我對編碼很陌生,剛開始做一些 R 圖形,現在我對我的資料分析有點迷失了,需要一些光!我正在訓練一些分析,我得到了一個非常長的資料集,包含 19 個國家 x 12 個月,每個月都有利潤。有點像這樣:
Country Month Profit
Brazil Jan 50
Brazil fev 80
Brazil mar 15
Austria Jan 35
Austria fev 80
Austria mar 47
France Jan 21
France fev 66
France mar 15
我正在考慮制作一張圖表來顯示全年的利潤,并為每個國家制作另一張圖表,這樣我就可以看到排名最高和排名最低的兩個國家,但我有點迷失了如何做到這一點?或者有沒有更好的方法來總結這個串列?
uj5u.com熱心網友回復:
也許這樣開始:
library(tidyverse)
u <- data.table::fread('Country Month Profit
Brazil Jan 50
Brazil fev 80
Brazil mar 15
Austria Jan 35
Austria fev 80
Austria mar 47
France Jan 21
France fev 66
France mar 15') %>% as_tibble()
u$Month <- factor(u$Month, levels = c('Jan', 'fev', 'mar'))
ggplot()
geom_line(data = u, aes(x = Month, y = Profit, color = Country, group = Country))
最好有一個像 1:12 這樣的真實月份列,而不必重構級別,然后您可以使用lubridate::month()該列來標記該列。
例如 lubridate::month(1L, label = TRUE, abbr = TRUE)
> lubridate::month(1L, label = TRUE, abbr = TRUE)
[1] jan
Levels: jan < fév < mar < avr < mai < jui < jul < ao? < sep < oct < nov < déc
uj5u.com熱心網友回復:
你可以試試這樣的。fct_*()函式來自forcats包,population來自tidyr. 這兩個都在tidyverse. 我希望它能給你一些想法
library(tidyverse)
# fuller reprex don't worry about this part
df <-
tidyr::population |>
filter(year >= 2010) |>
transmute(
country,
year,
profit = (population / 1e6 * rnorm(1))
) |>
filter(
fct_lump(country, w = profit, n = 19) != "Other"
)
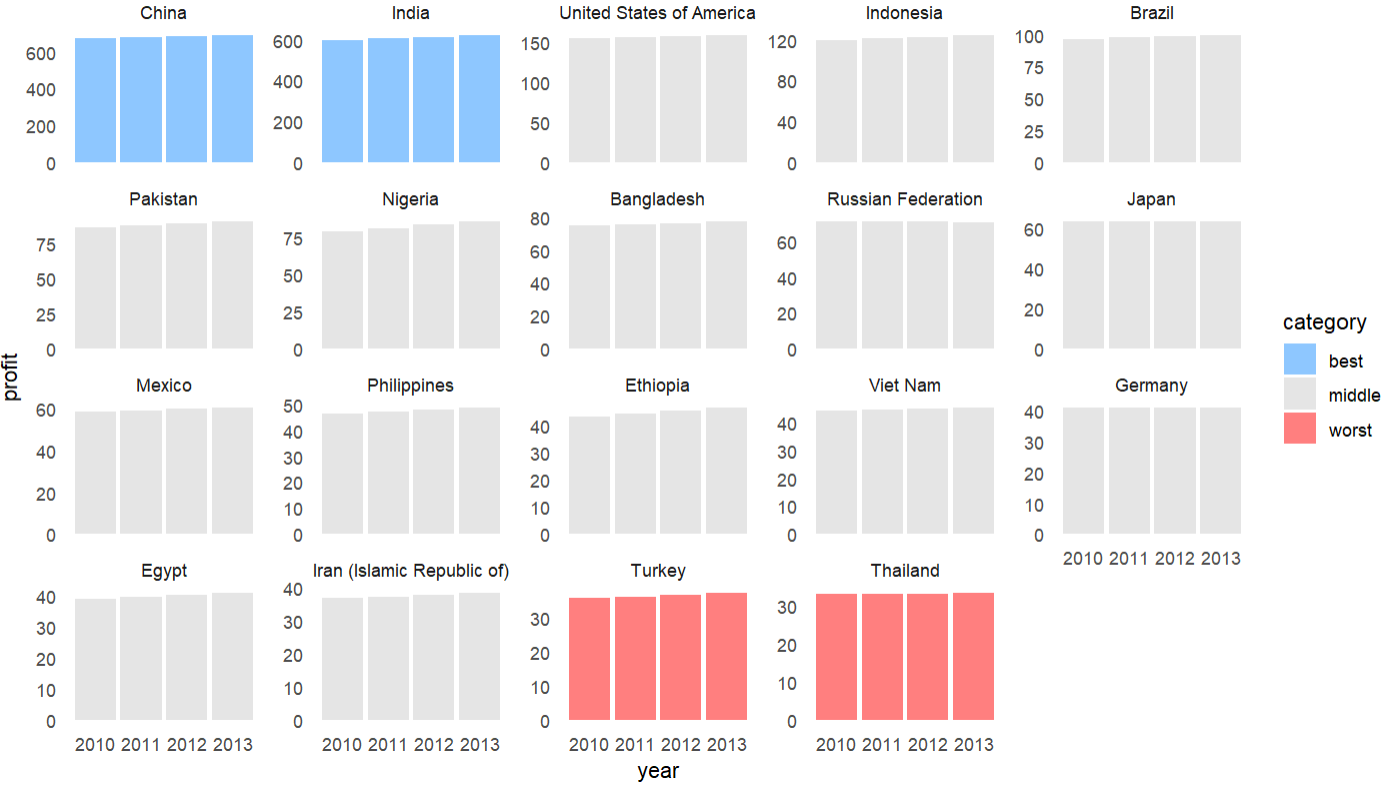
# how to highlight top and bottom performers
df |>
mutate(
country = fct_reorder(country, profit, sum, .desc = TRUE),
rank = as.integer(country),
color = case_when( # these order best in the legend if they are alphabetical or a factor
rank %in% 1:2 ~ "best",
rank %in% 18:19 ~ "worst",
TRUE ~ "middle"
)
) |>
ggplot(aes(year, profit, group = country))
geom_col(aes(fill = color), alpha = 0.5)
scale_size(range = c(0.5, 1))
facet_wrap(~country, scales = "free_y") # you could drop scales
scale_fill_manual(values = c("dodgerblue", "grey80", "red"))
theme_minimal()
theme(panel.grid = element_blank())
uj5u.com熱心網友回復:
我會做這樣的事情:
############ Libraries
library(ggplot2)
############ These lines are just to replicate the structure of your dataframe
df <- data.frame(Country=character(),
Month=character(),
Profit=integer(),
stringsAsFactors=FALSE)
for(one.country in LETTERS){
for(one.month in c("jan","feb","mar","apr","may","june",
"july","aug","sept","oct","nov","dec")){
add <- data.frame(Country=c(one.country),
Month=c(one.month),
Profit=c(sample(0:100,1)),
