前言
在學習C語言時,我們接觸過如fopen、fclose、fseek、fgets、fputs、fread、fwrite等函式,實際上,這些函式是對于底層系統呼叫的封裝,C默認會打開三個輸入輸出流,分別是stdin,stdout,stderr,執行man stdin后,會展示如下描述:
#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;
可以看到,這三個流型別都是FILE*,也就是說指向了某個檔案,實際上,以上三者分別對應的檔案為鍵盤、顯示幕、顯示幕,
那么,作業系統是如何管理檔案,并進行檔案IO呢?
1. 檔案描述符及基本IO介面介紹
1.1 什么是檔案描述符
在第一講中,我們知道了當行程被創建后,系統會給該行程分配對應的PCB,在Linux中,行程的PCB是task_stuct,里面有一項files_struct——打開檔案表,打開檔案表的原始碼如下:
struct files_struct {
atomic_t count; /* 共享該表的行程數 */
rwlock_t file_lock; /* 保護以下的所有域,以免在tsk->alloc_lock中的嵌套*/
int max_fds; /*當前檔案物件的最大數*/
int max_fdset; /*當前檔案描述符的最大數*/
int next_fd; /*已分配的檔案描述符加1*/
struct file ** fd; /* 指向檔案物件指標陣列的指標 */
fd_set *close_on_exec; /*指向執行exec( )時需要關閉的檔案描述符*/
fd_set *open_fds; /*指向打開檔案描述符的指標*/
fd_set close_on_exec_init;/* 執行exec( )時需要關閉的檔案描述符的初值集合*/
fd_set open_fds_init; /*檔案描述符的初值集合*/
struct file * fd_array[32];/* 檔案物件指標的初始化陣列*/
};
行程是通過檔案描述符(file descriptors,簡稱fd)而不是檔案名來訪問檔案的,檔案描述符是一個整數,
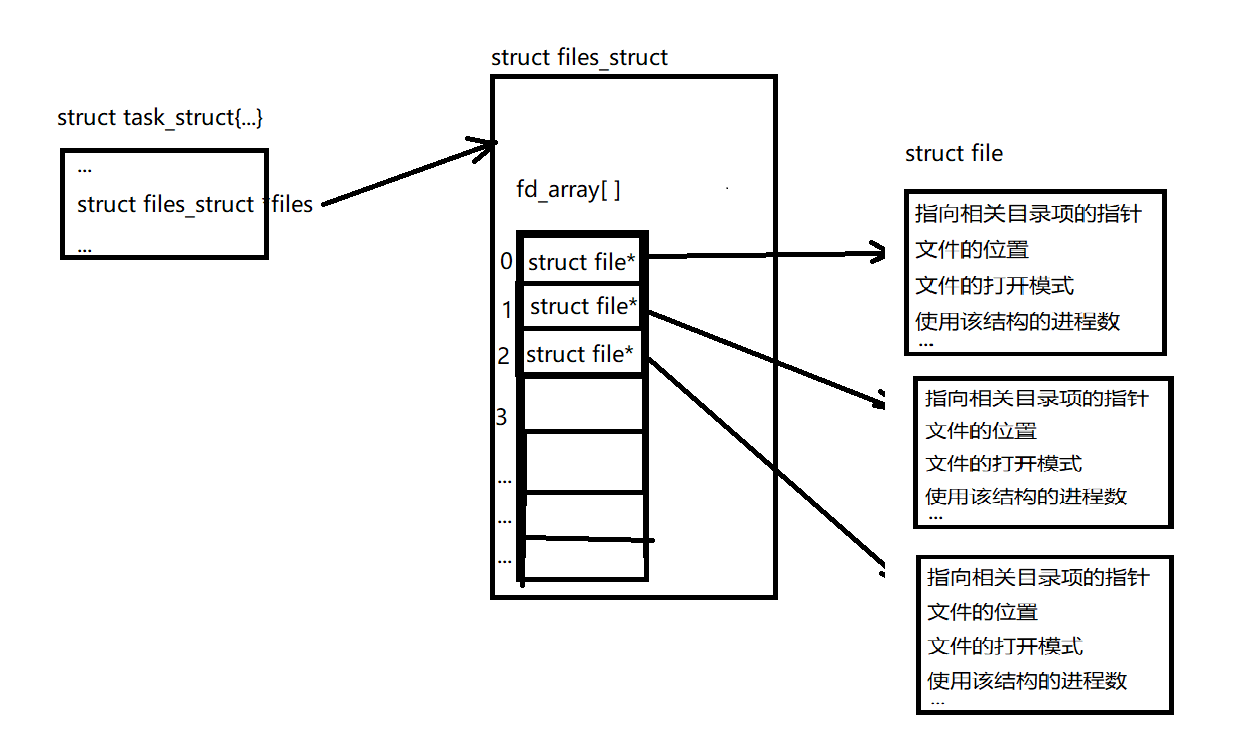
在打開檔案表中,最重要的一項是fd_array[32],這是一個指標陣列,通常,fd_array包括32個檔案物件指標,如果行程打開的檔案數目多于32,內核就分配一個新的、更大的檔案指標陣列,并將其地址存放在fd域中,內核同時也更新max_fds域的值,
