我正在使用beautifulsoup并selenium在 python 中抓取一些資料。這是我通過 url 運行的代碼https://www.flashscore.co.uk/match/YwbnUyDn/#/match-summary/point-by-point/10:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
DRIVER_PATH = '$PATH/chromedriver.exe'
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)
class_name = "matchHistoryRow__dartThrows"
def write_to_output(url):
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
print(soup.find_all("div", {"class": class_name}))
return
這是我試圖抓取的模式 - 我想在冒號之間獲取一對跨度并將它們放入 csv 上的單獨列中,問題是class冒號之前或之后出現,所以我不確定如何去做這件事。例如:
<div class="matchHistoryRow__dartThrows"><span><span class="matchHistoryRow__dartServis">321</span>:<span>501</span>
<span class="dartType dartType__180" title="180 thrown">180</span></span>, <span><span>321</span>:<span
class="matchHistoryRow__dartServis">361</span><span class="dartType dartType__140"
title="140 thrown">140 </span></span>, <span><span
class="matchHistoryRow__dartServis">224</span>:<span>361</span></span></div>
我希望在 csv 中以這種方式表示:
player_1_score,player_2_score
321,501
321,361
224,361
解決這個問題的最佳方法是什么?
uj5u.com熱心網友回復:
您可以使用正則運算式來決議分數(最簡單的方法,如果文本結構相應):
import re
import pandas as pd
from bs4 import BeautifulSoup
html_doc = """
<div ><span><span >321</span>:<span>501</span>
<span title="180 thrown">180</span></span>, <span><span>321</span>:<span
>361</span><span
title="140 thrown">140 </span></span>, <span><span
>224</span>:<span>361</span></span></div>
"""
soup = BeautifulSoup(html_doc, "html.parser")
# 1. parse whole text from a row
txt = soup.select_one(".matchHistoryRow__dartThrows").get_text(
strip=True, separator=" "
)
# 2. find scores with regex
scores = re.findall(r"(\d )\s :\s (\d )", txt)
# 3. create dataframe from regex
df = pd.DataFrame(scores, columns=["player_1_score", "player_2_score"])
print(df)
df.to_csv("data.csv", index=False)
印刷:
player_1_score player_2_score
0 321 501
1 321 361
2 224 361
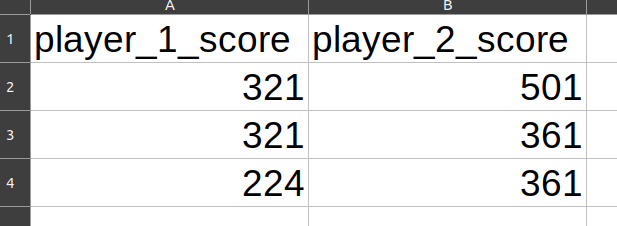
這個箱子data.csv(來自 LibreOffice 的截圖):
另一種方法,不使用re:
scores = [
s.get_text(strip=True)
for s in soup.select(
".matchHistoryRow__dartThrows > span > span:nth-of-type(1), .matchHistoryRow__dartThrows > span > span:nth-of-type(2)"
)
]
df = pd.DataFrame(
{"player_1_score": scores[::2], "player_2_score": scores[1::2]}
)
print(df)
uj5u.com熱心網友回復:
使用硒和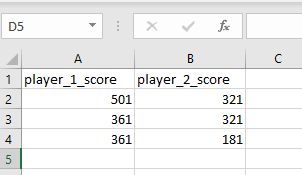
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/454798.html