在 Stackoverflow 上的一些明星的幫助下,我的情節就像一個魅力。這是代碼:
library(tidyverse)
require(scales)
library(ggrepel)
# ingest some sample data
structure(list(Q52_bin = structure(c(3L, 2L, 2L, 2L, 2L, 2L,
2L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), .Label = c("low", "medium",
"high"), class = "factor"), Q53_bin = structure(c(2L, 3L, 2L,
2L, 2L, 2L, 2L, 3L, 2L, 3L, 2L, 1L, 2L, 2L, 1L), .Label = c("low",
"medium", "high"), class = "factor"), Q57_bin = structure(c(2L,
2L, 2L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 3L, 2L, 2L, 2L, 2L), .Label = c("low",
"medium", "high"), class = "factor"), Q4 = c(2, 3, 3, 5, 4, 3,
4, 5, 2, 4, 2, 3, 5, 4, 3)), row.names = c(NA, -15L), class = c("tbl_df",
"tbl", "data.frame"))
names(df) <- c("Q52_bin", "Q53_bin", "Q57_bin", "response")
facet_names <- c(`Q52_bin` = "Spirituality", `Q53_bin` = "Politics L/R", `Q57_bin` = "Religiosity", `low`="low", `medium`="medium", `high`="high")
facet_labeller <- function(variable,value){return(facet_names[value])}
q4_levels = c("Not at all", "A little", "Some", "A lot", "A great deal")
df$response <- factor(df$response, ordered = TRUE, levels = c("5", "4", "3", "2", "1"))
df$response <- fct_recode(df$response, "Not at all" = "1", "A little" = "2", "Some" = "3", "A lot" = "4", "A great deal" = "5")
df %>%
pivot_longer(!response, names_to = "bin_name", values_to = "b") %>%
count(response, bin_name, b) %>%
ggplot(aes(x = n, y = "", fill = response))
geom_col(position="fill", aes(fill=response))
### Problem line is below
# geom_text(aes(label = n), position = position_stack(vjust = 0.5), size=2)
scale_fill_brewer(palette="YlOrBr")
scale_x_continuous(labels = scales::percent_format())
facet_grid(vars(b), vars(bin_name), labeller=as_labeller(facet_names))
labs(caption = "How much have you thought about climate change before today?", x = "", y = "")
guides(fill = guide_legend(title = NULL))
這里有兩個問題:首先,如果不使用 dplyr() 向資料框添加新列,我無法找到一種在條形圖上顯示百分比的好方法,這似乎過于復雜(尤其是考慮到我的刻面在這里做)。第二個問題是文本的顯示使圖表上的條形消失了!
uj5u.com熱心網友回復:
您正在使用position_fill條形圖,因此您也需要將其用于文本:
df %>%
pivot_longer(!response, names_to = "bin_name", values_to = "b") %>%
count(response, bin_name, b) %>%
group_by(bin_name, b) %>%
summarize(label = scales::percent(n / sum(n)), response, n) %>%
ggplot(aes(x = n, y = "", fill = response))
geom_col(position="fill", aes(fill=response))
geom_text(aes(label = label),
position = position_fill(vjust = 0.5), size = 3)
scale_fill_brewer(palette="YlOrBr")
scale_x_continuous(labels = scales::percent_format())
facet_grid(vars(b), vars(bin_name), labeller=as_labeller(facet_names))
labs(caption = "How much have you thought about climate change before today?",
x = "", y = "")
guides(fill = guide_legend(title = NULL))
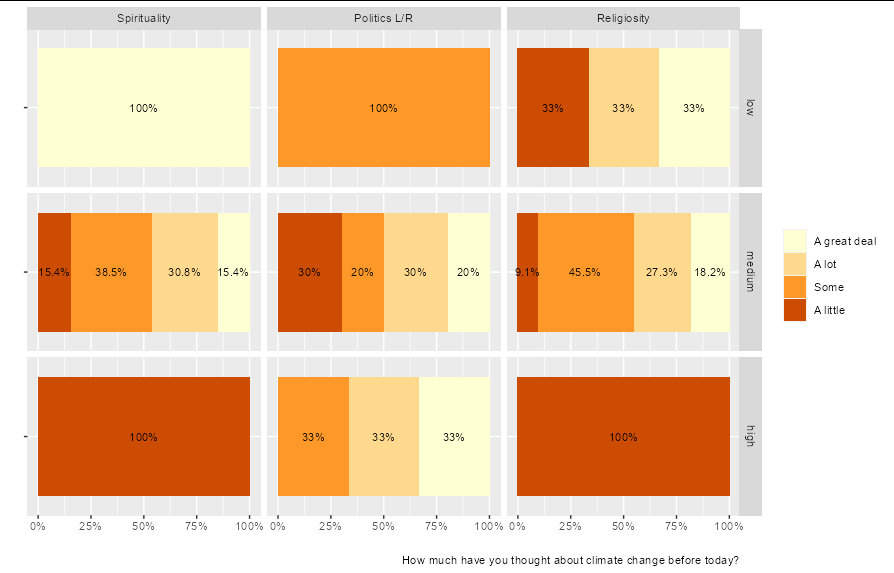
順便說一句,劇情不錯!