每當打開一個檔案時,系統就會分配fd_array中的某項,將其指向打開的檔案結構體,從下圖我們可以看出,fd實際上就是fd_array的索引,只要有fd,就可以找到對應檔案的位置,
1.2 基本IO介面
在認識回傳值之前,需要先區分兩個概念: 系統呼叫和庫函式, 在用戶程式中,凡是與資源有關的操作(如存盤分配、進行I/O傳輸及管理檔案等),都通過系統呼叫方式向作業系統提出服務請求,并由作業系統代為完成,在執行系統 呼叫的程序中,作業系統會由用戶態進入到內核態,系統為了防止應用程式能隨意修改系統資料,只給用戶提供介面,用戶要使用,那就通過提供的介面來呼叫,
fopen、fclose、fread、fwrite 都是C標準庫當中的函式,我們稱之為庫函式(libc),而open close read write lseek 都屬于系統提供的介面,稱之為系統呼叫介面,實際上,庫函式往往是對系統呼叫介面的進一步封裝,方便程式員進行二次開發,
1.2.1 open/close介面
函式原型:
頭檔案:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
介面1:int open(const char *pathname, int flags); :
介面2:int open(const char *pathname, int flags, mode_t mode);
介面3:int close(int fd);
如果打開的檔案存在,則使用介面1,如果打開的檔案不存在,則使用介面2,
pathname:待打開或創建的檔案
flags:以何種方式打開,打開檔案時,可以傳入多個常量進行“或”運算,這些常量有:
? 0_RDONLY:只讀打開;O_WRONLY:只寫打開;O_RDWR:讀寫打開,這三個常量,必須指定且只能指定一個,
? O_CREAT:若檔案不存在,則創建該檔案,需要使用mode選項,來指明新檔案的訪問權限,
? O_APPEND:追加寫入,
? O_TRUNC:截斷檔案(清空檔案內容)
? O_NONBLOCK :使用非阻塞方式讀寫設備檔案,如果不添加,默認情況下讀寫為阻塞方式,
以上的選項是按照按位或的方式進行組合的,O_RDWR|O_CREAT|O_APPEND 意思是以讀寫的方式打開檔案,如果檔案不存在則創建檔案,打開檔案后寫入方式為追加寫入,
mode:當創建一個新檔案時,需要給檔案設定權限,一般通過傳遞一個8進制的數字,關于檔案權限,請讀者自行查閱相關文章,
回傳值:
? 創建成功回傳一個檔案描述符
? 創建失敗回傳-1,
1.2.2 read/wirte介面
ssize_t read(int fd, void *buf, size_t count);
