我想在現有代碼中添加一段代碼,用于檢查High列值是否大于列的行的其他值Open, Low, Close。我還想檢查Low列的行值是否低于其他列的Open, High, Close行值。因此,在列的值的第 1 行中,該值High不符合此標準,因為Open and Close值高于它,因此它在預期的輸出中。所以本質上這個代碼應該檢查每個High值是否仍然是最大值并且Low每行的值是最低的。
代碼:
import pandas as pd
import numpy as np
import time
import datetime
A =[[1645661520000, 37352.0, 37276.5, 37252.0, 37376.0, 15.56119087],
[1645661580000, 37376.0, 37414.0, 37376.0, 37314.0, 49.38248589],
[1645661640000, 37414.0, 37414.0, 37350.0, 37350.0, 45.70306699],
[1645661700000, 37350.0, 37374.0, 37350.0, 37373.5, 14.4306948],
[1645661760000, 37373.5, 36588.0, 37373.5, 37388.0, 3.59340947],
[1645661820000, 37388.0, 37388.0, 37388.0, 39388.0, 21.45525727]]
column_names = ["Unix","Open", "High","Low", "Close", "Volume"]
df = pd.DataFrame(A, columns=column_names)
df.insert(1,"Date", pd.to_datetime(df["Unix"].to_numpy()/1000,unit='s'))
display(df)
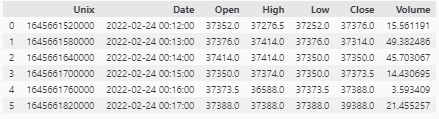
預期輸出:
Rows: 1, 5, 6
#Row 1 is low column is the highest of all than all the other rows
#Row 5 the High column is lower than the other columns
#Row 6 the low column is higher than the other columns
uj5u.com熱心網友回復:
嘗試這個:
# columns of interest
val_cols = ['Open', 'High', 'Low', 'Close']
# This is where High condition is violated
high_cond_violated = df['High'] < df[val_cols].max(axis=1)
# This is where Low condition is violated
low_cond_violated = df['Low'] > df[val_cols].min(axis=1)
# These are the indices where either condition is violated
(df.index[high_cond_violated | low_cond_violated] 1).values.tolist()
輸出:
[1, 2, 5, 6]
您可以分別呼叫它們以查看實際違反了哪一個,例如
# Only High condition violated
(df.index[high_cond_violated] 1).values.tolist()
...
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/433847.html
標籤:python-3.x 熊猫 数据框 麻木的 格式