我試圖了解口語和閱讀詞的頻率與文字游戲的表現如何相關。這是我的可重復樣本:
#Word Freq READ####
Master_error_analysis_READ <- structure(list(Target = c("BABY", "BAGEL", "BANDAGE", "BANJO",
"CARRIAGE", "CARROT", "CHICKEN", "CHIPMUNK", "CITY", "COBRA",
"COCOA", "FAIRY", "FERRET", "GARBAGE", "GARLIC", "LETTER", "LETTUCE",
"LOBSTER", "LOCKER", "MARBLE", "MARKER", "MUFFIN", "MUSHROOM",
"PASTA", "PEACOCK", "PEANUT", "POSSUM", "PUPPET", "PUPPY", "RACCOON",
"RACKET", "ROOSTER", "RULER", "SANDAL", "SANDWICH", "SCISSORS",
"TURKEY", "TURTLE", "WHISTLE", "WIZARD"), Word = c("BABY", "BAGEL",
"BANDAGE", "BANJO", "CARRIAGE", "CARROT", "CHICKEN", "CHIPMUNK",
"CITY", "COBRA", "COCOA", "FAIRY", "FERRET", "GARBAGE", "GARLIC",
"LETTER", "LETTUCE", "LOBSTER", "LOCKER", "MARBLE", "MARKER",
"MUFFIN", "MUSHROOM", "PASTA", "PEACOCK", "PEANUT", "POSSUM",
"PUPPET", "PUPPY", "RACCOON", "RACKET", "ROOSTER", "RULER", "SANDAL",
"SANDWICH", "SCISSORS", "TURKEY", "TURTLE", "WHISTLE", "WIZARD"
), n = c(14L, 6L, 3L, 13L, 4L, 14L, 17L, 13L, 6L, 9L, 6L, 12L,
9L, 11L, 8L, 6L, 4L, 12L, 8L, 13L, 13L, 12L, 16L, 14L, 11L, 12L,
6L, 14L, 14L, 8L, 10L, 8L, 6L, 16L, 15L, 14L, 10L, 11L, 8L, 7L
), `Frequency (Google Books)` = c(6127799, 29335, 428865, 125242,
2505730, 215525, 1724136, 30591, 30586130, 69450, 382604, 1082454,
115446, 674079, 651590, 20168453, 353798, 256454, 271988, 1996235,
769873, 81982, 270867, 238173, 149644, 277100, 76104, 384574,
316058, 73050, 268584, 136815, 1659585, 81154, 430627, 511265,
1763068, 396105, 778168, 309233), Freq = c(6127799, 29335, 428865,
125242, 2505730, 215525, 1724136, 30591, 30586130, 69450, 382604,
1082454, 115446, 674079, 651590, 20168453, 353798, 256454, 271988,
1996235, 769873, 81982, 270867, 238173, 149644, 277100, 76104,
384574, 316058, 73050, 268584, 136815, 1659585, 81154, 430627,
511265, 1763068, 396105, 778168, 309233)), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"), row.names = c(NA, -40L), groups = structure(list(
Target = c("BABY", "BAGEL", "BANDAGE", "BANJO", "CARRIAGE",
"CARROT", "CHICKEN", "CHIPMUNK", "CITY", "COBRA", "COCOA",
"FAIRY", "FERRET", "GARBAGE", "GARLIC", "LETTER", "LETTUCE",
"LOBSTER", "LOCKER", "MARBLE", "MARKER", "MUFFIN", "MUSHROOM",