fd:檔案描述符
buf:將檔案讀到buf指向的空間中
count:期望讀取的位元組數
ssize_t write(int fd, const void *buf, size_t count)
fd:檔案描述符
buf:將buf中的內容寫到檔案當中去
count:期望寫入的位元組數,size_t被定義為unsigned long,
回傳值:回傳讀出或者寫入的位元組數,需要注意的是read和write的回傳值都是有符號數,ssize_t被定義為long,出錯的時候回傳-1,有趣的是回傳一個-1的可能性使得讀到或者寫入的最大值減小了一半,
通過下例來感受一下上面幾個介面的使用:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
char buff[1024];
int main()
{
int fd = open("wrfile",O_RDWR|O_CREAT|O_APPEND,0644);
if(fd == -1)
{
return 1;
}
else{
const char* str = "Hello world\n";
strcpy(buff,str);
write(fd,buff,strlen(buff));
printf("%d\n",fd);
close(fd);
}
return 0;
}
執行該段代碼后,可以看到如下輸出結果
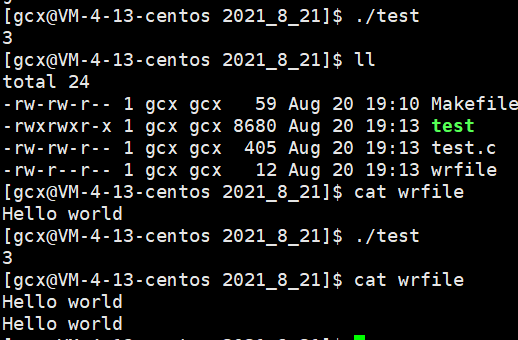
第一,打開檔案后,將回傳wrfile的fd,執行write函式,會將buff中的內容寫入到wrfile中,
第二,輸出wrfile的內容,發現如果只執行一次,輸出一行“Hello world”,如果執行兩次,輸出兩行“Hello world”,這是因為我們是以追加的方式打開的檔案,
第三,打開檔案后,回傳的fd號碼是3,為什么會是3?這就與檔案描述符的分配規則有關,
1.3 檔案描述符的分配規則
根據我們在1.1中知道的,fd是fd_array[ ]的索引,通常,陣列的第一個元素(索引為0)是行程的標準輸入檔案,陣列的第二個元素(索引為1)是行程的標準輸出檔案,陣列的第三個元素(索引為2)是行程的標準錯誤檔案,分別對應的鍵盤,顯示幕,顯示幕,在Linux中,萬物皆檔案,因此各種外設也會當做檔案進行處理,
是不是瞬間明白了為什么用戶自己打開第一個檔案的時候分配的fd是3而不是0?是的,這是因為對于任何行程,標準輸入檔案、標準輸出檔案和標準錯誤檔案會被默認打開,當再次分配的時候,作業系統會采用最小未分配原則——即先分配當前fd_array中未被使用的最小索引,
