我有一個如下的原始資料集:
| 可樂 | ColB | 期間 | 間隔 | 柜臺 |
|---|---|---|---|---|
| 一種 | 標清 | 2 | 4 | 1 |
| 一種 | 標清 | 3 | 3 | 2 |
| 一種 | UD | 2 | 1 | 10 |
| 乙 | UD | 1 | 2 | 2 |
| 乙 | UD | 2 | 2 | 2 |
| 乙 | 標清 | 3 | 3 | 13 |
| 乙 | 標清 | 1 | 4 | 19 |
我期待如下輸出結果:
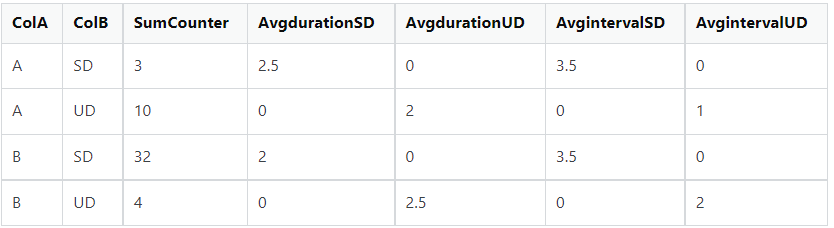
輸出說明:
- SumCounter 是 ColA 和 ColB 值對組的計數器值的總和。
- AvgdurationSD/UD 和 AvgIntervalSD/UD 是通過對 ColA 和 ColB 取平均值并在列不符合條件時具有 0 值創建的(例如,對于 ColA = A 和 ColB = UD 的組,AvgDurationSD 和 AvIntervalSD 的值為 0。
我知道我必須使用group by和agg函式才能在此處應用,但我不確定如何在單個新列上應用 ColB 的條件。
任何幫助表示贊賞:)
uj5u.com熱心網友回復:
通過復制 likeDataFrame.pivot_table與幫助列一起使用,然后展平并將輸出添加到由 aggregate 創建的新 DataFrame :newColBMultiIndexsum
df1 = (df.assign(new=df['ColB'])
.pivot_table(index=['ColA', 'ColB'],
columns='new',
values=['interval','duration'],
fill_value=0,
aggfunc='mean'))
df1.columns = df1.columns.map(lambda x: f'{x[0]}{x[1]}')
df = (df.groupby(['ColA','ColB'])['Counter']
.sum()
.to_frame(name='SumCounter')
.join(df1).reset_index())
print (df)
ColA ColB SumCounter durationSD durationUD intervalSD intervalUD
0 A SD 3 2.5 0.0 3.5 0
1 A UD 10 0.0 2.0 0.0 1
2 B SD 32 2.0 0.0 3.5 0
3 B UD 4 0.0 1.5 0.0 2
uj5u.com熱心網友回復:
您可以嘗試按列分組和A按列分組BNamed Aggregation
out = df.groupby('ColA').apply(lambda g: g.groupby('ColB').agg({'duration': [(f'{g["ColB"].iloc[0]}', 'mean')],
'interval': [(f'{g["ColB"].iloc[0]}', 'mean')],
'Counter': 'sum'})).fillna(0)
print(out)
duration interval Counter duration interval
SD SD sum UD UD
ColA ColB
A SD 2.5 3.5 3 0.0 0.0
UD 2.0 1.0 10 0.0 0.0
B SD 0.0 0.0 32 2.0 3.5
UD 0.0 0.0 4 1.5 2.0
然后重命名多索引列
out.columns = ['SumCounter' if 'Counter' in col[0] else f'Avg{col[0]}{col[1]}' for col in out.columns.values]
print(out)
AvgdurationSD AvgintervalSD SumCounter AvgdurationUD AvgintervalUD
ColA ColB
A SD 2.5 3.5 3 0.0 0.0
UD 2.0 1.0 10 0.0 0.0
B SD 0.0 0.0 32 2.0 3.5
UD 0.0 0.0 4 1.5 2.0
uj5u.com熱心網友回復:
groupby 的一個選項:
temp = (df
.assign(dummy = df.ColB)
.groupby(['ColA','ColB','dummy'])
.agg({'duration':'mean', 'interval':'mean', 'Counter':'sum'})
.rename(columns = {'Counter':'SumCounter'})
.set_index('SumCounter', append = True)
.unstack('dummy', fill_value = 0)
)
temp.columns = temp.columns.map(lambda x: f"Avg{''.join(x)}")
temp.reset_index()
ColA ColB SumCounter AvgdurationSD AvgdurationUD AvgintervalSD AvgintervalUD
0 A SD 3 2.5 0.0 3.5 0.0
1 A UD 10 0.0 2.0 0.0 1.0
2 B SD 32 2.0 0.0 3.5 0.0
3 B UD 4 0.0 1.5 0.0 2.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/458769.html