我對某種 mean() 計算有疑問。我使用具有兩個識別符號“ID”和“年份”的面板資料集(使用 plm pkg)
我想計算變數“y”的分組平均值,但省略計算的第一年輸入,然后只填寫用于計算它的年份的計算平均值。換句話說,我想在這個變數的每個 ID 的第一個條目中都有 NA 。
面板資料是不平衡的,所以人們在不同的時間點來來去去。有些人從頭到尾都留著,有些人我只有三三年的資料。
library(tidyverse)
library(plm)
ID <- c("a","a","a","a","a","b","b","b","b","c","c","c")
y <- c(9,2,5,3,3,9,1,2,3,9,2,5)
year<- c(2001,2002,2003,2004,2005,2001,2002,2003,2004,2002,2003,2004)
dt <- data.frame(ID,y,year)
dt <- pdata.frame(dt, index = c("ID","year"))
我首先嘗試了一個過濾器,如下所示:
dt <- dt %>% group_by(ID) %>%
filter(year %in% first(year) 1:last(year)) %>%
mutate(mean.y = mean(y))
但這不起作用,說實話,我并不感到驚訝,但我希望你知道我想要實作的目標。最終結果應如下所示:
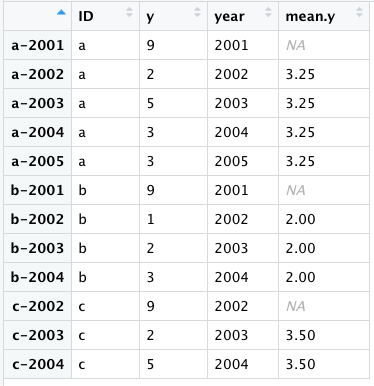
查看“a-2001”的變數 y = 9 的第一個條目是如何被省略的,這樣它不會影響單個 a 的其他 y 條目的平均值 (2 5 3 3)/4
我希望你們能理解它。我將非常感謝任何幫助。再見
uj5u.com熱心網友回復:
這是一個dplyr解決方案。您可以計算除第一個值之外的所有值的平均值,然后使用is.na<-函式分配mean.yas的第一個元素NA。
library(dplyr)
dt %>% group_by(ID) %>% mutate(mean.y = mean(y[-1L]), mean.y = `is.na<-`(mean.y, 1L))
輸出
# A tibble: 12 x 4
# Groups: ID [3]
ID y year mean.y
<chr> <dbl> <dbl> <dbl>
1 a 9 2001 NA
2 a 2 2002 3.25
3 a 5 2003 3.25
4 a 3 2004 3.25
5 a 3 2005 3.25
6 b 9 2001 NA
7 b 1 2002 2
8 b 2 2003 2
9 b 3 2004 2
10 c 9 2002 NA
11 c 2 2003 3.5
12 c 5 2004 3.5
更緊湊,
dt %>% group_by(ID) %>% mutate(mean.y = mean(y[-1L])[n():1 %/% n() 1L])
uj5u.com熱心網友回復:
我們可以使用ifelseinside mutate。它的代碼更多,但我認為它非常易讀且易于理解發生了什么。
library(tidyverse)
library(plm)
dt %>%
group_by(ID) %>%
mutate(mean.y = ifelse(year == first(year),
NA,
mean(y[year != first(year)], na.rm = TRUE)))
#> # A tibble: 12 x 4
#> # Groups: ID [3]
#> ID y year mean.y
#> <fct> <dbl> <fct> <dbl>
#> 1 a 9 2001 NA
#> 2 a 2 2002 3.25
#> 3 a 5 2003 3.25
#> 4 a 3 2004 3.25
#> 5 a 3 2005 3.25
#> 6 b 9 2001 NA
#> 7 b 1 2002 2
#> 8 b 2 2003 2
#> 9 b 3 2004 2
#> 10 c 9 2002 NA
#> 11 c 2 2003 3.5
#> 12 c 5 2004 3.5
由reprex 包(v0.3.0)于 2022-01-23 創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/420150.html
標籤:
上一篇:R中的移位矩陣元素