如果我們先關閉了fd為1的檔案,會是什么情況呢?請看下例:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(1);
int fd = open("./myfile",O_RDWR|O_CREAT,0644);
if(-1 == fd)
{
return -1;
}else{
printf("The fd is : %d\n",fd);
fflush(stdout);
close(fd);
}
return 0;
}
執行該段代碼后,結果如下:
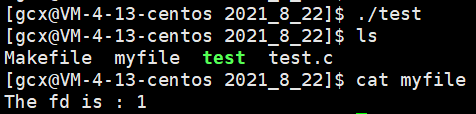
執行./test后,并沒有在螢屏上列印出結果,但是當我們查看myfile檔案中的內容時發現,原來是內容都輸出在了myfile檔案中,我們可以看到,打開myfile的fd為1,這是因為我們之前關閉了fd為1的檔案,當打開新的檔案時,系統會分配最小未使用的fd——1,
為什么執行printf后內容會輸出到myfile中而不是螢屏上,這就需要提到輸出重定向,
1.4 輸入重定向與輸出重定向的本質
1.4.1重定向的原理
printf是格式化輸出函式,當呼叫printf時,資料會被默認輸出到緩沖區中,當換行符或者緩沖區滿時,會將資料重繪到stdout中,stdout是標準輸出設備,其fd默認為1,
在上例中,關閉fd為1的檔案后,當打開新的檔案,會給其分配最小未使用的fd,此時執行printf函式,會將資料輸出到磁盤檔案myfile中,我們將這種現象稱為輸出重定向,常見的重定向有:>, >>, <,分別為輸出重定向,追加重定向,輸入重定向,重定向的原理如下圖所示:
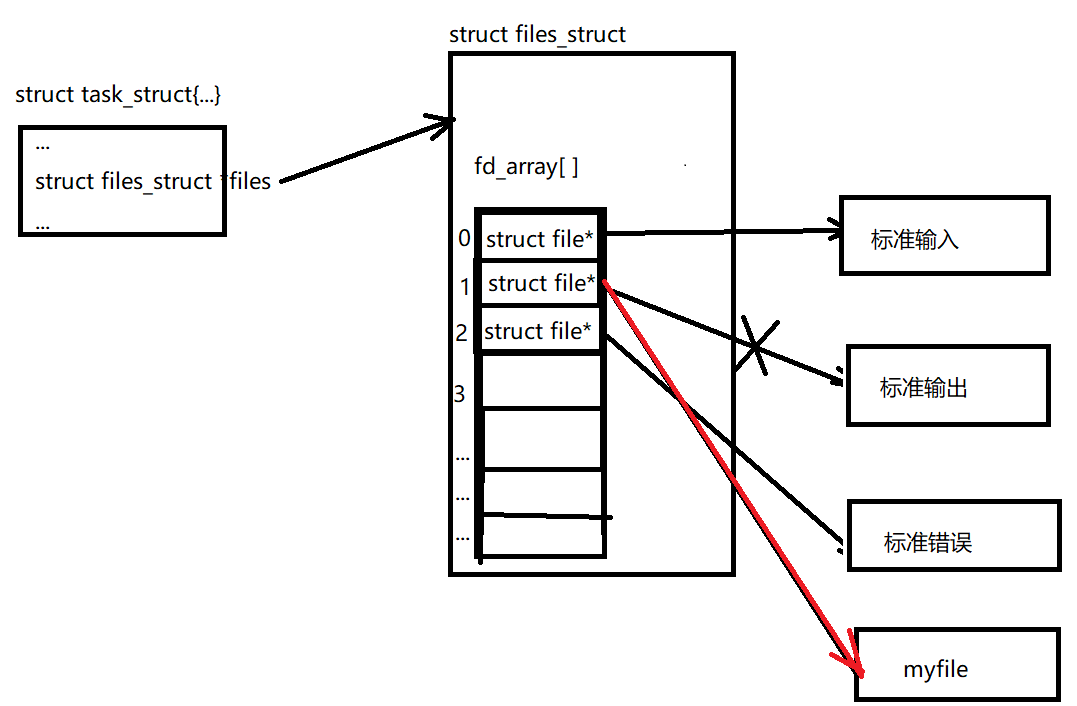
需要注意的是,我們在執行完printf后,使用了fflush函式來重繪緩沖區,如果不使用這個函式,當執行./test后,我們會發現資料并未輸出到myfile中,這就需要提到緩沖區,
在默認情況下,stdout是行緩沖的,他的輸出會放在一個buffer里面,只有到換行的時候,才會輸出到螢屏,stderro是無緩沖,會直接進行io操作,而平時使用的磁盤檔案是全緩沖(或稱滿緩沖)的,只有緩沖區滿的時候才會將緩沖區里面的內容重繪,當關閉stdout,打開myfile后,會變成全緩沖,因此需要我們執行fflush強制重繪緩沖區,緩沖區的型別如下:
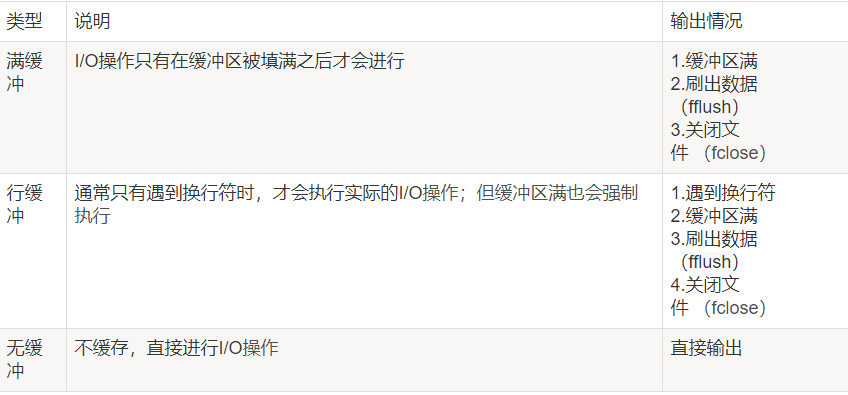
需要注意的是,這里的緩沖區指的是c程式中的用戶緩沖區,而不是內核緩沖區!
