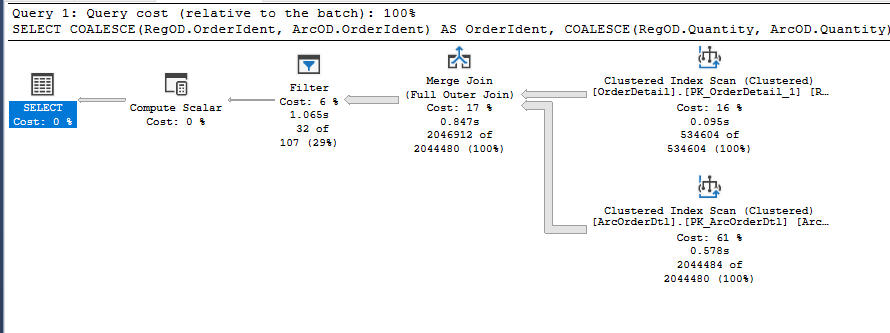
由于在一些較大的表上運行完整掃描以獲取報告,我遇到了一些性能問題。我已將范圍縮小到查詢的這一部分,但無法弄清楚如何在不更改結果的情況下避免掃描。
解釋一下,我們有一個資料歸檔系統,每天將資料從活動表復制到歸檔表。直到經過一段時間后,資料才會從活動表中洗掉。這會導致實時表和存檔表都具有相同的行,但行中的資料可能不匹配。
這排除了 UNION 查詢(??這將消除完整掃描)。要求報告顯示實時資料,所以我也不能只查詢存檔表。
有任何想法嗎?這是查詢。兩個表的主鍵都是 DetailIdent,但我在 OrderIdent 上有一個索引,因為它是回傳父表的外鍵。您可以看到,如果主表結果存在,我們將獲取它們,否則我們將回退到存檔資料。
SELECT COALESCE(RegOD.OrderIdent, ArcOD.OrderIdent) AS OrderIdent,
COALESCE(RegOD.Quantity, ArcOD.Quantity) AS Quantity,
COALESCE(RegOD.LoadQuan, ArcOD.LoadQuan) AS LoadQuan,
COALESCE(RegOD.ShipQuan, ArcOD.ShipQuan) AS ShipQuan,
COALESCE(RegOD.RcvdQuan, ArcOD.RcvdQuan) AS RcvdQuan,
COALESCE(RegOD.UOM, ArcOD.UOM) AS UOM,
COALESCE(RegOD.SkidType, ArcOD.SkidType) AS SkidType,
COALESCE(RegOD.Product, ArcOD.Product) AS Product,
COALESCE(RegOD.PkgCode, ArcOD.PkgCode) AS PkgCode
FROM OrderDetail RegOD
FULL JOIN dbo.ArcOrderDtl ArcOD
ON ArcOD.DetailIdent = RegOD.DetailIdent
WHERE COALESCE(RegOD.OrderIdent, ArcOD.OrderIdent) = 717010
uj5u.com熱心網友回復:
過濾謂詞COALESCE(RegOD.OrderIdent,ArcOD.OrderIdent) = 717010正在扼殺性能,它迫使引擎首先執行完整掃描,然后過濾資料。
選項 1 - 改寫 COALESCE() 函式
改寫COALESCE()函式并讓引擎完成它的作業。運氣好的話,引擎會很聰明地找到優化。在這種情況下,查詢可以采用以下形式:
SELECT
COALESCE(RegOD.OrderIdent,ArcOD.OrderIdent) AS OrderIdent,
COALESCE(RegOD.Quantity,ArcOD.Quantity) AS Quantity,
COALESCE(RegOD.LoadQuan,ArcOD.LoadQuan) AS LoadQuan,
COALESCE(RegOD.ShipQuan,ArcOD.ShipQuan) AS ShipQuan,
COALESCE(RegOD.RcvdQuan,ArcOD.RcvdQuan) AS RcvdQuan,
COALESCE(RegOD.UOM,ArcOD.UOM) AS UOM,
COALESCE(RegOD.SkidType,ArcOD.SkidType) AS SkidType,
COALESCE(RegOD.Product,ArcOD.Product) AS Product,
COALESCE(RegOD.PkgCode,ArcOD.PkgCode) AS PkgCode
FROM OrderDetail RegOD
FULL JOIN dbo.ArcOrderDtl ArcOD ON ArcOD.DetailIdent = RegOD.DetailIdent
WHERE RegOD.OrderIdent = 717010 or ArcOD.OrderIdent = 717010
選項 2 - 將左連接與右反連接組合,而不是使用完全連接
如果引擎沒有優化上面的選項 #1,您仍然可以嘗試將左連接與右反連接組合,而不是撰寫完全連接(它們是等效的)。它肯定更冗長,但在這種情況下,它清楚地顯示了引擎要做什么。此查詢可能如下所示:
SELECT -- left join here
