如何從以下格式的文本表中決議和提取 4 個重要列?這些是使用 Ruby 包從 PDF 中提取的銀行交易行專案pdf-reader- 正如您所見,各列之間的列間距非常不規則。
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com 12.00
11/4 Purchase authorized on 11/01 Google *Gsuite_Get 24.00
11/4 Purchase authorized on 11/02 Amazon Web Service 460.15
11/4 Purchase authorized on 11/02 Amazon Web Service 8.07 2,903.09
11/5 Recurring Payment authorized on 11/03 Atlassian 15.00 2,888.09
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY 24.00 2,864.09
11/12 Foobar Retail Dis 211011 ABCDEFGH 8,031.44
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# 45.00
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC 5,000.00 5,850.53
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN 100.00 5,702.53
上述交易是從具有以下視覺布局的銀行 PDF 中提取的

需要通過正則運算式決議粗體列:
- 日期- dd/mm 格式 - 始終存在
- 支票號碼 - 始終為空,可能會被忽略(字母數字單字?)
- 說明- 帶有日期、數字、特殊字符的文本 - 始終存在
- 積分- 貨幣金額(僅適用于存款)
- 借方- 貨幣金額(僅用于付款)
- 余額 - 貨幣金額(偶爾出現,不重要)
我只能/^(\d{1,2}\/\d{1,2})\s /mg提取 mm/dd。我是否應該從右邊開始計算數量,但是沒有明確的分隔符模式!
uj5u.com熱心網友回復:
列之間的間距是不規則的,但似乎總是大于 2。在這種情況下,您可以使用 3 個捕獲組和一個可選的第 4 部分以及借項部分的捕獲組。
^(\d{1,2}\/\d{1,2})\s{2,}(\S.*?)\s{2,}(\d{1,3}(?:,\d{3})*\.\d{2})(?:\s{2,}(\d{1,3}(?:,\d{3})*\.\d{2}))?
部分模式匹配:
^字串的開始(\d{1,2}\/\d{1,2})\s{2,}捕獲組 1匹配 1,2 位/1,2 位和 2 個或更多空白字符(\S.*?)\s{2,}捕獲組 2匹配至少一個非空白字符和盡可能少的字符,直到下一次出現 2 個或更多空白字符(\d{1,3}(?:,\d{3})*\.\d{2})捕獲組 3匹配數字格式(?:非捕獲組\s{2,}匹配 2 個或更多空白字符(\d{1,3}(?:,\d{3})*\.\d{2})捕獲組4,匹配數字格式
)?關閉非捕獲組并使其可選
查看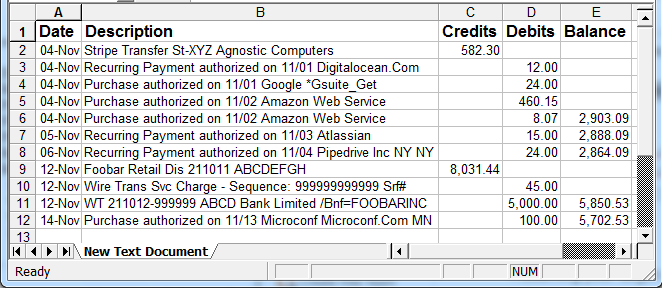
最好分階段處理任務,我首選的目標格式是電子表格的 CSV
TL;DR 見最后評論
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com 12.00
11/4 Purchase authorized on 11/01 Google *Gsuite_Get 24.00
11/4 Purchase authorized on 11/02 Amazon Web Service 460.15
11/4 Purchase authorized on 11/02 Amazon Web Service 8.07 2,903.09
11/5 Recurring Payment authorized on 11/03 Atlassian 15.00 2,888.09
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY 24.00 2,864.09
11/12 Foobar Retail Dis 211011 ABCDEFGH 8,031.44
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# 45.00
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC 5,000.00 5,850.53
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN 100.00 5,702.53
第一,我們可以瞄準更大的間隙,所以選擇一個合適的寬度,不用擔心他們以后會解決的錯位。
成為 ??.??
我們要么需要保護現有的逗號,所以用另一個未使用的符號替換它們,~或者為了貨幣最好從數字之間洗掉它們。
用虛擬擴展替換所有行尾,如果不是數字,那么列是否太多也沒關系,所以使用
??.?? ??.??(是的,在這種情況下,我們假設低于 1000 并且不能使用,# 或 *)
因此11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
變成 11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30 ??.?? ??.??
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30 ??.?? ??.??
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com ??.?? 12.00 ??.?? ??.??
11/4 Purchase authorized on 11/01 Google *Gsuite_Get ??.?? 24.00 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 460.15 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 8.07 2903.09 ??.?? ??.??
11/5 Recurring Payment authorized on 11/03 Atlassian ??.?? 15.00 2888.09 ??.?? ??.??
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY ??.?? 24.00 2864.09 ??.?? ??.??
