所以我正在準備一個技術面試,我的一個練習題是第K個最小的數字。我知道我可以對 O(n * log(n)) 時間進行排序,并為 O(n * log(k)) 使用堆。但是我也知道我可以對 O(n) 的平均情況進行磁區(類似于快速排序)。
實際計算的平均時間復雜度應該是:

我已經使用 WolframAlpha 仔細檢查了這個數學,它同意。
所以我撰寫了我的解決方案,然后計算了隨機資料集的實際平均時間復雜度。對于較小的 n 值,它非常接近。例如,當我預計大約 5.7 時,n=5 可能會給我大約 6.2 的實際值。這個稍微多一點的錯誤是一致的。
當我增加 n 的值時,這只會變得更糟。例如,對于 n=5000,我的實際平均時間復雜度約為 15,000,而它應該略小于 10,000。
所以基本上,我的問題是這些額外的迭代來自哪里?我的代碼是錯的,還是我的數學?我的代碼如下:
import java.util.Arrays;
import java.util.Random;
public class Solution {
static long tc = 0;
static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
static int kMin(int[] arr, int k) {
arr = arr.clone();
int pivot = pivot(arr);
if(pivot > k) {
return kMin(Arrays.copyOfRange(arr, 0, pivot), k);
} else if(pivot < k) {
return kMin(Arrays.copyOfRange(arr, pivot 1, arr.length), k - pivot - 1);
}
return arr[k];
}
static int pivot(int[] arr) {
Random rand = new Random();
int pivot = rand.nextInt(arr.length);
swap(arr, pivot, arr.length - 1);
int i = 0;
for(int j = 0; j < arr.length - 1; j ) {
tc ;
if(arr[j] < arr[arr.length - 1]) {
swap(arr, i, j);
i ;
}
}
swap(arr, i, arr.length - 1);
return i;
}
public static void main(String args[]) {
int iterations = 10000;
int n = 5000;
for(int j = 0; j < iterations; j ) {
Random rd = new Random();
int[] arr = new int[n];
for (int i = 0; i < arr.length; i ) {
arr[i] = rd.nextInt();
}
int k = rd.nextInt(arr.length - 1);
kMin(arr, k);
}
System.out.println("Actual: " tc / (double)iterations);
double expected = 2.0 * n - 2.0 - (Math.log(n) / Math.log(2));
System.out.println("Expected: " expected);
}
}
uj5u.com熱心網友回復:
正如您和其他人在評論中指出的那樣,您的計算假設陣列在每次迭代時被隨機樞軸分成兩半,這是不正確的。這種不均勻的拆分會產生重大影響:例如,當您嘗試選擇的元素是實際中位數時,在一次隨機樞軸選擇后陣列的預期大小是原始的 75%,因為您將始終選擇兩個陣列中較大的一個。
為了準確估計 和 的每個值的預期比較n,kDavid Eppstein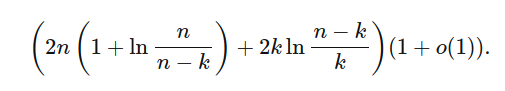
這是對您的值的非常接近的估計,即使這假設陣列中沒有重復項。

轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/434658.html
上一篇:有沒有漸近表示法的替代品?