我想獲得值高于閾值的每個間隔的平均值。顯然,我可以做一個回圈,看看下一個值是否低于閾值等,但我希望有一種更簡單的方法。您是否有類似于掩蔽之類的想法,但包括“間隔”問題?
下面是2張帶有原始資料和我想要獲得的圖片。
前:
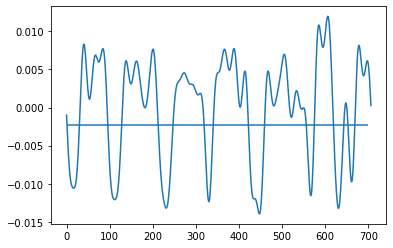
后:
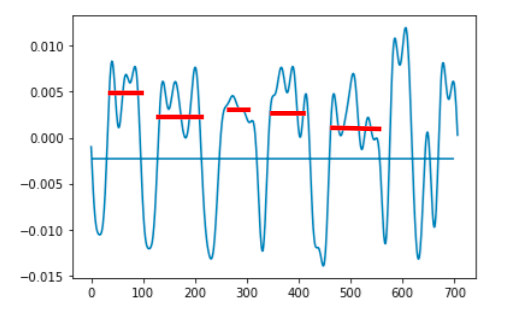
我最初的想法是回圈遍歷我的陣列,但是由于我想這樣做大約 10.000 次或更多,我想它變得非常耗時。
有沒有辦法擺脫for回圈?
transformed是一個 numpy 陣列。
plt.figure()
plt.plot(transformed)
thresh=np.percentile(transformed,30)
plt.hlines(np.percentile(transformed,30),0,700)
transformed_copy=transformed
transformed_mask=[True if x>thresh else False for x in transformed_copy]
mean_arr=[]
for k in range(0,len(transformed)):
if transformed_mask[k]==False:
mean_all=np.mean(transformed_copy[mean_arr])
for el in mean_arr:
transformed_copy[el]=mean_all
mean_arr=[]
if transformed_mask[k]==True:
mean_arr.append(k)
plt.plot(transformed_copy)
回圈后輸出:
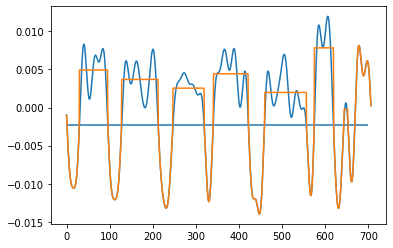
uj5u.com熱心網友回復:
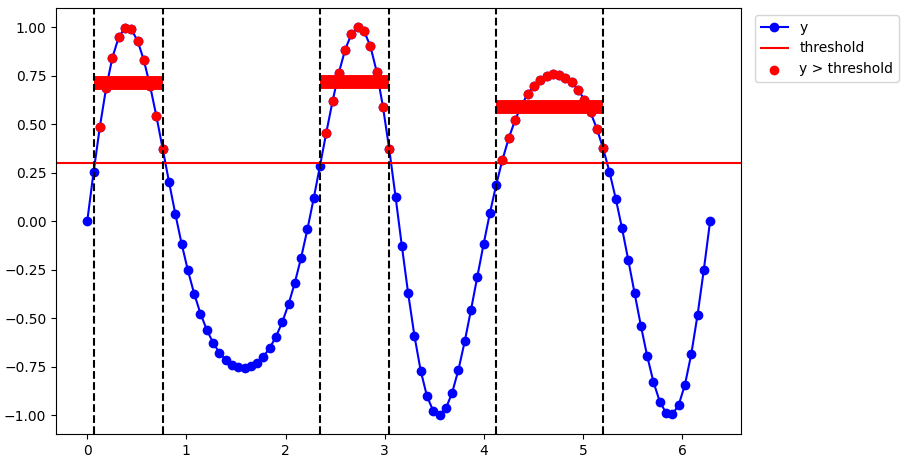
我在這里使用的技巧是計算掩碼中的突然差異,這意味著我們從一個連續的部分切換到另一個。然后我們得到這些部分開始和結束的索引,并計算它們內部的平均值。
# Imports.
import matplotlib.pyplot as plt
import numpy as np
# Create data.
x = np.linspace(0, 2*np.pi, 100)
y = np.sin(np.sin(x)*4)
threshold = 0.30
mask = y > threshold
# Plot the raw data, threshold, and show where the data is above the threshold.
fig, ax = plt.subplots()
ax.plot(x, y, color="blue", label="y", marker="o", zorder=0)
ax.scatter(x[mask], y[mask], color="red", label="y > threshold", zorder=1)
ax.axhline(threshold, color="red", label="threshold")
ax.legend(loc="upper left", bbox_to_anchor=(1.01, 1))
# Detect the different segments.
diff = np.diff(mask) # Where the mask starts and ends.
jumps = np.where(diff)[0] # Indices of where the mask starts and ends.
for jump in jumps:
ax.axvline(x[jump], linestyle="--", color="black")
# Calculate the mean inside each segment.
for n1, n2 in zip(jumps[:-1:2], jumps[1::2]):
xn = x[n1:n2]
yn = y[n1:n2]
mean_in_section_n = np.mean(yn)
ax.hlines(mean_in_section_n, xn[0], xn[-1], color="red", lw=10)
fig.show()
With a bit more time, we could imagine a function that encases all this logic and has this signature: f(data, mask) -> data1, data2, ... with an element returned for each contiguous section.
def data_where_mask_is_contiguous(data:np.array, mask:np.array) -> list:
sections = []
diff = np.diff(mask) # Where the mask starts and ends.
jumps = np.where(diff)[0] # Indices of where the mask starts and ends.
for n1, n2 in zip(jumps[:-1:2], jumps[1::2]):
sections.append(data[n1:n2])
return sections
With this, you can get the mean in each section very easily:
print([np.mean(yn) for yn in data_where_mask_is_contiguous(y, mask)])
>>> [0.745226, 0.747790, 0.599429]
I just noticed it doesn't work when the mask is all true, so I need to add a default case but you get the idea.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/433834.html