所以我試圖從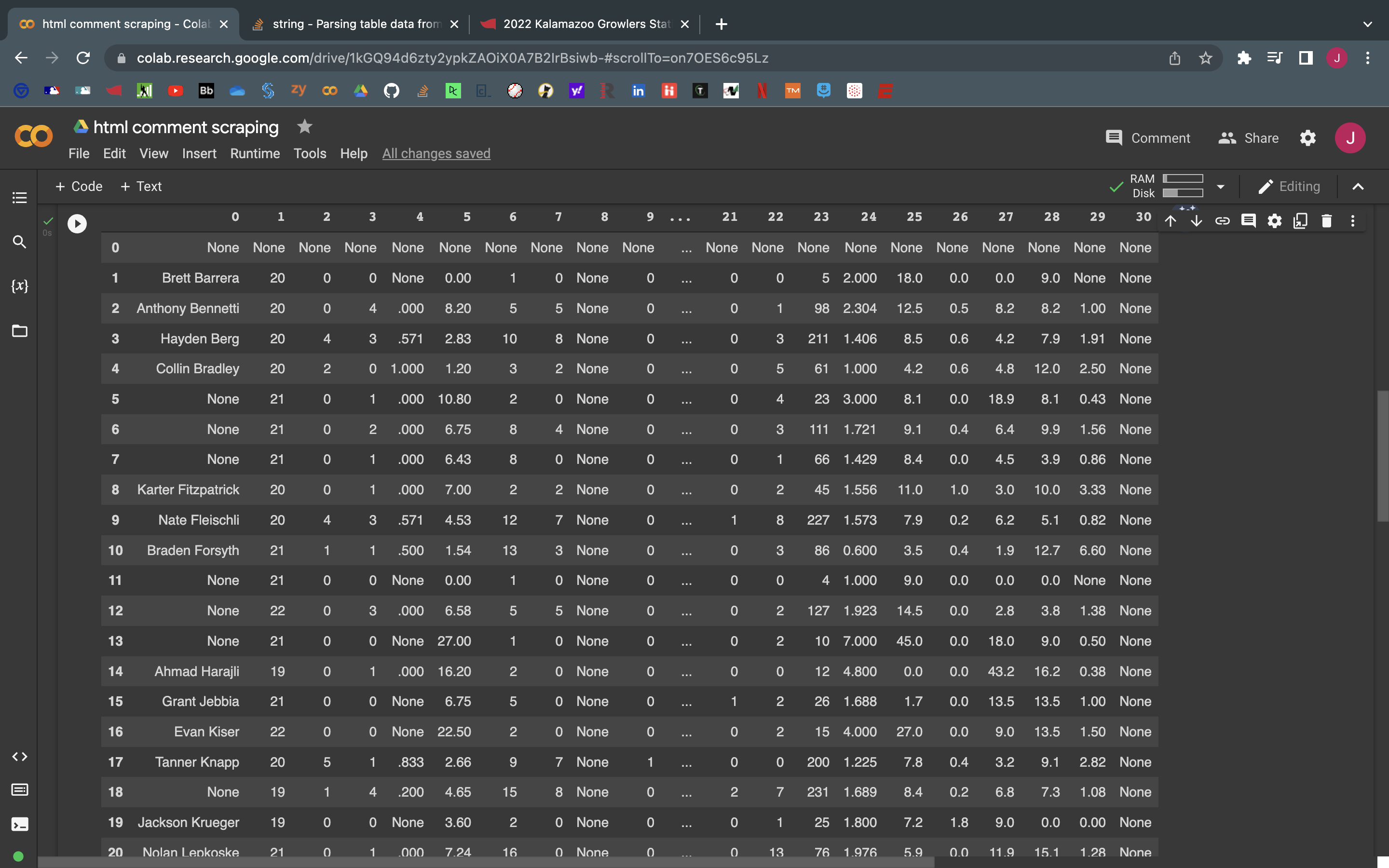
任何幫助都會得到幫助!
