我想將文本轉換為 csv。輸入檔案包含 10000K 行。輸入檔案示例如下:-
Item=a
Price=10
colour=pink
Item=b
Price=20
colour=blue Pattern=checks
我的輸出應該是這樣的
Item Price Colour Pattern
a 10 pink
b 20 blue checks
如果 1 行中只有一個 '=' 我會得到輸出,如果有超過 1 個像 2/3 '=' 那么我不知道如何申請回圈。有人可以檢查我的 for 回圈部分嗎?我在某個地方出錯了嗎?
import csv
import glob
import os
def dat_to_csv(filename, table_name):
with open(filename, 'r') as reader:
list_of_columns = []
table_values = []
master_table = []
counter = 0
for line in reader:
#stripped_line = line.strip()
if line == "\n":
#copy all elements which have values else paste a null
if (table_values):
#master_table.append(table_values)
master_table.append([])
master_table[counter] = table_values.copy()
counter=counter 1
length = len(table_values)
for element in range(length):
table_values[element] = []
continue
if line == "\n":
continue
extra_stripped_line = ' '.join(line.split())
data = extra_stripped_line.split("=",1)
column_name = data[0].strip()
if "=" in data[1]:
data1 = data[1].split(" ",1)
value = data1[0].strip()
data2 = data1[1].split("=",1)
column_name = data2[0].strip()
value = data2[1].strip()
continue
value = data[1].strip()
if column_name not in list_of_columns:
list_of_columns.append(column_name)
table_values.append([])
index = list_of_columns.index(column_name)
#table_values[index].append(value)
table_values[index] = value
#with open("output\\{}.csv".format(table_name), 'w', newline='') as csvfile:
with open("folderpath\\{}.csv".format(table_name), 'w', newline='') as csvfile:
writer = csv.writer(csvfile, delimiter=',', quotechar='"', quoting=csv.QUOTE_ALL)
writer.writerow(list_of_columns)
#t_table_values = zip(*table_values)
max_elements = len((master_table))
master_table_transp = []
for cntr in range(max_elements):
master_table_transp.append([])
num_objects = len(master_table)
for cntr_obj in range(num_objects):
for cntr_row in range(max_elements):
if (cntr_row<len(master_table[cntr_obj])):
master_table_transp[cntr_row].append(master_table[cntr_obj][cntr_row])
else:
master_table_transp[cntr_row].append([])
t_table_values = zip(*master_table_transp)
for values in t_table_values:
writer.writerow(values)
if __name__ == '__main__':
path = "folderpath"
for filename in glob.glob((os.path.join(path, '*.txt'))):
name_only = os.path.basename(filename).replace(".txt", "")
dat_to_csv(filename, name_only)
我得到的輸出如下:
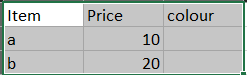
uj5u.com熱心網友回復:
除非我誤解了某些東西,否則它就像這樣簡單:
from pandas import DataFrame
from numpy import nan
master = [dict()]
with open('foo.txt') as foo:
for line in foo:
if (line := line.strip()):
for token in line.split():
k, v = token.split('=')
master[-1][k] = v
elif master[-1]:
master.append(dict())
if not master[-1]:
del master[-1]
if master:
df = DataFrame(master).replace(nan, '', regex=True)
df.to_csv('foo.csv', index=False)
輸出(csv 檔案):
Item,Price,colour,Pattern
a,10,pink,
b,20,blue,checks
uj5u.com熱心網友回復:
有了一些假設,這是可行的。我添加了一些測驗用例。這確實需要所有記錄都適合記憶體,但如果您提前知道所有可能的列名,您可以columns相應地設定并將行寫入生成的行而不是最后的所有行。即使有 10000K (10M) 記錄,除非記錄非常大,可以輕松放入現代系統記憶體中。
輸入.csv
Item=a
Price=10
Item=b
Price=20
colour=blue Pattern=checks
Item=c
Price=5
Item=d Price=25 colour=blue
Item=e colour===FANCY== Price=1/2=$1
測驗.py
from collections import defaultdict
import csv
columns = {}
lines = []
with open('input.txt') as fin:
for line in fin:
if not line.strip(): # write record on blank line
needs_flush = False
lines.append(columns)
# blank all the columns to start next record.
columns = {k:'' for k in columns}
continue
# assume multiple items on a line are separated by a single space
items = line.strip().split(' ')
# assume column name is before first = sign in each item
for column,value in [item.split('=',1) for item in items]:
needs_flush = True
columns[column] = value
# write record on EOF if hasn't been flushed
if needs_flush:
lines.append(columns)
# dump records to CSV
with open('output.csv','w',newline='') as fout:
writer = csv.DictWriter(fout, fieldnames=columns)
writer.writeheader()
writer.writerows(lines)
輸出.csv:
Item,Price,colour,Pattern
a,10,,
b,20,blue,checks
c,5,,
d,25,blue,
e,1/2=$1,==FANCY==,
uj5u.com熱心網友回復:
如果您的資料在欄位之間有換行符:
Item=a Price=10 colour=pink
Item=b
Price=20
colour=blue
Pattern=checks
Item=c
Price=9
Colour=green
Size=small
我也有colourand Colour,你可以在下面的輸出中看到。
這是一個簡單的狀態機,它可以看到以 'Item' 開頭的行,它只是開始將資料決議為一條記錄,直到它看到另一個 Item-line,它將開始一條新記錄;并在檔案末尾清除所有剩余記錄:
import csv
def flush(record, records):
if record != {}:
records.append(record)
field_names = {} # use dict as ordered set to collect all field names as data is parsed
records = []
record = {}
with open('input.txt') as f:
for line in f:
line = line.strip()
if line.startswith('Item'):
flush(record, records) # flush any previous data
record = {} # (re)set for upcoming data
if line == '':
continue
# Line is data, parse it
fields = [x for x in line.split() if x] # default for split is "whitespace", so space or tab (or maybe something else relevant)
kvps = [field.split('=', 1) for field in fields] # 1 in split('=', 1) is for the `===FANCY==` example @MarkTolonen threw at us
try:
kvp_dict = dict(kvps)
except Exception as e:
print(f'error: found KVPs {kvps} in line \'{line}\', but couldn\'t create dict: {e}')
record.update(kvp_dict)
field_names.update(kvp_dict) # pass in keys & vals (it's simpler) even if we only need the keys
# Save last record
flush(record, records)
out_f = open('output.csv', 'w', newline='')
writer = csv.DictWriter(out_f, fieldnames=field_names)
writer.writeheader()
writer.writerows(records)
| Item | Price | colour | Pattern | Colour | Size |
|------|-------|--------|---------|--------|-------|
| a | 10 | pink | | | |
| b | 20 | blue | checks | | |
| c | 9 | | | green | small |
colour/Colour由于大小寫的不同,您可以看到。因此,如果您擔心這樣的差異,則需要在首次獲取鍵值對時添加“規范化步驟”。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/433955.html