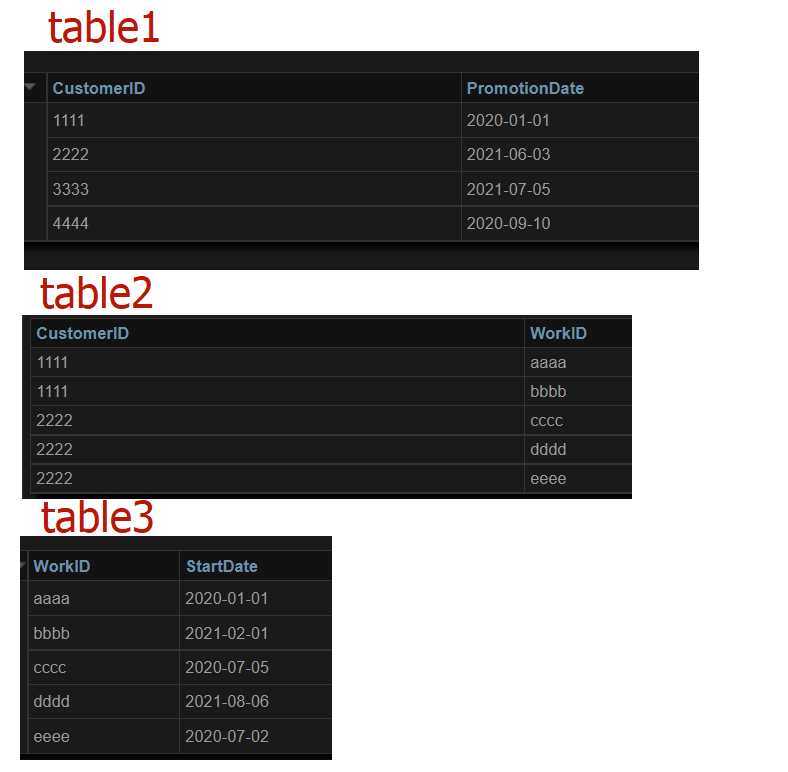
我有 3 張桌子:
CustomerID | PromotionDate
1111 | 01-01-2020
2222 | 03-06-2021
3333 | 05-07-2021
4444 | 09-10-2020
CustomerID | WorkID
1111 | aaaa
1111 | bbbb
2222 | cccc
2222 | dddd
2222 | eeee
WorkID | StartDate
aaaa | 01-01-2020
bbbb | 01-02-2021
cccc | 05-07-2020
dddd | 06-08-2021
eeee | 03-07-2022
我想找到每個 CustomerID 的 WorkID 計數,其中 StartDate >= PromotionDate 為該 CustomerID。
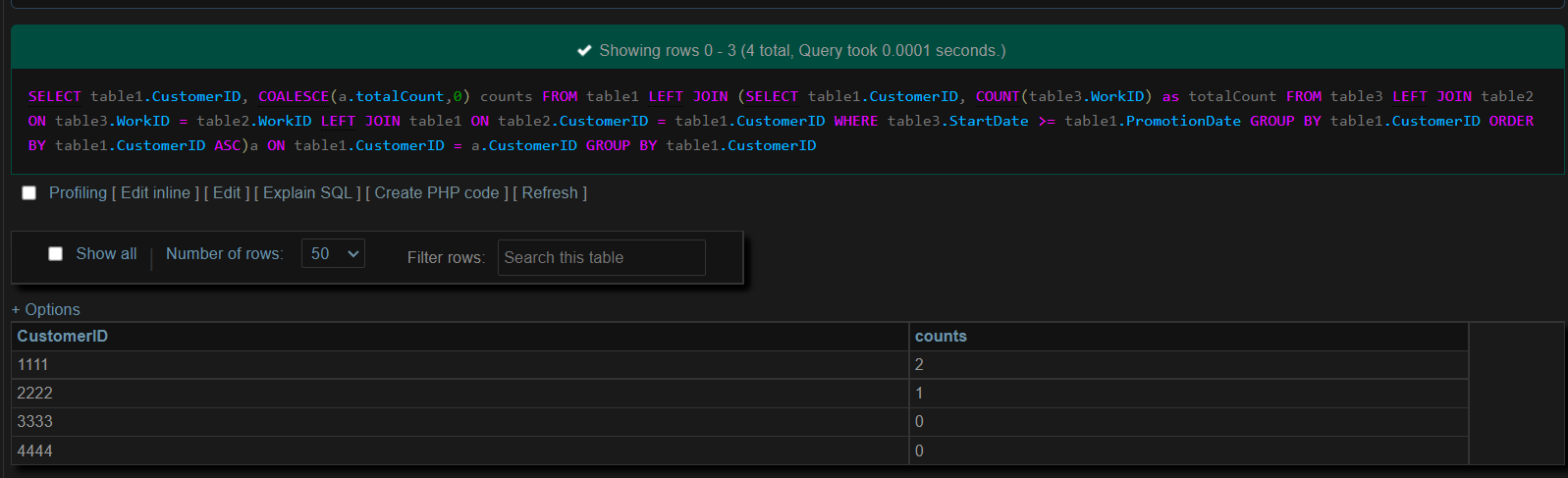
所以上述樣本的結果應該是:
CustomerID | Count
1111 | 2
2222 | 2
3333 | 0
4444 | 0
如何做到這一點?
uj5u.com熱心網友回復:
用真實姓名替換表名,除此之外應該可以正常作業。
SELECT table1.CustomerID, COALESCE(a.totalCount,0) counts FROM table1
LEFT JOIN (SELECT table1.CustomerID, COUNT(table3.WorkID) as totalCount
FROM table3
LEFT JOIN table2 ON table3.WorkID = table2.WorkID
LEFT JOIN table1 ON table2.CustomerID = table1.CustomerID
WHERE table3.StartDate >= table1.PromotionDate
GROUP BY table1.CustomerID ORDER BY table1.CustomerID ASC)a ON table1.CustomerID = a.CustomerID GROUP BY table1.CustomerID
我正在使用呼叫的聚合函式COUNT()來計算同一客戶的類似出現次數。GROUP BY將相似的記錄合并為一個,以便使用該COUNT()功能。ORDER BY用于按 CustomerID 對其進行排序
我的資料:
結果:
uj5u.com熱心網友回復:
