我想在我的系數圖中包含一個輔助 y 軸。在輔助軸上,我想顯示一個包含點估計值及其 95% CI 的 var。如果輔助軸上的資訊是數字但我的 var 是字符,那么到目前為止我看到的示例都有效。例如,在下圖中,次要 y 軸顯示了一個 p 值,
在下面的示例資料中,我想顯示標記為“估計”的 var,其中 P 值顯示在下面的示例圖中。
structure(list(Exposure = c("Organic Carbon", "Organic Carbon",
"Organic Carbon", "Organic Carbon", "Black Carbon", "Black Carbon",
"Black Carbon", "Black Carbon", "Carbon Monoxide", "Carbon Monoxide",
"Carbon Monoxide", "Carbon Monoxide"), `Unit Increase` = c("1 μg/m3",
"1 μg/m3", "1 μg/m3", "1 μg/m3", "1 μg/m3", "1 μg/m3", "1 μg/m3",
"1 μg/m3", "10 ppbv", "10 ppbv", "10 ppbv", "10 ppbv"), Models = c("Model 1",
"Model 2", "Model 3", "Model 4", "Model 1", "Model 2", "Model 3",
"Model 4", "Model 1", "Model 2", "Model 3", "Model 4"), mean = c(1.00227974541066,
0.985112091974051, 0.983374917346068, 0.981911815085857, 1.05170784539884,
0.866397662179956, 0.852380008027597, 0.843141476496602, 1.0285956205419,
1.01469851838101, 1.01167376733896, 1.01112354142356), sd = c(0.009168606994035,
0.00941380294243673, 0.00930958569680644, 0.00931923969816641,
0.0923351388901415, 0.0926479017865309, 0.0923142930597128, 0.0916749212837342,
0.000753411222911813, 0.000758915467329065, 0.000747152757518728,
0.000748722745120326), lci = c(0.984429504585927, 0.967102723558839,
0.96559452133446, 0.964139630281724, 0.877605428442938, 0.722528919823888,
0.711303894242616, 0.704476676931527, 1.01351836592852, 0.999717112334597,
0.996966839004107, 0.996393951145291), uci = c(1.02045365704779,
1.00345683050333, 1.0014827204373, 1.00001159824068, 1.26034930530902,
1.03891330635438, 1.02143638459725, 1.00910019120188, 1.04389716670672,
1.02990443046443, 1.02659764746465, 1.02607087773444), estimates = c("1.002 (0.984 - 1.020)",
"0.985 (0.967 - 1.003)", "0.983 (0.966 - 1.001)", "0.982 (0.964 - 1.000)",
"1.052 (0.878 - 1.260)", "0.866 (0.723 - 1.039)", "0.852 (0.711 - 1.021)",
"0.843 (0.704 - 1.009)", "1.029 (1.014 - 1.044)", "1.015 (1.000 - 1.030)",
"1.012 (0.997 - 1.027)", "1.011 (0.996 - 1.026)")), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -12L))