uj5u.com熱心網友回復:
我已經調整了df上一個問題的操作方式
df %>%
pivot_longer(!response, names_to = "bin_name", values_to = "b") %>%
count(response, bin_name, b) %>%
group_by(bin_name,b) %>%
mutate(perc=paste0(round(n*100/sum(n),1),"%")) %>%
ggplot(aes(x = n, y = "", fill = response))
geom_col(position=position_fill(), aes(fill=response))
geom_text(aes(label = perc), position = position_fill(vjust=.5), size=2)
scale_fill_brewer(palette="YlOrBr")
scale_x_continuous(labels = scales::percent_format())
facet_grid(vars(b), vars(bin_name), labeller=as_labeller(facet_names))
labs(caption = "How much have you thought about climate change before today?", x = "", y = "")
guides(fill = guide_legend(title = NULL))
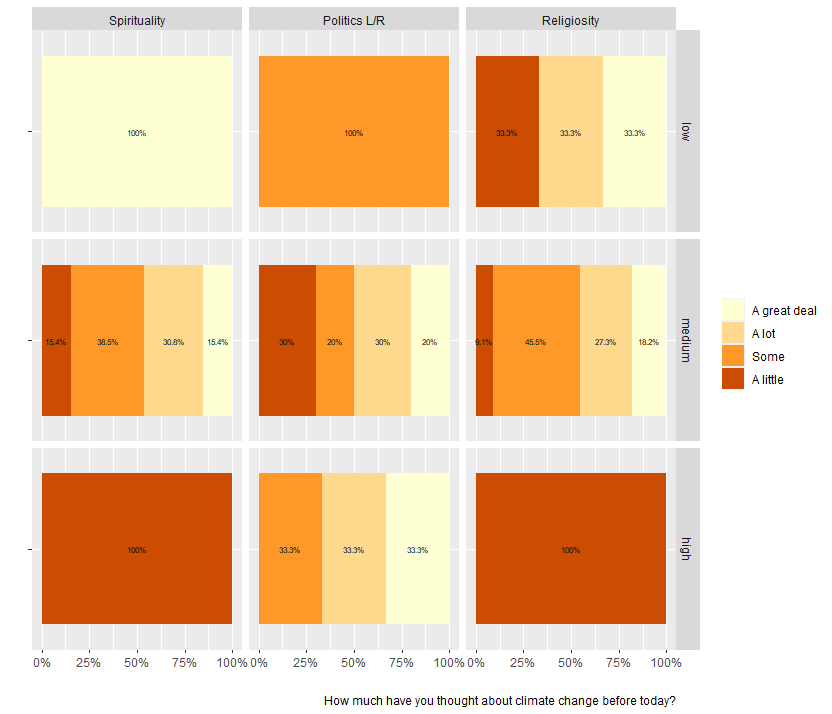
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/443270.html
下一篇:如何使用堆疊條制作多面條形圖?