"PASTA", "PEACOCK", "PEANUT", "POSSUM", "PUPPET", "PUPPY",
"RACCOON", "RACKET", "ROOSTER", "RULER", "SANDAL", "SANDWICH",
"SCISSORS", "TURKEY", "TURTLE", "WHISTLE", "WIZARD"), .rows = structure(list(
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L,
14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L,
25L, 26L, 27L, 28L, 29L, 30L, 31L, 32L, 33L, 34L, 35L,
36L, 37L, 38L, 39L, 40L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -40L), .drop = TRUE))
以及圖表的代碼
#rounding up from 6M (highest value)
coeff_WF_READ <- 10000000
#divided highest value from 10M, then applies same coeff to error analysis
coeff_Error_READ <- 27.742
ggplot(Master_error_analysis_READ, aes(x = reorder(Word, n)))
geom_point(aes(y = n / coeff_Error_READ), size = 4, color = "red")
geom_point(aes(y = Freq / coeff_WF_READ), shape=23, fill="blue", size=4)
scale_y_continuous(
name = "Number Correct",
sec.axis = sec_axis(~.*coeff_WF_READ, name = "Word Frequency"),
limits = c(NA, 1)
)
xlab("\nTarget word")
theme_bw(14)
theme(
axis.title.y = element_text(color = "red", size=13, face="bold"),
axis.title.y.right = element_text(color = "blue", size=13, face="bold"),
axis.text.x = element_text(angle = 45, vjust = 0.5, hjust=1)
)
ggtitle("Error analysis")
我對另一個圖表使用相同的代碼,其中包含來自口語的資料,而不是 READ 單詞。我不能簡單地將更多資料幀合并在一起,Master_error_analysis_READ因為這會導致錯誤:Error: suffix must be a character vector of length 2. ? suffix is a grouped_df/tbl_df/tbl/data.frame object of length 2.
我還能如何在一張圖中繪制兩個以上的圖表?這里總共將有三行,一行用于表演,一行用于口語,一行用于閱讀單詞。
您可以在下面找到該資料框。
Master_error_analysis_Spoken <- structure(list(Target = c("BABY", "BAGEL", "BANDAGE", "BANJO",
"CARRIAGE", "CARROT", "CHICKEN", "CHIPMUNK", "CITY", "COBRA",
"COCOA", "FAIRY", "FERRET", "GARBAGE", "GARLIC", "LETTER", "LETTUCE",
"LOBSTER", "LOCKER", "MARBLE", "MARKER", "MUFFIN", "MUSHROOM",
"PASTA", "PEACOCK", "PEANUT", "POSSUM", "PUPPET", "PUPPY", "RACCOON",
"RACKET", "ROOSTER", "RULER", "SANDAL", "SANDWICH", "SCISSORS",
"TURKEY", "TURTLE", "WHISTLE", "WIZARD"), Word = c("BABY", "BAGEL",
"BANDAGE", "BANJO", "CARRIAGE", "CARROT", "CHICKEN", "CHIPMUNK",
"CITY", "COBRA", "COCOA", "FAIRY", "FERRET", "GARBAGE", "GARLIC",
"LETTER", "LETTUCE", "LOBSTER", "LOCKER", "MARBLE", "MARKER",
