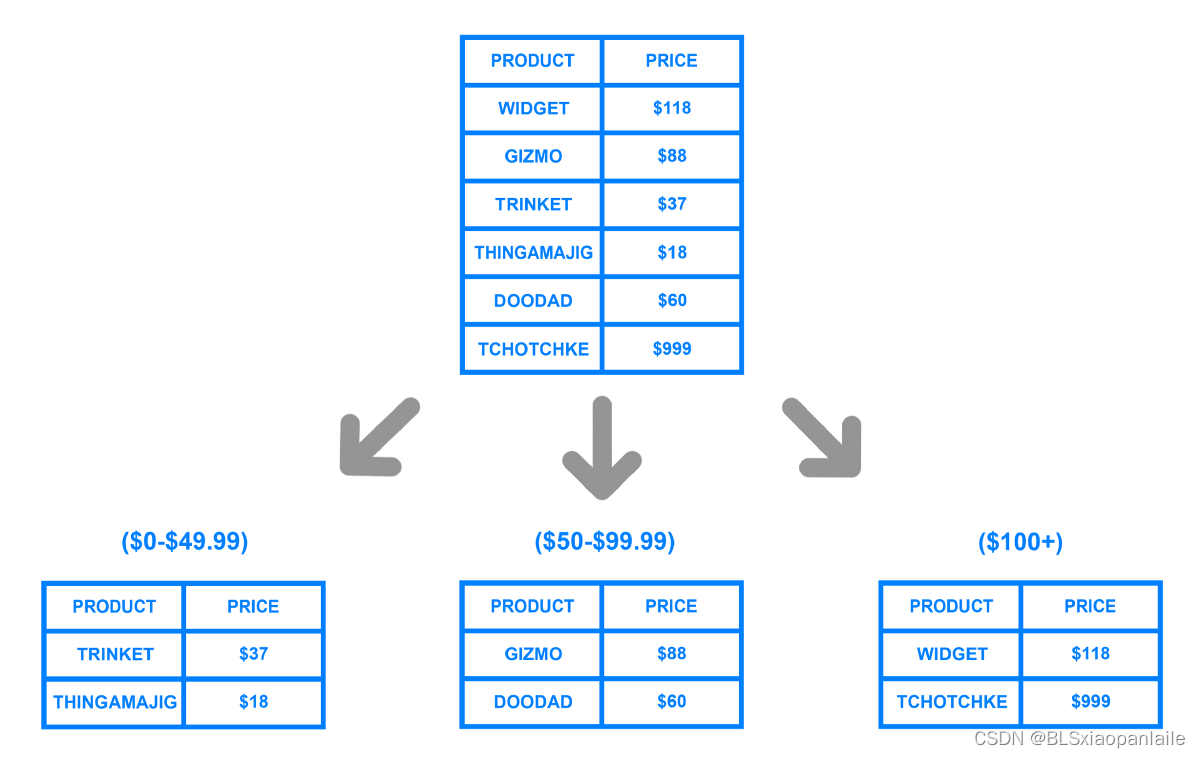
??為了達到線性擴展的目的,cassandra也采用了一致性hash的partition方式,關于一致性hash在dynamo中有過介紹,這里就不贅述了,不過對于一致性hash的固有缺點,即可能會存在非均勻的資料分布問題(non-uniform data and load distribution)和未充分考慮每個node的性能情況,dynamo采用的是一個node分配多個虛擬節點的方式,而cassandra采用的是分析負載情況,讓node在hash ring 上所對應的key 進行移動,以達到均衡負載的效果,
??對于dynamo采用的虛擬節點的改進方式,從某種程度上來說,變動一個新的結點后又會影響到多個相鄰的結點了(因為一個實際的node對應多個虛擬節點);而且根據【1】中的說法,如果一個實際結點的資料量比較大(TB),那么在進行資料遷移的時候,會對資源(disk IO,network io,cpu等)有很大的開銷花費,(需要遷移的資料量比較大,都會有很大的開銷吧?)
??對于cassandra采用的改進方式,如果節點在ring上的移動將很頻繁,【1】中也說了其存而控制混亂,手動維護繁重的問題,
?