1.4.2 重定向在命令列的應用
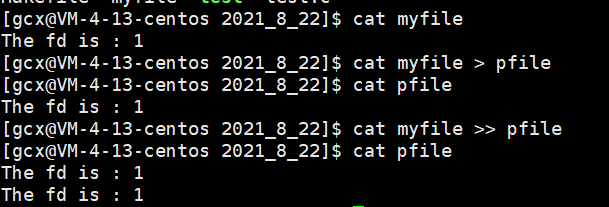
如下圖所示,當執行cat指令后,myfile中的內容會輸出到螢屏上,當我們再次執行cat myfile,并使用>進行輸出重定向后,可以看出myfile中的內容輸出到了pfile中,當使用>>后,會發現pfile中有兩行資料,這就是追加重定向,即再原來檔案的末尾繼續輸出,
1.4.3 dup2系統呼叫
如果我們想在IO時進行重定向操作,難道每次都需要先close一個檔案,再申請對應的fd嗎?這樣無疑增加了編碼的復雜程度,因此,如果想進行重定向操作,推薦使用dup2系統呼叫,
介面描述:
int dup2(int oldfd, int newfd);
該介面用來復制新的檔案描述符,通俗地說,fd_array[ ]中存放著指向若干打開的檔案結構體file,比如此時某個檔案的fd為3,我們想對這個檔案進行輸出重定向,讓本應該輸出到fd為3的檔案中的資料輸出到螢屏上,就可以通過呼叫dup2(3,1),原理是把fd為3的檔案結構體指標復制到fd為1的單元中,這樣3和1都指向了同一個檔案結構體,
示例如下:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("./myfile",O_RDWR|O_CREAT,0644);
if(-1 == fd)
{
return -1;
}else{
printf("Hello world!\n");
dup2(fd,1);
close(fd);
printf("The fd is : %d\n",fd);
fflush(stdout);
}
return 0;
}
輸出結果如下:
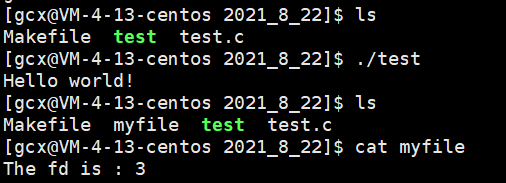
在程式中,有兩處printf函式,當執行./test后,螢屏上只列印出一行"Hello world!",而第二行的資料列印到了myfile中,我們明明已經對新打開的檔案執行了close(fd),為什么資料還是會列印到myfile中?
這是因為呼叫dup2的時候,將oldfd中的值復制到了newfd中,
注意:復制的是陣列下標為fd中存盤的指標值而不是fd本身!若newfd指向的檔案已經被打開,會先將其關閉,若newfd等于oldfd,就不關閉newfd,newfd和oldfd共同指向一份檔案,
1.5 fd與C庫中FILE的關系
C庫中的函式本質上是對系統呼叫的封裝,所以本質上,所有對于檔案的操作都是通過檔案描述符fd來實作的,那么,C庫的FILE中一定有對應檔案的fd!
2. 檔案系統
2.1 磁盤簡介
傳統的硬碟盤結構是像下面這個樣子的,它有一個或多個盤片,用于存盤資料,中間有一個主軸,所有的盤片都繞著這個主軸轉動,一個組合臂上面有多個磁頭臂,每個磁頭臂上面都有一個磁頭,負責讀寫資料,
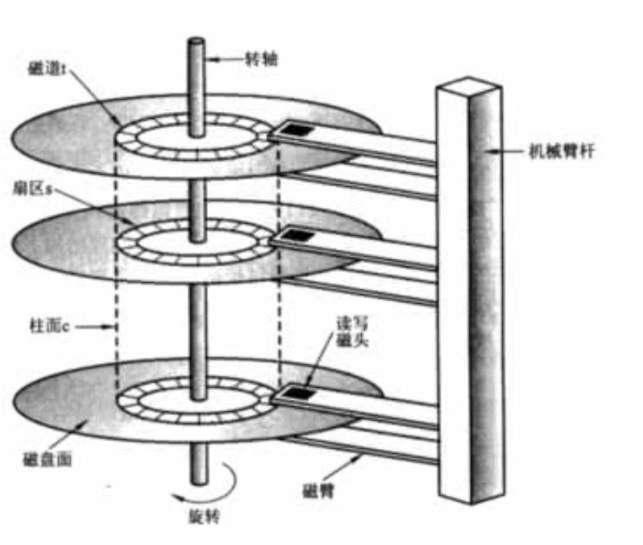
每個磁道劃分為若干個弧段,每個弧段就是一個扇區 (Sector),是硬碟的最小存盤單位,每個扇區儲存512位元組(相當于0.5KB),
作業系統讀取硬碟的時候,不會一個個扇區地讀取,因為這樣效率太低,而是一次性連續讀取多個扇區,即一次性讀取一個”塊”(block),這種由多個扇區組成的”塊”,是檔案存取的最小單位,”塊”的大小,最常見的是4KB,即連續八個sector組成一個block,一個block的大小是由格式化的時候確定的,并且不可以更改,
2.2 inode(索引結點)
輸入ls -l指令后,我們能看到如下內容

對于一個檔案而言,一個檔案= 檔案屬性+檔案內容,圖中所標識的部分就是檔案的各種屬性,那這些屬性是存盤在哪里?又是怎樣存盤的呢?檔案的資料又存放在哪里呢?