uj5u.com熱心網友回復:
需要的表格資料在html注釋中,可以呼叫beautifulsoup自帶的Comment帶有lambda函式的包來抓取資料。
import pandas as pd
import requests
from bs4 import BeautifulSoup
from bs4 import Comment
url='https://www.baseball-reference.com/register/team.cgi?id=9995d2a1'
req=requests.get(url)
soup=BeautifulSoup(req.text,'lxml')
df = pd.read_html([x for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_team_pitching"' in x][0])[0]
print(df)
輸出:
Rk Name Age W L W-L% ... H9 HR9 BB9 SO9 SO/W Notes
0 1.0 Logan Bursick-Harrington 21.0 0 2 0.000 ... 4.5 0.0 15.8 15.8 1.00 NaN
1 2.0 Cylis Cox* 19.0 1 0 1.000 ... 23.1 0.0 7.7 11.6 1.50 NaN
2 3.0 Travis Densmore* 21.0 0 1 0.000 ... 7.2 0.0 1.8 14.4 8.00 NaN
3 4.0 Dylan Freeman 22.0 1 0 1.000 ... 13.5 1.1 3.4 14.6 4.33 NaN
4 5.0 Zach Hopman* 22.0 0 1 0.000 ... 12.8 0.0 9.9 11.4 1.14 NaN
5 6.0 Eamon Horwedel 22.0 1 0 1.000 ... 9.0 0.0 6.4 6.4 1.00 NaN
6 7.0 Tyler Johnson 19.0 0 0 NaN ... 5.4 0.0 2.7 10.8 4.00 NaN
7 8.0 Trent Jones 20.0 0 0 NaN ... 14.6 1.1 2.3 12.4 5.50 NaN
8 9.0 Tanner Knapp 21.0 1 1 0.500 ... 11.6 0.0 7.7 4.8 0.63 NaN
9 10.0 Mason Majors 22.0 1 0 1.000 ... 4.9 0.0 7.4 12.3 1.67 NaN
10 11.0 Mason Meeks 21.0 0 1 0.000 ... 6.3 0.9 3.6 5.4 1.50 NaN
11 12.0 Sam Nagelvoort 19.0 0 1 0.000 ... 18.0 2.3 22.5 9.0 0.40 NaN
12 13.0 Tyler Nichol 20.0 0 0 NaN ... 27.0 0.0 27.0 0.0 0.00 NaN
13 14.0 Cole Russo 19.0 0 0 NaN ... 27.0 13.5 0.0 0.0 NaN NaN
14 15.0 Kyle Salley* 22.0 0 1 0.000 ... 9.0 2.3 22.5 9.0 0.40 NaN
15 16.0 Noah Stants 21.0 0 0 NaN ... 4.3 1.4 7.1 11.4 1.60 NaN
16 17.0 Quinn Waterhouse* 21.0 0 0 NaN ... 4.5 0.0 4.5 18.0 4.00 NaN
17 18.0 Nick Weyrich 19.0 0 0 NaN ... 6.4 1.3 7.7 11.6 1.50 NaN
