我有一個類似于下面的資料框:
| 案例ID | D1 | D2 | D3 | D4 |
|---|---|---|---|---|
| 一個 | 2022 年 12 月 | 2023 年 2 月 | 2023 年 5 月 | 2024 年 6 月 |
| 乙 | 2020 年 7 月 | 2023 年 5 月 | 2024 年 8 月 | |
| C | 2019 年 5 月 | 2020 年 7 月 | 2021 年 12 月 | |
| 丁 | 2020 年 7 月 | 2021 年 3 月 | 2021 年 4 月 | 2024 年 8 月 |
| 乙 | 2019 年 5 月 | 2023 年 5 月 | 2024 年 8 月 | |
| F | 2022 年 12 月 | 2023 年 2 月 | 2023 年 5 月 | 2024 年 8 月 |
| G | 2022 年 12 月 | 2023 年 2 月 | 2023 年 5 月 | 2024 年 8 月 |
我想要一個資料框,其中包含所有日期(從上述資料框的最小(日期)到最大(日期))作為索引,然后是給定日期有截止日期(即 Dx)的案例數。所以,在視覺上我期待類似于下面的東西:
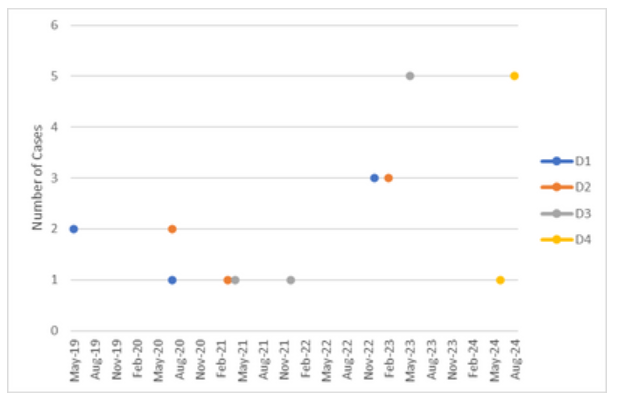
謝謝
uj5u.com熱心網友回復:
我終于找到了解決方案,不確定這是否是最直接的方法,但我認為它可行。
# reshape data from wide to long and add a column "has_deadline" as marker.
df1 = df.set_index('Case ID').stack().reset_index(name='dates').rename(columns={'level_1': 'deadlines'})
df1['has_deadline'] = 1
# we need to create a new index which includes every single combination for each Case, deadline and date
# Then reindex the dataframe (missing values will be filled with NaN)
df1 = df1.set_index(['deadlines', 'dates', 'Case ID'])
new_idx = pd.MultiIndex.from_product(df1.index.levels)
df1 = df1.reindex(new_idx)
# Now we need to sum each row to get the sum of all cases for each deadline and date
# also sort the index chronological
df1 = df1.unstack(level=2).sum(axis=1).unstack('deadlines').sort_index(key=lambda x: pd.to_datetime(x, format="%b %Y"))
print(df1)
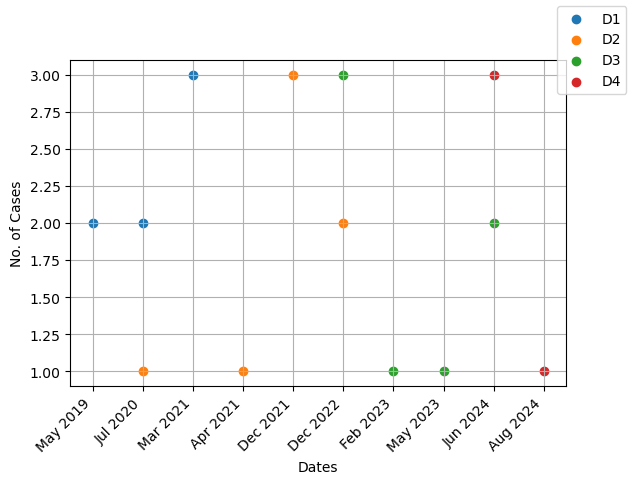
輸出df1:
deadlines D1 D2 D3 D4
dates
May 2019 2.0 0.0 0.0 0.0
Jul 2020 2.0 1.0 0.0 0.0
Mar 2021 0.0 1.0 0.0 0.0
Apr 2021 0.0 0.0 1.0 0.0
Dec 2021 0.0 0.0 1.0 0.0
Dec 2022 3.0 0.0 0.0 0.0
Feb 2023 0.0 3.0 0.0 0.0
May 2023 0.0 2.0 3.0 0.0
Jun 2024 0.0 0.0 0.0 1.0
Aug 2024 0.0 0.0 2.0 3.0
陰謀:
# plot each column
for col in df1.columns:
tmp = df1.loc[df1[col].ne(0), col]
plt.scatter(x=tmp.index, y=tmp, label=col)
plt.xticks(rotation=90)
plt.xlabel('Dates')
plt.ylabel('No. of Cases')
plt.grid(True)
plt.legend()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/533674.html