我有大約 100 萬個名字和姓氏的資料點。這些名稱可能是有效的,例如:“大衛貝克漢姆”或無效的名稱 - “rockstar123”或“新突變體”。是否有任何深度學習/ML 模型可以讓我區分這兩者?
uj5u.com熱心網友回復:
選項 1:使用任何預訓練的命名物體識別 (NER) 模型。
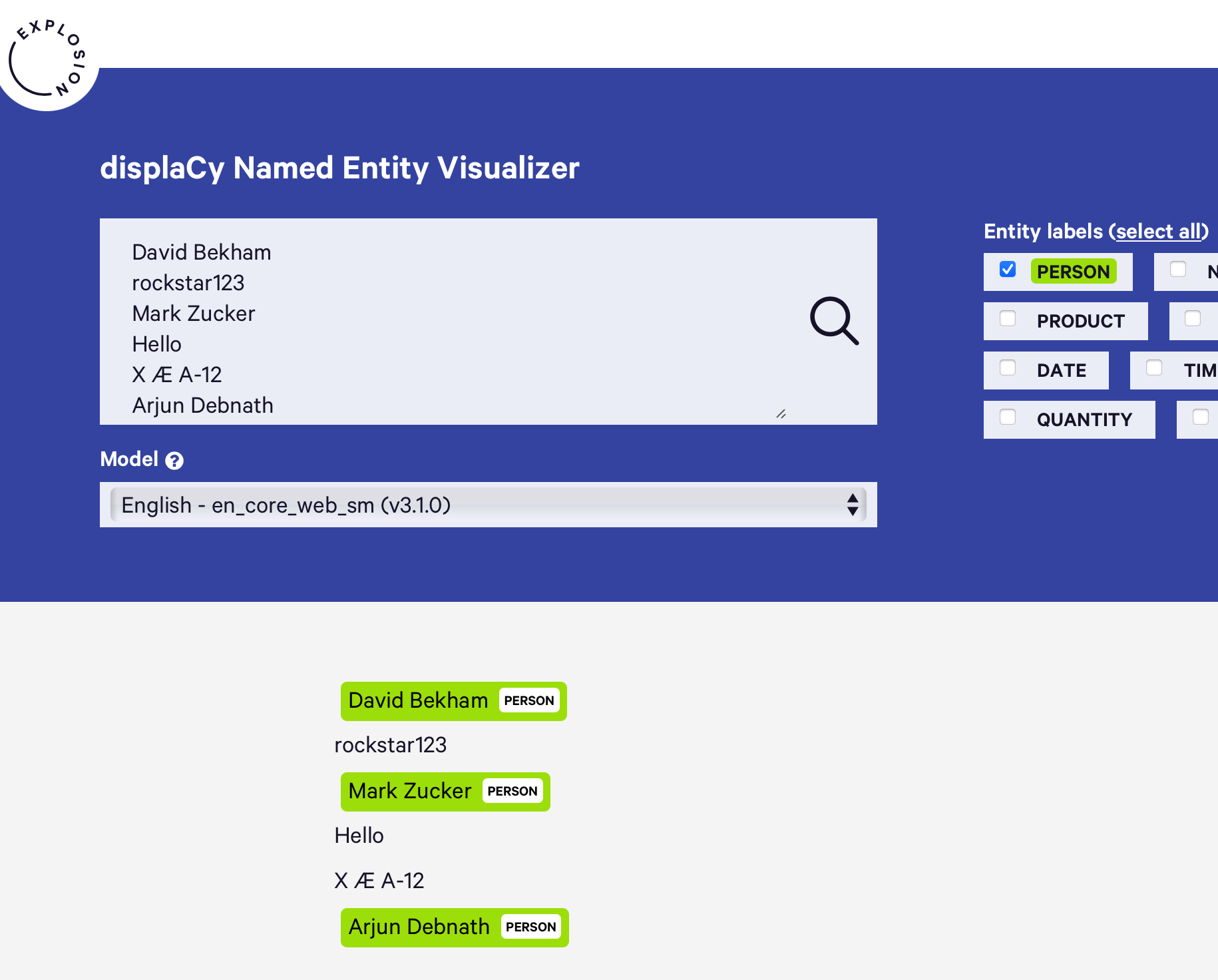
選項 2:訓練您的自定義 NER 模型。在底層,不同的 NER 模型使用不同的嵌入(GloVe、基于 Transformer 等)。一旦確定了任務的嵌入,任何二元分類模型都可以輸出概率(例如,樸素貝葉斯、邏輯回歸、SVM、神經網路)。
選項 3:不要使用機器學習。對于這個簡單的任務,我傾向于 regex/ rule-matching。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/481170.html