18 19.0 Adam Wheaton 23.0 0 1 0.000 ... 11.7 1.8 4.5 12.6 2.80 NaN
19 NaN 19 Players 20.9 5 9 0.357 ... 9.2 0.8 6.9 10.7 1.55 NaN
[20 rows x 32 columns]
uj5u.com熱心網友回復:
所以要做到這一點,你需要改變:
def parse_row(row):
return [str(x.string) for x in row.find_all('td')]
至
def parse_row(row):
return [str(x.text) for x in row.find_all('td')]
你得到的原因None是因為'*'它不是<a>標簽的一部分,所以基本上元素中有2個內容<td>。如果您使用.text它將加入他們。
這樣就處理了第一個問題None。洗掉的第二個問題*:我不確定您是否真的希望將其從 html 中洗掉,或者只是在您創建的資料框中洗掉,所以我將向您展示兩者。
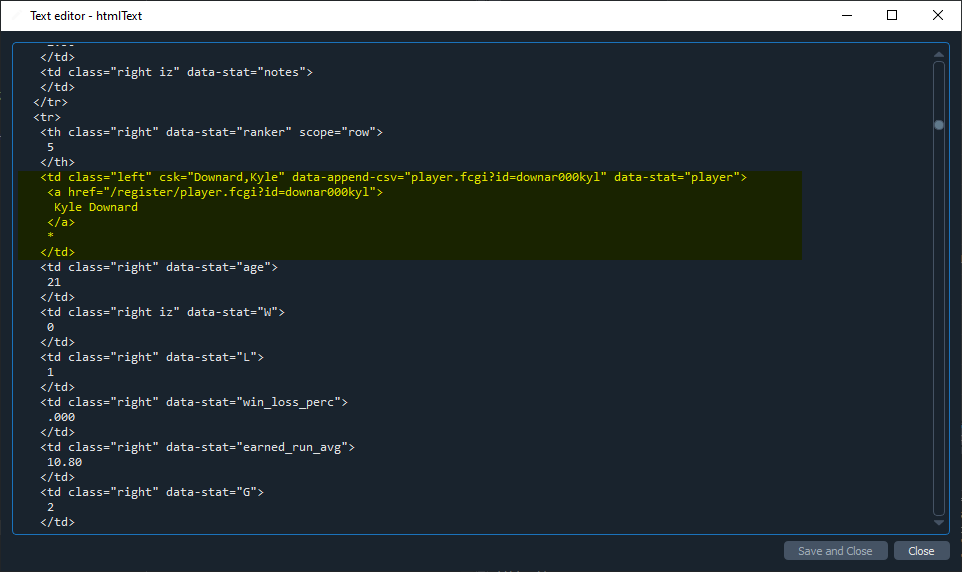
要更改實際的 html:
這里我們只是從串列中洗掉'*'元素。<td> .contents這將改變實際的湯物件,改變 html。這也將導致您的資料框也沒有顯示。
之前的 HTML:
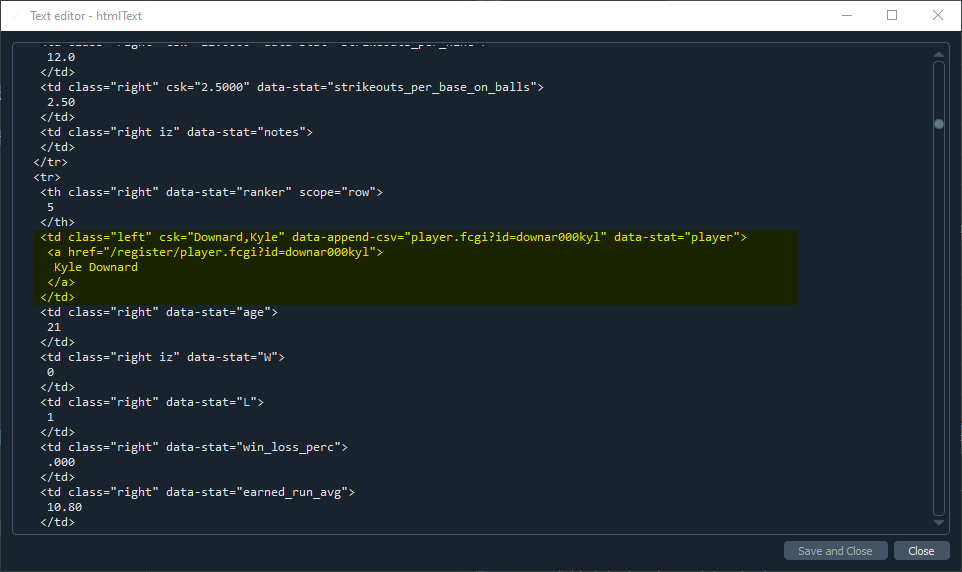
HTML After - 注意'*'不再出現在實際的 html 中:
現在,如果您對更改 html 不感興趣,而只是抓取資料并使用 pandas 進行操作(注意:就像 F.Hoque 所做的那樣,我會讓pandas'.read_html()為您決議表格,因為它也會抓取標題,但這仍然適用于您的代碼。無論哪種方式,一旦您擁有data或在其他解決方案中,這將是最后一步df。對于他,您會這樣做df['Name'] = df['Name'].str.replace('*','', regex=True)):
import requests
from bs4 import BeautifulSoup, Comment
import pandas as pd
page = BeautifulSoup(requests.get('https://www.baseball-reference.com/register/team.cgi?id=b0a9f9bc').text, features = 'lxml')
tbls = []
for comment in page.find_all(text=lambda text: isinstance(text, Comment)):
if comment.find("<table ") > 0:
comment_soup = BeautifulSoup(comment, 'lxml')
table = comment_soup.find("table")
tbls.append(table)
def parse_row(row):
return [str(x.text) for x in row.find_all('td')]
# pitching table
pitching_tbl = tbls[0]
# html text only used for finding names
html = BeautifulSoup(pitching_tbl.text, features = 'lxml')
rows = pitching_tbl.find_all('tr')
data = pd.DataFrame([parse_row(row) for row in rows])