到目前為止,我已經嘗試過這個
df %>%
ggplot(aes(x=mean, y= interaction(`Unit Increase`,Exposure, sep = "&"), colour=Models))
scale_color_brewer(palette="Set1",
breaks=c("Model 1","Model 2","Model 3", "Model 4"))
geom_vline(xintercept = 1)
geom_point(position = position_dodge(width=.75))
geom_errorbarh(aes(xmin = lci, xmax=uci), position=position_dodge(width=.75), height=0)
labs(x="Odds Ratio", y="Exposures (Unit of Increase)", colour="Models")
guides(
y = guide_axis_nested(delim = "&", n.dodge = 1))
theme(
axis.text.y.left = element_text(margin = margin(r = 5, l = 5)),
ggh4x.axis.nesttext.y = element_text(margin = margin(r = 6, l = 6)),
ggh4x.axis.nestline = element_blank())
theme_classic()
并得到了這個結果(沒有第二個軸)
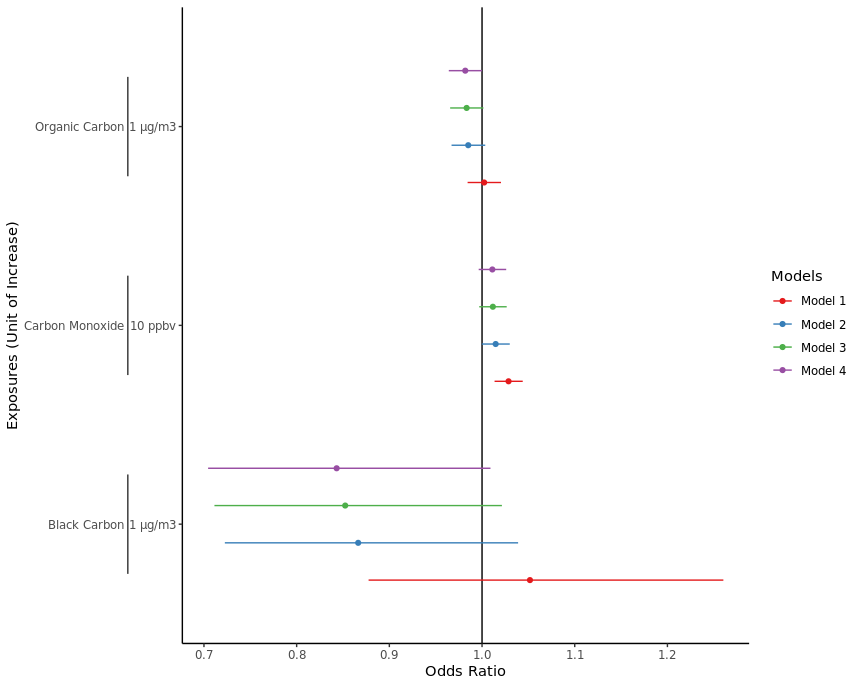
uj5u.com熱心網友回復:
離散比例不支持輔助軸,請參閱問題。也就是說,您可以使用ggh4x::guide_axis_manual(). 但是,確切的休息時間應該是有點痛苦(我被騙了layer_data())。
library(ggplot2)
library(ggh4x)
# df <- structure(...) # omitted for brevity
ggplot(df, aes(x=mean, y = interaction(`Unit Increase`, Exposure, sep = "&"),
colour=Models))
scale_color_brewer(palette="Set1",
breaks=c("Model 1","Model 2","Model 3", "Model 4"))
geom_vline(xintercept = 1)
geom_point(position = position_dodge(width=.75))
geom_errorbarh(aes(xmin = lci, xmax=uci), position=position_dodge(width=.75), height=0)
labs(x="Odds Ratio", y="Exposures (Unit of Increase)", colour="Models")
guides(
y = guide_axis_nested(delim = "&", n.dodge = 1),
y.sec = guide_axis_manual(
breaks = as.vector(outer(c(-0.28125, -0.09375, 0.09375, 0.28125), 1:3, " ")),
labels = df$estimates
)
)
theme_classic()
theme(
axis.text.y.left = element_text(margin = margin(r = 5, l = 5)),
ggh4x.axis.nesttext.y = element_text(margin = margin(r = 6, l = 6)),
ggh4x.axis.nestline.y = element_blank())
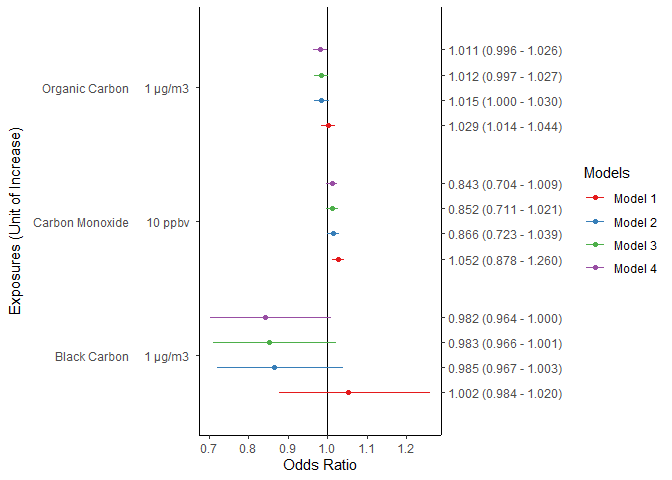
由reprex 包(v2.0.1)創建于 2022-05-16
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/476652.html
上一篇:在每個欄的頂部添加總計
下一篇:在ggplot2/stat_summary中,如何將`median`值作為標簽添加到繪圖(如geom_text())