我的資料:
data <- structure(list(col1 = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), col2 = c(0L, 1L, 1L, 0L, 0L,
1L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 0L, 1L, 0L, 1L, 0L)), class = "data.frame", row.names = c(NA,
-18L))
我想獲得 2 個基于col1和的新列col2。
- 獲得第 3 列:如果第二列為零,我們留下單位,則簡單地轉移 2。
- 第 4 列將變成:如果第二列中有一個,我們會留下單位,2 只是簡單地轉移。
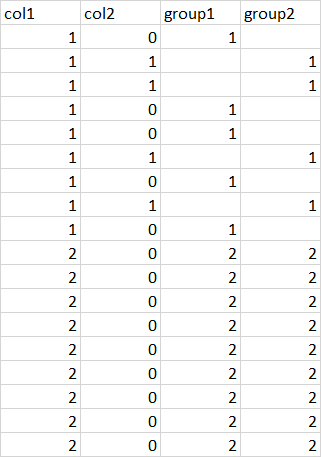
我想得到什么:
data <- structure(list(col1 = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), col2 = c(0L, 1L, 1L, 0L, 0L,
1L, 0L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L), group1 = c(1L,
NA, NA, 1L, 1L, NA, 1L, NA, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L), group2 = c(NA, 1L, 1L, NA, NA, 1L, NA, 1L, NA, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L)), class = "data.frame", row.names = c(NA,
-18L))
uj5u.com熱心網友回復:
使用的解決方案tidyr::pivot_wider():
library(dplyr)
data %>%
mutate(id = 1:n(), name = paste0("group", col2 1), value = 1) %>%
tidyr::pivot_wider() %>%
mutate(col2 = replace(col2, col1 == 2, 0),
across(starts_with("group"), replace, col1 == 2, 2)) %>%
select(-id)
# A tibble: 18 x 4
col1 col2 group1 group2
<int> <dbl> <dbl> <dbl>
1 1 0 1 NA
2 1 1 NA 1
3 1 1 NA 1
4 1 0 1 NA
5 1 0 1 NA
6 1 1 NA 1
7 1 0 1 NA
8 1 1 NA 1
9 1 0 1 NA
10 2 0 2 2
11 2 0 2 2
12 2 0 2 2
13 2 0 2 2
14 2 0 2 2
15 2 0 2 2
16 2 0 2 2
17 2 0 2 2
18 2 0 2 2
uj5u.com熱心網友回復:
您可以使用ifelse獲取group1和group2。
transform(data
, group1 = ifelse(col1==2, 2, ifelse(col2==0, 1, NA))
, group2 = ifelse(col1==2, 2, ifelse(col2==1, 1, NA))
)
# col1 col2 group1 group2
#1 1 0 1 NA
#2 1 1 NA 1
#3 1 1 NA 1
#4 1 0 1 NA
#5 1 0 1 NA
#6 1 1 NA 1
#7 1 0 1 NA
#8 1 1 NA 1
#9 1 0 1 NA
#10 2 0 2 2
#11 2 1 2 2
#12 2 1 2 2
#13 2 0 2 2
#14 2 0 2 2
#15 2 1 2 2
#16 2 0 2 2
#17 2 1 2 2
#18 2 0 2 2
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/458775.html