stringsAsFactors=FALSE)
df <- rbind(df,add)
}
}
############ If you keep months as characters you need to set the variable as factor and
# define the specific order (else they'll be ordered alphabetically in the plot)
df$Month <- factor(df$Month,
levels=c("jan","feb","mar","apr","may","june",
"july","aug","sept","oct","nov","dec"))
show.this.country <- "A" # you can use this variable to switch from
# one country to the other to explore them
ggplot(df[df$Country==show.this.country,])
geom_col(aes(x=Month,y=Profit),colour="steelblue4",fill="steelblue2")
labs(title = paste0("country ",show.this.country))
theme(plot.margin = unit(c(0.5, 0, 1, 1), "cm"), # theme variables are not needed, but
plot.title = element_text(hjust = 0.5,vjust = 2), # they make it look cleaner in my view
axis.title.x = element_text(vjust=-2),
axis.title.y = element_text(vjust=7))
# or loop through if you want to print them all
for(show.this.country in levels(as.factor(df$Country))){
# (but in that case remember to add print(), otherwise they won't show)
print(
ggplot(df[df$Country==show.this.country,])
geom_col(aes(x=Month,y=Profit),colour="steelblue4",fill="steelblue2")
labs(title = paste0("country ",show.this.country))
theme(plot.margin = unit(c(0.5, 0, 1, 1), "cm"),
plot.title = element_text(hjust = 0.5,vjust = 2),
axis.title.x = element_text(vjust=-2),
axis.title.y = element_text(vjust=7))
)
}
然后是國家之間的比較:
# You can rearrange a bit to have the totals per country on a separate dataframe
df2 <- aggregate(x = df$Profit,
by = list(df$Country),
FUN = sum)
colnames(df2) <- c("Country","Total")
# these will return the lines in this dataframe with
# "n.extreme" number of highest and lowest values:
n.extremes <- 3
highest <- order(df2$Total, decreasing=TRUE)[1:n.extremes]
lowest <- order(df2$Total, decreasing=FALSE)[1:n.extremes]
# this is one way to show the 3 best and 3 worst performers
ggplot(df[df$Country%in%df2$Country[c(highest,lowest)],])
geom_col(aes(x=Month,y=Profit,fill=Country),position = "dodge")
labs(title = paste0("best and worst performers"))
theme(plot.margin = unit(c(0.5, 0, 1, 1), "cm"),
plot.title = element_text(hjust = 0.5,vjust = 2),
axis.title.x = element_text(vjust=-2),
axis.title.y = element_text(vjust=7))
scale_fill_brewer(palette="Spectral")
# (but ggplot provides many more, so have fun exploring!)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/420120.html
標籤:
上一篇:使用滑塊回圈通過函式生成的圖