"MUFFIN", "MUSHROOM", "PASTA", "PEACOCK", "PEANUT", "POSSUM",
"PUPPET", "PUPPY", "RACCOON", "RACKET", "ROOSTER", "RULER", "SANDAL",
"SANDWICH", "SCISSORS", "TURKEY", "TURTLE", "WHISTLE", "WIZARD"
), n = c(14L, 6L, 3L, 13L, 4L, 14L, 17L, 13L, 6L, 9L, 6L, 12L,
9L, 11L, 8L, 6L, 4L, 12L, 8L, 13L, 13L, 12L, 16L, 14L, 11L, 12L,
6L, 14L, 14L, 8L, 10L, 8L, 6L, 16L, 15L, 14L, 10L, 11L, 8L, 7L
), `Frequency (TV Corpus)` = c(134992, 1092, 801, 459, 1825,
1545, 18305, 279, 62051, 967, 1409, 3991, 617, 7496, 1938, 20534,
1010, 2775, 6017, 1262, 1507, 1863, 1093, 2179, 742, 3391, 741,
2303, 3527, 845, 1430, 817, 1379, 126, 8080, 2031, 6705, 4702,
3036, 3237), Freq = c(134992, 1092, 801, 459, 1825, 1545, 18305,
279, 62051, 967, 1409, 3991, 617, 7496, 1938, 20534, 1010, 2775,
6017, 1262, 1507, 1863, 1093, 2179, 742, 3391, 741, 2303, 3527,
845, 1430, 817, 1379, 126, 8080, 2031, 6705, 4702, 3036, 3237
)), class = c("grouped_df", "tbl_df", "tbl", "data.frame"), row.names = c(NA,
-40L), groups = structure(list(Target = c("BABY", "BAGEL", "BANDAGE",
"BANJO", "CARRIAGE", "CARROT", "CHICKEN", "CHIPMUNK", "CITY",
"COBRA", "COCOA", "FAIRY", "FERRET", "GARBAGE", "GARLIC", "LETTER",
"LETTUCE", "LOBSTER", "LOCKER", "MARBLE", "MARKER", "MUFFIN",
"MUSHROOM", "PASTA", "PEACOCK", "PEANUT", "POSSUM", "PUPPET",
"PUPPY", "RACCOON", "RACKET", "ROOSTER", "RULER", "SANDAL", "SANDWICH",
"SCISSORS", "TURKEY", "TURTLE", "WHISTLE", "WIZARD"), .rows = structure(list(
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L,
15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L,
27L, 28L, 29L, 30L, 31L, 32L, 33L, 34L, 35L, 36L, 37L, 38L,
39L, 40L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -40L), .drop = TRUE))
先感謝您!
uj5u.com熱心網友回復:
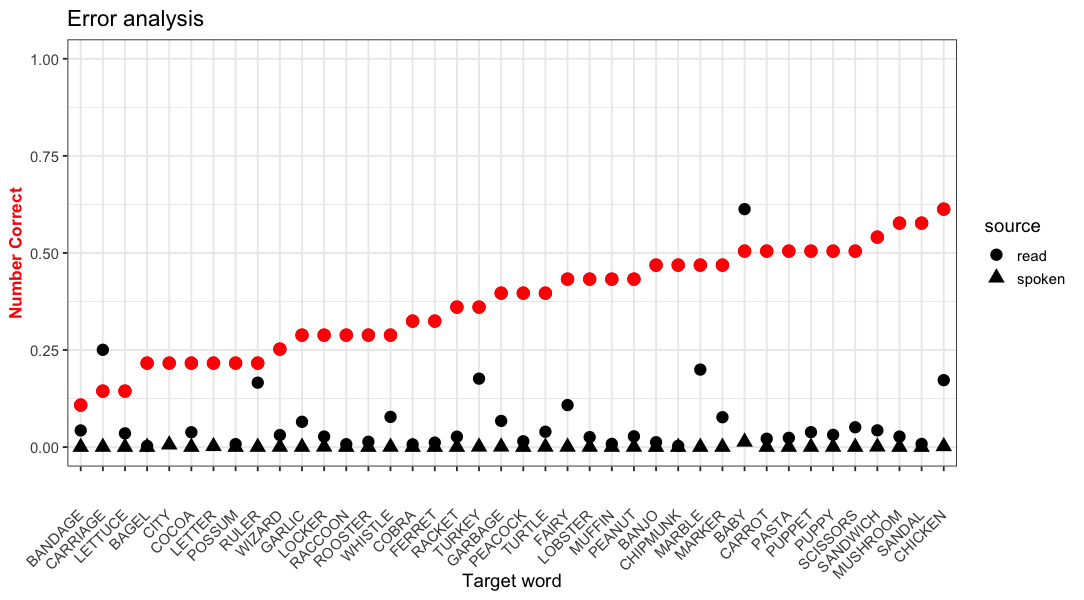
也許是這樣的?
library(dplyr);
combo <- bind_rows(
read = Master_error_analysis_READ,
spoken = Master_error_analysis_Spoken,
.id = "source")
ggplot(combo, aes(x = reorder(Word, n)))
geom_point(aes(y = n / coeff_Error_READ), size = 4, color = "red")
geom_point(aes(y = Freq / coeff_WF_READ, shape = source), fill="blue", size=4)
...
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/443277.html
上一篇:自定義意大利面條情節
下一篇:顯示百分比和值的堆疊條