11/12 Foobar Retail Dis 211011 ABCDEFGH 8031.44 ??.?? ??.??
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# ??.?? 45.00 ??.?? ??.??
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC ??.?? 5000.00 5850.53 ??.?? ??.??
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN ??.?? 100.00 5702.53 ??.?? ??.??
現在我們可以定位剩余的不規則空白,因此適當地用 2 或 3 個空格替換所有較大的空格(通常 2 就可以,但要注意任何帶有雙空格的描述。)
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30 ??.?? ??.??
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com ??.?? 12.00 ??.?? ??.??
11/4 Purchase authorized on 11/01 Google *Gsuite_Get ??.?? 24.00 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 460.15 ??.?? ??.??
11/4 Purchase authorized on 11/02 Amazon Web Service ??.?? 8.07 2903.09 ??.?? ??.??
11/5 Recurring Payment authorized on 11/03 Atlassian ??.?? 15.00 2888.09 ??.?? ??.??
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY ??.?? 24.00 2864.09 ??.?? ??.??
11/12 Foobar Retail Dis 211011 ABCDEFGH 8031.44 ??.?? ??.??
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# ??.?? 45.00 ??.?? ??.??
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC ??.?? 5000.00 5850.53 ??.?? ??.??
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN ??.?? 100.00 5702.53 ??.?? ??.??
最后添加標題, 用逗號分隔符替換并洗掉 ??.??
Date,Description,Credits,Debits,Balance,,,
11/4,Stripe Transfer St-XYZ Agnostic Computers,582.30,,
11/4,Recurring Payment authorized on 11/01 Digitalocean.Com,,12.00,,
11/4,Purchase authorized on 11/01 Google *Gsuite_Get,,24.00,,
11/4,Purchase authorized on 11/02 Amazon Web Service,,460.15,,
11/4,Purchase authorized on 11/02 Amazon Web Service,,8.07,2903.09,,
11/5,Recurring Payment authorized on 11/03 Atlassian,,15.00,2888.09,,
11/6,Recurring Payment authorized on 11/04 Pipedrive Inc NY NY,,24.00,2864.09,,
11/12,Foobar Retail Dis 211011 ABCDEFGH,8031.44,,
11/12,Wire Trans Svc Charge - Sequence: 999999999999 Srf#,,45.00,,
11/12,WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC,,5000.00,5850.53,,
11/14,Purchase authorized on 11/13 Microconf Microconf.Com MN,,100.00,5702.53,,
在匯入電子表格時,標題和可能的貨幣需要樣式。
事后我意識到你需要做的就是
- 洗掉逗號
- 在大的空白處注入一個虛擬列 3(甚至是一個 ~)
- 將空格減少到 2x 空格,然后用逗號替換這 2 個空格
- 洗掉虛擬條目,例如 ~
- 添加標題
Date,Description,Credits,Debits,Balance
其余的將自行處理。
uj5u.com熱心網友回復:
TL;博士
您的主要問題是,如果您在從 PDF 決議字串資料后處理它,那么很難確定哪些位置元素對應于哪個欄位。你真的應該打開一個單獨的問題,關于如何在 PDF 決議時解決這個問題,而不是在 PDF 決議階段之后嘗試決議文本。也就是說,下面是一個適用于您提供的有限示例的解決方案,并且至少應該讓您開始嘗試進行字串決議。
假設和例子
從您的示例中,您的格式似乎有一些隱含的業務規則:
- 某些欄位始終存在(例如日期和描述)。
- 每行只有一個借記卡或貸記卡。
- 每行最多有 4/5 個填充欄位。
但是,即使“余額”不重要,如果不參考某些現有余額或決議輸出中明確定義的空格數,您也無法真正判斷某物是貸方還是借方,因此您要么需要修復您的輸入資料或 PDF 決議,以確保您始終保持平衡(您可以在 PDF 決議時計算)或確保您知道 PDF 布局中的特定欄位寬度或 PDF 的決議輸出。
雖然只是您需要針對實際用例更新的部分解決方案,但您可以創建一個 Struct 或其他物件來保存您的資料,然后根據每個事務包含的欄位數或欄位之間的空格數做出額外的決議決策。一個潛在的解決方案如下。
使用 PDF 決議中的字串的示例
注意:下面的代碼示例在不影響結果的情況下已積極包裝為 60 個字符,以減少 StackOverflow 代碼塊中的橫向滾動。隨意重排代碼以適合您自己的樣式選擇。
我們將首先將您在原始帖子中提供的決議文本存盤在此處的檔案中,以便練習此代碼示例的其余部分。
text_extracted_from_pdf = <<~'EXTRACTED_TEXT'
11/4 Stripe Transfer St-XYZ Agnostic Computers 582.30
11/4 Recurring Payment authorized on 11/01 Digitalocean.Com 12.00
11/4 Purchase authorized on 11/01 Google *Gsuite_Get 24.00
11/4 Purchase authorized on 11/02 Amazon Web Service 460.15
11/4 Purchase authorized on 11/02 Amazon Web Service 8.07 2,903.09
11/5 Recurring Payment authorized on 11/03 Atlassian 15.00 2,888.09
11/6 Recurring Payment authorized on 11/04 Pipedrive Inc NY NY 24.00 2,864.09
11/12 Foobar Retail Dis 211011 ABCDEFGH 8,031.44
11/12 Wire Trans Svc Charge - Sequence: 999999999999 Srf# 45.00
11/12 WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC 5,000.00 5,850.53
11/14 Purchase authorized on 11/13 Microconf Microconf.Com MN 100.00 5,702.53
EXTRACTED_TEXT
We'll also define some constants that we'll use to parse your extracted text after the PDF parse, and a Struct class to hold the results of parsing each line of text. You may need to adjust these based on your real data.
