我有興趣在我的 ggplot 條形圖上方添加分組標簽。此功能存在于資料可視化中,例如系統發育樹(在ggtree中),但我還沒有找到在 ggplot 中執行此操作的方法。
我試過玩弄 geom_text 和 geom_label,但還沒有成功。也許還有另一個包可以啟用此功能?我附上了一些應該完全可重現的示例代碼。我希望評級變數超過列出的大陸的條形(跨越多個大陸)。
任何幫助是極大的贊賞!謝謝!
PS 請原諒所有的評論——我正在寫一個教學教程。
#load necessary packages
library(tidyverse)
library(stringr)
library(hrbrthemes)
library(scales)
#load data
covid<- read_csv("https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/owid-covid-data.csv", na = ".")
#this makes a new dataframe (total_cases) that only has the latest COVID cases count and location data
total_cases <- covid %>% filter(date == "2021-05-23") %>%
group_by(location, total_cases) %>%
summarize()
#get number for world total cases.
world <- total_cases %>%
filter(location == "World") %>%
select(total_cases)
#make new column that has the proportion of total world cases (number was total on that day)
total_cases$prop_total <- total_cases$total_cases/world$total_cases
#this specifies what the continents are so we can filter them out with dplyr
continents <- c("North America", "South America", "Antarctica", "Asia", "Europe", "Africa", "Australia")
#Using dyplr, we're choosing total_cases pnly for the continents
contin_cases <- total_cases %>%
filter(location %in% continents)
#Loading a colorblind accessible palette
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7")
#Add a column that rates proportion of cases categorically.
contin_cases <- contin_cases %>%
mutate(rating = case_when(prop_total <= 0.1 ~ 'low',
prop_total <= 0.2 ~ 'medium',
prop_total <= 1 ~ 'high'))
#Ploting it on a bar chart.
plot1 <- ggplot(contin_cases,
aes(x = reorder(location, prop_total),
y = prop_total,
fill = location))
geom_bar(stat="identity", color="white")
ylim(0, 1)
geom_text(aes(y = prop_total,
label = round(prop_total, 4)),
vjust = -1.5)
scale_fill_manual(name = "Continent",
values = cbbPalette)
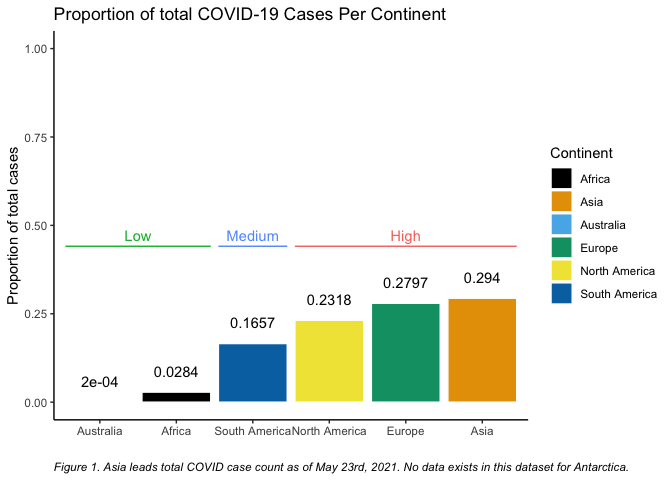
labs(title = "Proportion of total COVID-19 Cases Per Continent",
caption ="Figure 1. Asia leads total COVID case count as of May 23rd, 2021. No data exists in this dataset for Antarctica.")
ylab("Proportion of total cases")
xlab("") #this makes x-axis blank
theme_classic()
theme(
plot.caption = element_text(hjust = 0, face = "italic"))
plot1
這與我想要實作的目標類似:
條形圖顯示截至 2021 年 5 月各大陸的 COVID 病例總數
uj5u.com熱心網友回復:
實作所需結果的一種方法是通過geom_segment. 為此,我首先準備一個資料集,其中包含要按評級組放在條形頂部的段的開始和結束位置。基本上,這涉及將離散位置轉換為數字。
之后,添加段和標簽非常簡單。
library(tidyverse)
library(hrbrthemes)
library(scales)
# Loading a colorblind accessible palette
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7")
width <- .45 # Half of default width of bars
df_segment <- contin_cases %>%
ungroup() %>%
# Convert location to numerics
mutate(loc_num = as.numeric(fct_reorder(location, prop_total))) %>%
group_by(rating) %>%
summarise(x = min(loc_num) - width, xend = max(loc_num) width,
y = max(prop_total) * 1.5, yend = max(prop_total) * 1.5)
ggplot(
contin_cases,
aes(
x = reorder(location, prop_total),
y = prop_total,
fill = location
)
)
geom_bar(stat = "identity", color = "white")
ylim(0, 1)
geom_segment(data = df_segment, aes(x = x, xend = xend, y = max(y), yend = max(yend),
color = rating, group = rating),
inherit.aes = FALSE, show.legend = FALSE)
geom_text(data = df_segment, aes(x = .5 * (x xend), y = max(y), label = str_to_title(rating), color = rating),
vjust = -.5, inherit.aes = FALSE, show.legend = FALSE)
geom_text(aes(
y = prop_total,
label = round(prop_total, 4)
),
vjust = -1.5
)
scale_fill_manual(
name = "Continent",
values = cbbPalette
)
labs(
title = "Proportion of total COVID-19 Cases Per Continent",
caption = "Figure 1. Asia leads total COVID case count as of May 23rd, 2021. No data exists in this dataset for Antarctica."
)
ylab("Proportion of total cases")
xlab("") # this makes x-axis blank
theme_classic()
theme(
plot.caption = element_text(hjust = 0, face = "italic")
)
資料
contin_cases <- structure(list(location = c(
"Africa", "Asia", "Australia", "Europe",
"North America", "South America"
), total_cases = c(
4756650, 49204489,
30019, 46811325, 38790782, 27740153
), prop_total = c(
0.0284197291646085,
0.293983843894959, 0.000179355607369132, 0.2796853202015, 0.231764691226676,
0.165740097599109
), rating = c(
"low", "high", "low", "high",
"high", "medium"
)), class = c(
"grouped_df", "tbl_df", "tbl",
"data.frame"
), row.names = c(NA, -6L), groups = structure(list(
location = c(
"Africa", "Asia", "Australia", "Europe", "North America",
"South America"
), .rows = structure(list(
1L, 2L, 3L, 4L,
5L, 6L
), ptype = integer(0), class = c(
"vctrs_list_of",
"vctrs_vctr", "list"
))
), row.names = c(NA, -6L), class = c(
"tbl_df",
"tbl", "data.frame"
), .drop = TRUE))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/452350.html
上一篇:將主題存盤在自定義函式中