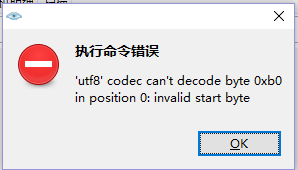
 掃描時出現錯誤,不會解決,求大神指點
掃描時出現錯誤,不會解決,求大神指點
uj5u.com熱心網友回復:
// UTF-8 編碼字符理論上可以最多到 6個位元組長,但目前全世界的所
// 有文字和符號種類加起來也只要編到 4個位元組長就夠了。
// UTF-8 是以 8位(即 1個位元組)為單元對原始碼進行編碼(注意一
// 點:這里所講的原始碼都是指Unicode碼),并規定:多位元組碼(2個字
// 節以上才稱為多位元組)以轉換后第1個位元組起頭的連續“1”的數目(這
// 些連續“1”稱為標記位),表示轉換成幾個位元組:“110”連續兩個
// “1”,表示轉換結果為2個位元組,“1110”表示3個位元組,而“11110”
// 則表示4個位元組……跟隨在標記位之后的“0”,其作用是分隔標記位和
// 字符碼位。第2~第4個位元組的起頭兩個位固定設定為“10”,也作為標
// 記,剩下的6個位才做為字符碼位使用。
// 這樣,2位元組UTF-8碼剩下11個字符碼位,可用以轉換0080~07FF的
// 原始字符碼,3位元組剩下16個字符碼位,可用以轉換0800~FFFF的原始字
// 符碼,由此類推。編碼方式的模板如下:
//
// 原始碼(16進制) UTF-8編碼(二進制)
// --------------------------------------------
// 0000 - 007F 0xxxxxxx
// 0080 - 07FF 110xxxxx 10xxxxxx
// 0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
// ……
// --------------------------------------------
//
// 模板中的“x”表示字符碼。
// Ascii碼<007F,編為1個
// 位元組的UTF-8碼。漢字的 Unicode編碼范圍為0800-FFFF,所以被編為
// 3個位元組的UTF-8碼。
// 例如“漢”字的Unicode編碼是6C49,6C49在0800-FFFF之間,所以
// 要用3個位元組的模板:1110wwww 10xxxxyy 10yyzzzz。
// 6 C 4 9
// 0110 1100 0100 1001
// wwww xxxx yyyy zzzz
// wwww xxxxyy yyzzzz
// 1110wwww 10xxxxyy 10yyzzzz。
// 11100110 10110001 10001001
// E 6 B 1 8 9
//“漢”字的UTF-8編碼是E6 B1 89
uj5u.com熱心網友回復:
有沒有解決,我也出現了這個問題
uj5u.com熱心網友回復:
最新7.8版本號稱解決了這個BUG,我安裝后一樣出現這個問題。我在win7的系統下就沒這個問題,不知道是不是win10的原因。uj5u.com熱心網友回復:
謝謝
uj5u.com熱心網友回復:
可能的錯誤原因:當前電腦用戶為中文用戶會出現這種情況,提供一個部分解決方案吧:https://blog.csdn.net/l870358133/article/details/105172626uj5u.com熱心網友回復:
這個已經找到問題了,安裝的用戶不能是中文轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/25476.html
標籤:一般軟件使用