COALESCE(RegOD.OrderIdent,ArcOD.OrderIdent) AS OrderIdent,
COALESCE(RegOD.Quantity,ArcOD.Quantity) AS Quantity,
COALESCE(RegOD.LoadQuan,ArcOD.LoadQuan) AS LoadQuan,
COALESCE(RegOD.ShipQuan,ArcOD.ShipQuan) AS ShipQuan,
COALESCE(RegOD.RcvdQuan,ArcOD.RcvdQuan) AS RcvdQuan,
COALESCE(RegOD.UOM,ArcOD.UOM) AS UOM,
COALESCE(RegOD.SkidType,ArcOD.SkidType) AS SkidType,
COALESCE(RegOD.Product,ArcOD.Product) AS Product,
COALESCE(RegOD.PkgCode,ArcOD.PkgCode) AS PkgCode
FROM OrderDetail RegOD
LEFT JOIN dbo.ArcOrderDtl ArcOD ON ArcOD.DetailIdent = RegOD.DetailIdent
WHERE RegOD.OrderIdent = 717010
UNION ALL
SELECT -- right anti-join here
OrderIdent,
Quantity,
LoadQuan,
ShipQuan,
RcvdQuan,
UOM,
SkidType,
Product,
PkgCode
FROM dbo.ArcOrderDtl ArcOD
LEFT JOIN OrderDetail RegOD ON ArcOD.DetailIdent = RegOD.DetailIdent
WHERE ArcOD.OrderIdent = 717010 and RegOD.DetailIdent IS NULL
uj5u.com熱心網友回復:
您需要 OrderIdent 的所有行,但行(由 DetailIdent 標識)可以在 OrderDetail 或 ArcOrderDtl 中,或兩者兼有。如果存在 OrderDetail 行,您希望優先考慮它們。
因此,一個想法是選擇所有行,然后對它們進行排名,給 OrderDetail 一個比 ArcOrderDtl 更好的排名,TOP WITH TIES然后使用它來獲取所有排名更好的行并忽略其他行。
SELECT TOP(1) WITH TIES
OrderIdent, Quantity, LoadQuan, ShipQuan, RcvdQuan, UOM, SkidType, Product, PkgCode
FROM
(
SELECT
DetailIdent, OrderIdent, Quantity, LoadQuan, ShipQuan, RcvdQuan, UOM, SkidType,
Product, PkgCode, 1 AS priority
FROM OrderDetail
WHERE OrderIdent = 717010
UNION ALL
SELECT
DetailIdent, OrderIdent, Quantity, LoadQuan, ShipQuan, RcvdQuan, UOM, SkidType,
Product, PkgCode, 2 AS priority
FROM dbo.ArcOrderDtl
WHERE OrderIdent = 717010
) unioned
ORDER BY RANK() (PARTITION BY DetailIdent ORDER BY priority);
uj5u.com熱心網友回復:
嘗試在索引中包含所有列,例如:
CREATE NONCLUSTERED INDEX IX_OrderDetail_OrderIdent
ON OrderDetail (OrderIdent)
INCLUDE (—ALL COLUMN IN SELECT)
GO
CREATE NONCLUSTERED INDEX IX_OrderDtl_OrderIdent
ON OrderDtl (OrderIdent)
INCLUDE (—ALL COLUMN IN SELECT)
GO
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/446836.html