三、Replication
??為了達到high availability 和 durability的目的,cassandra采用了多副本的方式,系統給客戶端提供了三種副本策略:
(1) Rack Unaware,
(2) Rack Aware ,
(3) Datacenter Aware,
??其中第一種直接在key 所對應的coordinator中順延選取N-1個node,后面兩種要根據不同node結點所對應的的位置進行選擇,如副本需在不同機架、不同的資料中心等,
?
??對于cassandra來說,不同node之間元資料(每個node負責的range 范圍,node屬性等資訊)是通過一個zookeeper結點來控制的, (對于dynamo來說,它是通過gossip協議來進行資訊互通)那這個ZK算不算是中心化的一個結點呢,但是很多文章中又說到cassandra是一個非中心化的系統,這是不是就有點小矛盾了?
??是這樣,所謂中心化的副本控制協議指的是由一個中心節點來協同控制副本資料的更新、進行并發控制,協調副本間的一致性, 而這里的zk只是存盤了一部分的元資料,從某種程度上來說相當于各個資料結點的網路共享存盤,但是其并不負責維護資料的更新和協調副本間的一致性(副本間的一致性是通過gossip演算法來實作的),所以確切的說不應該算作中心化的結點,
?
四、Consistency

??一旦涉及到多副本replication機制,就免不了其副本間的一致性問題,對于副本間的一致性來說,cassandra來說使用的是和dynamo類似,支持用戶總是可寫,而解決一致性沖突留給了讀操作,
??它們使用了可調節的quorum機制,其基本思路是對于quorum中的N,W,R , 一般要求需要保證W+R>N. 如果W設定的大些,那么說明在寫時需要多花功夫; 如果R設定的大些,說明在讀時需要多讀幾個replication, 前者偏向更強的一致性,后者更強調寫性能, 如下圖三所示,
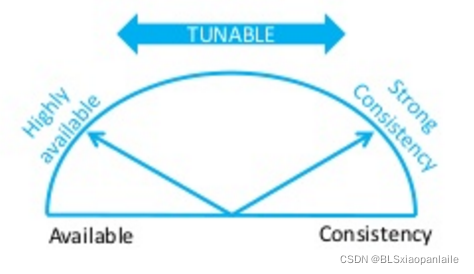
圖三 quorum調節示意圖
?
??文章【1】中又指明了cassandra系統中采用這種一致性的一些問題,這里就不多探究了,感興趣的可以研究研究,
五、Persistence
??對于anssandra系統來說,其資料的持久化本質上采用的是LSM-Tree機制,以犧牲一部分的讀性能,來大大提高寫性能,在我看來其最基本的原理就是把大量的隨機寫變成順序寫,詳細的細節網上有很多,這里就不贅述了,
下面兩張圖說明了讀寫LSM的讀寫流程和其示意圖,

圖四 LSM讀寫流程
?
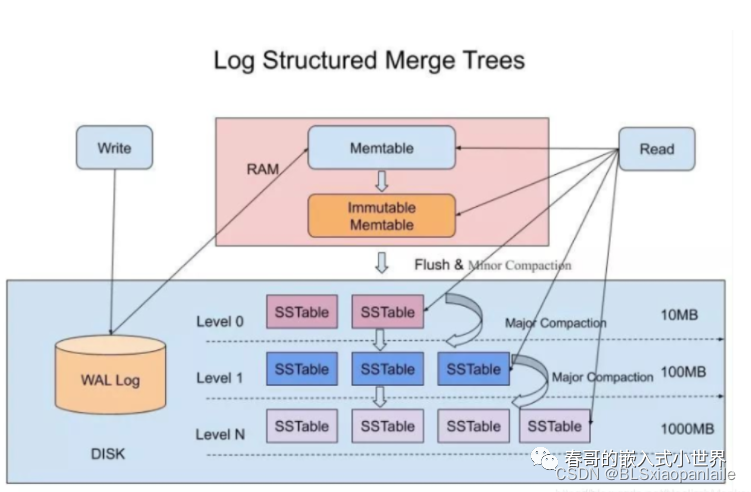
圖五 LSM示意圖
?
參考
【1】、Cassandra VS Dynamo(擴展篇)
【2】、深入研究Cassandra后 重讀Dynamo Paper (Document Transcript)
【3】、LSM學習分享——LSM讀寫流程
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/401716.html
標籤:區塊鏈