免責宣告:我不使用 PostgreSQL,所以可能有更好的選擇。然而,一般的方法是使用條件 SUM() 來計算記錄的數量,其中StartDate >= PromotionDate:
SELECT t1.CustomerId
, SUM( CASE WHEN t3.StartDate >= t1.PromotionDate THEN 1 ELSE 0 END ) AS "Count"
FROM Table1 t1
LEFT JOIN Table2 t2 ON t1.CustomerID = t2.CustomerID
LEFT JOIN Table3 t3 ON t2.WorkId = t3.WorkId
GROUP BY t1.CustomerId
結果:
| 客戶ID | 總數 |
|---|---|
| 1111 | 2 |
| 2222 | 2 |
| 3333 | 0 |
| 4444 | 0 |
db<>在這里擺弄
uj5u.com熱心網友回復:
這應該在 Redshift 中作業:
SELECT p.customerid
, count(s.startdate >= p.promotiondate OR NULL) AS total_count
FROM cust_promo p
LEFT JOIN cust_work w ON w.customerid = p.customerid
LEFT JOIN work_start s ON s.workid = w.workid
GROUP BY p.customerid;
db<>在這里擺弄
假設workid在UNIQUE表中work_start(似乎合理)。
聚合FILTER子句在現代 Postgres 中表現更好。但是 Redshift 自從它的分叉很久以前就沒有跟上:
SELECT p.customerid
, count(*) FILTER (WHERE s.startdate >= p.promotiondate) AS total_count
FROM cust_promo p
LEFT JOIN cust_work w ON w.customerid = p.customerid
LEFT JOIN work_start s ON s.workid = w.workid
GROUP BY p.customerid;
看:
- 如何在 SQL 中獲取最新的非負值?
- 對于絕對性能,SUM 更快還是 COUNT 更快?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/452524.html
標籤:sql PostgreSQL 加入 数数 亚马逊红移