# This describes what a currency item looks like after your
# PDF parse.
MONEY_FMT = /\b[\d,] \.\d{2}\b/
# Make some assumptions about fixed-width fields. These
# values seem reliable given the sample string data from
# your original post.
LN_START_TO_LAST_CRED_CHR = /^.{92}\.\d{2}$?/
LN_START_TO_END_OF_DEBIT = /^.{93,}#{MONEY_FMT}$?/
Transaction = Struct.new(:date, :description, :credit,
:debit, :balance, keyword_init:
true)
Now we read the output from the PDF parse to try to analyze the resulting string. Using Ruby 3.1.1, and with code aggressively wrapped to minimize side-scrolling on StackOverflow:
transactions = []
text_extracted_from_pdf.each_line do
fields = _1.split /\s{2,}/
date, description = fields.shift 2
balance = fields.pop.chomp if fields.count == 2
# This violates our rule of 4/5 populated fields.
raise "too many fields remaining: #{fields.count}" unless
fields.count == 1
# Match on characters from start of line to end of credit.
credit =
fields.pop.chomp if _1.match? LN_START_TO_LAST_CRED_CHR
# Match on characters from start of line to end of debit.
debit =
fields.pop.chomp if _1.match? LN_START_TO_END_OF_DEBIT
transactions << Transaction.new({date: date, description:
description, credit:
credit, debit: debit,
balance: balance})
end
Expected Result
The transactions array should now hold a collection of Transaction objects which you can iterate over as needed. For example, the example code above populates the transactions Array with the following Struct objects:
transactions
#=>
[#<struct Transaction date="11/4", description="Stripe Transfer St-XYZ Agnostic Computers", credit="582.30", debit=nil, balance=nil>,
#<struct Transaction date="11/4", description="Recurring Payment authorized on 11/01 Digitalocean.Com", credit=nil, debit="12.00", balance=nil>,
#<struct Transaction date="11/4", description="Purchase authorized on 11/01 Google *Gsuite_Get", credit=nil, debit="24.00", balance=nil>,
#<struct Transaction date="11/4", description="Purchase authorized on 11/02 Amazon Web Service", credit=nil, debit="460.15", balance=nil>,
#<struct Transaction date="11/4", description="Purchase authorized on 11/02 Amazon Web Service", credit=nil, debit="8.07", balance="2,903.09">,
#<struct Transaction date="11/5", description="Recurring Payment authorized on 11/03 Atlassian", credit=nil, debit="15.00", balance="2,888.09">,
#<struct Transaction date="11/6", description="Recurring Payment authorized on 11/04 Pipedrive Inc NY NY", credit=nil, debit="24.00", balance="2,864.09">,
#<struct Transaction date="11/12", description="Foobar Retail Dis 211011 ABCDEFGH", credit="8,031.44", debit=nil, balance=nil>,
#<struct Transaction date="11/12", description="Wire Trans Svc Charge - Sequence: 999999999999 Srf#", credit=nil, debit="45.00", balance=nil>,
#<struct Transaction date="11/12", description="WT 211012-999999 ABCD Bank Limited /Bnf=FOOBARINC", credit=nil, debit="5,000.00", balance="5,850.53">,
#<struct Transaction date="11/14", description="Purchase authorized on 11/13 Microconf Microconf.Com MN", credit=nil, debit="100.00", balance="5,702.53">]
Validate Your String Parse
A lot of things can go wrong when people make assumptions about either formatting or their code's logic. If you want to validate your Struct objects, you can iterate over the collection to identify bad parses, or you could choose to log, warn, or raise an exception inside your parsing loop above.
# If you have parsed both a credit and a debit on the same line,
# something's wrong.
transactions.map do
warn "bad parse for #{_1}" if _1.credit && _1.debit
end.compact!
#=> []
Instead of simply raising a warning here, you could also use Array#reject! to remove items directly from transactions which didn't parse properly, assuming you don't simply skip adding them to the collection in the first place within the #each_line loop above. How you choose to identify and handle a bad parse is really up to you; this is just one of many approaches, and is meant to illustrate that you need to validate the results of each PDF or string parse somewhere in your code.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/434165.html