我有一個如下所示的資料框
df = pd.DataFrame(
{'stud_id' : [101, 101, 101, 101,
101, 101, 101, 101],
'ques_date' : ['13/11/2020', '10/1/2018','11/11/2017', '27/03/2016',
'13/05/2010', '10/11/2008','11/1/2007', '27/02/2006']})
基本上,我想做以下
a) 獲取每個財政季度ques_date
但是,我們公司遵循他們自己的季度定義,如下所示
Q1 - Oct to Dec
Q2 - Jan to Mar
Q3 - Apr to Jun
Q4 - July - Sep
我正在嘗試類似下面的東西
df['act_qtr'] = df['ques_date'].dt.to_period('Q')
df['custom_qtr'] = np.where(df['act_qtr'] == 'Q1','Q2',(df['act_qtr'] == 'Q2', 'Q3',(df['act_qtr'] == 'Q3', 'Q4', (df['act_qtr'] == 'Q4', 'Q1'))))
但這并不優雅和高效。
有沒有pythonic或更好的方法來做到這一點?
我希望我的輸出如下
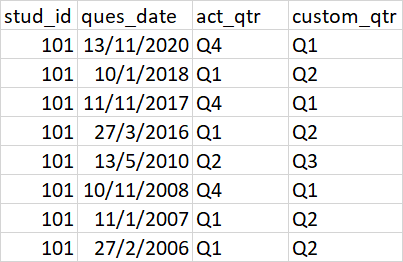
uj5u.com熱心網友回復:
一個想法是為下個季度加 1,然后Series.dt.strftime用于自定義字串Q1, Q2, Q3, Q4:
df['ques_date'] = pd.to_datetime(df['ques_date'], dayfirst=True)
df['act_qtr'] = df['ques_date'].dt.to_period('Q').add(1).dt.strftime('Q%q')
print (df)
stud_id ques_date act_qtr
0 101 2020-11-13 Q1
1 101 2018-01-10 Q2
2 101 2017-11-11 Q1
3 101 2016-03-27 Q2
4 101 2010-05-13 Q3
5 101 2008-11-10 Q1
6 101 2007-01-11 Q2
7 101 2006-02-27 Q2
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/433851.html
標籤:Python 熊猫 数据框 麻木的 熊猫-groupby
上一篇:DataFrame順序洗牌本身