我有一個如下所示的資料框
tdf = pd.DataFrame(
{'Unnamed: 0' : ['Region','Asean','Asean','Asean','Asean','Asean','Asean'],
'Unnamed: 1' : ['Name', 'DEF', 'GHI', 'JKL', 'MNO', 'PQR','STU'],
'2017Q1' : ['target_achieved',2345,5678,7890,1234,6789,5454],
'2017Q1' : ['target_set', 3000,6000,8000,1500,7000,5500],
'2017Q1' : ['score', 86, 55, 90, 65, 90, 87],
'2017Q2' : ['target_achieved',245,578,790,123,689,454],
'2017Q2' : ['target_set', 300,600,800,150,700,500],
'2017Q2' : ['score', 76, 45, 70, 55, 60, 77]})
如您所見,我的列名是重復的。
意思是,有 3 列(2017Q1每列2017Q2)
資料框不允許有重復名稱的列。
我嘗試了以下方法來獲得我的預期輸出
tdf.columns = tdf.iloc[0]v # but this still ignores the column with duplicate names
更新
讀取 excel 檔案后,根據 jezrael 的答案,我得到以下顯示
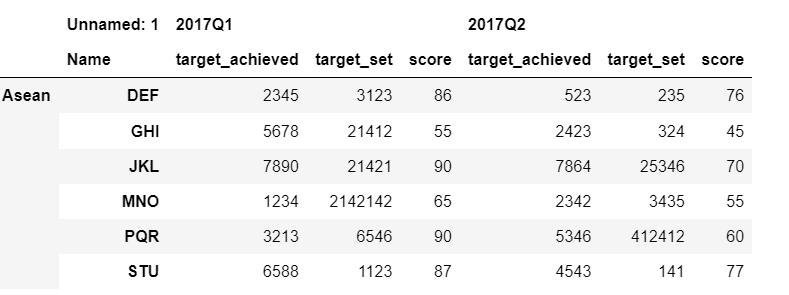
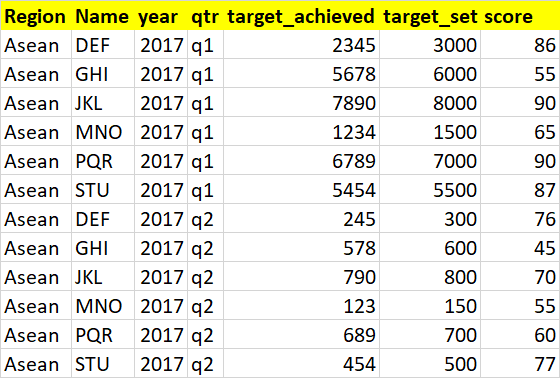
我希望我的輸出如下所示
uj5u.com熱心網友回復:
首先MultiIndex在列和索引中創建:
df = pd.read_excel(file, header=[0,1], index_col=[0,1])
如果不可能,這里是您的示例資料的替代方法 - 將列和第一行資料轉換為MultiIndex in columns,第一列轉換為MultiIndex in index:
tdf = pd.read_excel(file)
tdf.columns = pd.MultiIndex.from_arrays([tdf.columns, tdf.iloc[0]])
df = (tdf.iloc[1:]
.set_index(tdf.columns[:2].tolist())
.rename_axis(index=['Region','Name'], columns=['Year',None]))
print (df.index)
MultiIndex([('Asean', 'DEF'),
('Asean', 'GHI'),
('Asean', 'JKL'),
('Asean', 'MNO'),
('Asean', 'PQR'),
('Asean', 'STU')],
names=['Region', 'Name'])
print (df.columns)
MultiIndex([('2017Q1', 'target_achieved'),
('2017Q1', 'target_set'),
('2017Q1', 'score'),
('2017Q2', 'target_achieved'),
('2017Q2', 'target_set'),
('2017Q2', 'score')],
names=['Year', None])
然后重塑:
df1 = df.stack(0).reset_index()
print (df1)
Region Name Year score target_achieved target_set
0 Asean DEF 2017Q1 86 2345 3000
1 Asean DEF 2017Q2 76 245 300
2 Asean GHI 2017Q1 55 5678 6000
3 Asean GHI 2017Q2 45 578 600
4 Asean JKL 2017Q1 90 7890 8000
5 Asean JKL 2017Q2 70 790 800
6 Asean MNO 2017Q1 65 1234 1500
7 Asean MNO 2017Q2 55 123 150
8 Asean PQR 2017Q1 90 6789 7000
9 Asean PQR 2017Q2 60 689 700
10 Asean STU 2017Q1 87 5454 5500
11 Asean STU 2017Q2 77 454 500
編輯:已編輯問題的解決方案類似:
df = pd.read_excel(file, header=[0,1], index_col=[0,1])
df1 = df.rename_axis(index=['Region','Name'], columns=['Year',None]).stack(0).reset_index()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/433855.html
上一篇:使用100行和53列的資料,我想使用pandas從csv檔案中提取僅包含true和false作為資料的列名
下一篇:np.where未在新列上實作