我有一個 CSV 資料,如下所示:
time_value,annual_salary
5/01/19 01:02:16,120.56
06/01/19 2:02:17,12800
7/01/19 03:02:18,123.00
08/01/19 4:02:19,123isdhad
我只想考慮numeric values十進制值。基本上,我想忽略最后一條記錄,因為它是字母數字的,annual_salary并且我能夠這樣做。但是,當我嘗試將其轉換為正確的十進制值時,它給了我不正確的結果。下面是我的代碼:
df = df.withColumn("annual_salary", regexp_replace(col("annual_salary"), "\.", ""))
df = df.filter(~col("annual_salary").rlike("[^0-9]"))
df.show(truncate=False)
df.withColumn("annual_salary", col("annual_salary").cast("double")).show(truncate=False)
但它給了我如下記錄:
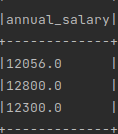
這是不正確的。
Expected output:
annual_salary
120.56
12800.00
123.00
這里有什么問題?我是否需要為這種型別的轉換實施 UDF?
uj5u.com熱心網友回復:
請嘗試強制轉換十進制型別。
df.where(~col('annual_salary').rlike('[A-Za-z]')).withColumn('annual_salary', col('annual_salary').cast(DecimalType(38,2))).show()
---------------- -------------
| time_value|annual_salary|
---------------- -------------
|5/01/19 01:02:16| 120.56|
|06/01/19 2:02:17| 12800.00|
|7/01/19 03:02:18| 123.00|
---------------- -------------
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/483120.html