data[0] = data[0].str.replace('*','', regex=True)
**使用 F.Hoque 的解決方案,我就是這樣做的。然后,這可能是一個不錯的額外列添加,所以如果它在那里,為什么不添加它?:
import pandas as pd
import requests
from bs4 import BeautifulSoup, Comment
import numpy as np
url='https://www.baseball-reference.com/register/team.cgi?id=9995d2a1'
req=requests.get(url)
soup=BeautifulSoup(req.text,'lxml')
df = pd.read_html([x for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_team_pitching"' in x][0])[0]
df['Handedness'] = np.where(df['Name'].str.contains('\*'), 'L', 'R')
df['Name'] = df['Name'].str.replace('*','', regex=True)
print(df)
輸出:
Rk Name Age W ... SO9 SO/W Notes Handedness
0 1.0 Logan Bursick-Harrington 21.0 0 ... 15.8 1.00 NaN R
1 2.0 Cylis Cox 19.0 1 ... 11.6 1.50 NaN L
2 3.0 Travis Densmore 21.0 0 ... 14.4 8.00 NaN L
3 4.0 Dylan Freeman 22.0 1 ... 14.6 4.33 NaN R
4 5.0 Zach Hopman 22.0 0 ... 11.4 1.14 NaN L
5 6.0 Eamon Horwedel 22.0 1 ... 6.4 1.00 NaN R
6 7.0 Tyler Johnson 19.0 0 ... 10.8 4.00 NaN R
7 8.0 Trent Jones 20.0 0 ... 12.4 5.50 NaN R
8 9.0 Tanner Knapp 21.0 1 ... 4.8 0.63 NaN R
9 10.0 Mason Majors 22.0 1 ... 12.3 1.67 NaN R
10 11.0 Mason Meeks 21.0 0 ... 5.4 1.50 NaN R
11 12.0 Sam Nagelvoort 19.0 0 ... 9.0 0.40 NaN R
12 13.0 Tyler Nichol 20.0 0 ... 0.0 0.00 NaN R
13 14.0 Cole Russo 19.0 0 ... 0.0 NaN NaN R
14 15.0 Kyle Salley 22.0 0 ... 9.0 0.40 NaN L
15 16.0 Noah Stants 21.0 0 ... 11.4 1.60 NaN R
16 17.0 Quinn Waterhouse 21.0 0 ... 18.0 4.00 NaN L
17 18.0 Nick Weyrich 19.0 0 ... 11.6 1.50 NaN R
18 19.0 Adam Wheaton 23.0 0 ... 12.6 2.80 NaN R
19 NaN 19 Players 20.9 5 ... 10.7 1.55 NaN R
[20 rows x 33 columns]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/492299.html