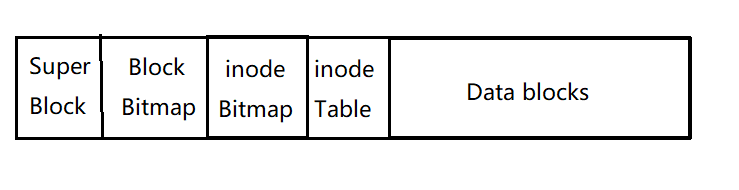
上圖是一個簡易的磁盤系統磁區圖,一般來說,在一個檔案系統內,一般將磁盤分為如下幾個區域:
超級塊:里面存放該檔案系統本身的結構資訊,如bolok 和 inode(馬上會講)的總量, 未使用的block和inode的數量,一個block和inode的大小等,
block位圖:先來看一下位圖的結構

block位圖有點像是一個超大型陣列,每個位元位所在位置可以看成陣列下標,而這個“下標”就是對應的block號,0代表該塊未分配,1代表該塊已經被分配,如在上圖中,表示9號塊已經分配,每分配一個block,要將對應位置的Bitmap置為1,
inode表:inode中存放的是一個檔案的元資訊,一般來說有以下資訊:
-
該檔案的inode號,用來標識一個inode,而每個inode對應一個檔案,Linux系統內部不使用檔案名,而使用inode號碼來識別檔案,對于系統來說,檔案名只是inode號碼便于識別的別稱或者綽號,
查看inode號碼的指令:
ls -i
-
檔案的位元組數
-
檔案擁有者的User ID ,所屬組的Group ID
-
檔案的讀、寫、執行權限
-
檔案的時間戳
-
鏈接數,即有多少檔案名指向這個inode 檔案資料block的位置
可以通過
stat指令查看對應檔案的inode資訊,如下圖所示:
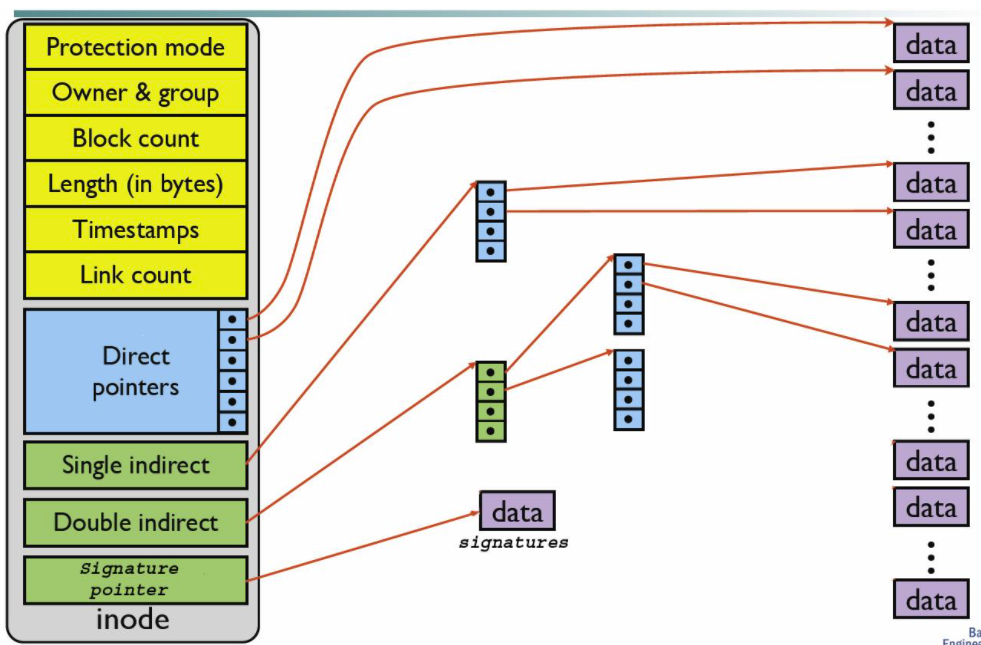
inode中還會為該檔案維護一個索引表,類似于記憶體管理中的頁表記錄了邏輯塊號到物理塊號之間的對應關系,索引表的目錄項中記錄的是每個檔案的索引塊地址,一般有直接索引,多層索引或混合索引等,
inode位圖:一個檔案系統能分配的inode數量是一定的,因此也可以用記錄block的方式來記錄inode的分配情況,原理與block Bitmap的原理一樣,inode Bitmap中的“下標”就是inode號,當分配了某個inode號時,將對應inode Bitmap位元位置為1,
