假設我有以下 DataFame:
df = pd.DataFrame(
{
'id':[112, 130, 200],
'name':['Lara', 'Kasia', 'Rocco'],
'level/income':[{1:400, 2:800}, {1:100}, {1:1000, 2:2000, 3:5000}]
}
)

我希望這是最終結果:
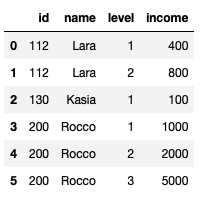
我試圖自己做這件事,但我失敗了。我試圖通過查找哪個id和name會出現多次來重新創建原始 DataFrame,但這證明太多了。
len_need = []
id2 = []
name2 = []
level2 = []
income2 = []
for index,row in df.iterrows():
len_need.append(len(row['level/income']))
我確信有更好的方法來做到這一點。
uj5u.com熱心網友回復:
嘗試這個:
(df.set_index(['id', 'name'])
.squeeze()
.apply(pd.Series)
.rename_axis('level', axis=1)
.stack()
.reset_index(name='income'))
>>>
id name level income
0 112 Lara 1 400.0
1 112 Lara 2 800.0
2 130 Kasia 1 100.0
3 200 Rocco 1 1000.0
4 200 Rocco 2 2000.0
5 200 Rocco 3 5000.0
uj5u.com熱心網友回復:
變體使用json_normalize:
from pandas import DataFrame, json_normalize
df = DataFrame(
{
"id": [112, 130, 200],
"name": ["Lara", "Kasia", "Rocco"],
"level/income": [{1: 400, 2: 800}, {1: 100}, {1: 1000, 2: 2000, 3: 5000}],
}
)
income_cols = list(range(1, 3 1))
id_cols = ["id", "name"]
final = (
df["level/income"]
.pipe(json_normalize)
.assign(id=df["id"], name=df["name"])
.melt(
id_vars=id_cols, value_vars=income_cols, var_name="level", value_name="income"
)
.dropna()
)
print(final)
# id name level income
# 0 112 Lara 0 400.0
# 1 130 Kasia 0 100.0
# 2 200 Rocco 0 1000.0
# 3 112 Lara 1 800.0
# 5 200 Rocco 1 2000.0
# 8 200 Rocco 2 5000.0
uj5u.com熱心網友回復:
我會提取該level/income列,將其分解,然后重新加入:
# this remove the `level/income` column from the dataframe
s = df.pop('level/income')
df.join(pd.DataFrame(s.tolist(), index=s.index)
.rename_axis(columns='level')
.stack()
.reset_index(level='level', name='income')
)
輸出:
id name level income
0 112 Lara 1 400.0
0 112 Lara 2 800.0
1 130 Kasia 1 100.0
2 200 Rocco 1 1000.0
2 200 Rocco 2 2000.0
2 200 Rocco 3 5000.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/490936.html