2.3 目錄檔案的理解
在Linux中,目錄(directory)也是一種檔案,
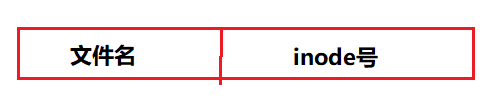
目錄檔案是一系列目錄項(dirent)組成的,每個目錄項,由兩部分組成:所包含檔案的檔案名,以及該檔案名對應的inode號碼,如下圖所示
既然目錄也是檔案,那么目錄本身也一定有其inode,現代作業系統一般采用樹形結構來組織檔案,因此要打開一個檔案,需要先找到該檔案的目錄,并在目錄中找到對應的目錄項,獲取到該檔案的inode號碼,再將磁盤中的內容加載到記憶體,
進入一個目錄需要什么權限?
顯示目錄下的內容是讀權限(r) ,由于目錄檔案內只有檔案名和inode號碼,所以如果只有讀權限,只能獲取檔案名,無法獲取其他資訊,因為其他資訊都儲存在inode節點中,進入是可執行權限 (x),一個目錄默認需要有可執行權限,
2.4 軟鏈接與硬鏈接
我們已經知道,檔案的唯一識別符號是inode而非檔案名,檔案名僅僅是方便用戶使用的一個“綽號”,那么,只能通過一個檔案名來找到對應的inode,獲取檔案的元資訊嗎?在Linux中,為了解決檔案共享的問題,提出了鏈接,鏈接分為硬鏈接和軟鏈接:
2.4.1 硬鏈接
讓不同的檔案名訪問同樣的內容,這種方式被稱為硬鏈接,
可以使用ln指令創建硬鏈接:ln 源檔案 目標檔案,如下圖所示
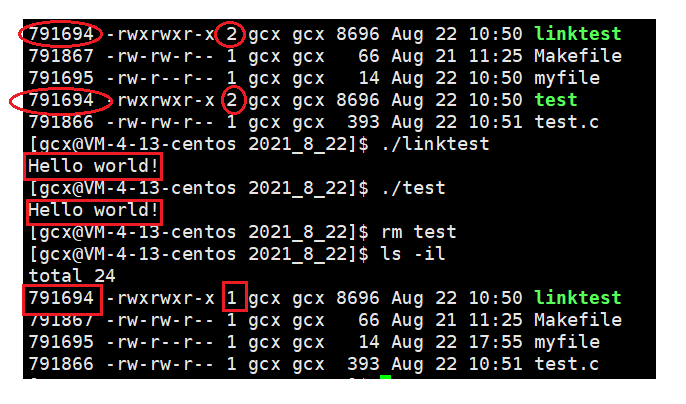
該案例中為test可執行檔案創建了一個硬鏈接linktest,通過ls -il指令可以看到,linktest和test具有相同的inode號碼,也就是說實際上是同一個檔案,此時鏈接數為2,執行test和linktest后,都會輸出同樣的結果,而當洗掉test檔案后,由于linktest的存在,該檔案實際上并未被洗掉,洗掉的僅僅是該檔案名!此時,鏈接數會變為1,
因此我們可以總結出硬鏈接的如下特點:
- 不同的檔案名訪問同樣的內容,
- 對檔案內容進行修改,會影響到所有檔案名,
- 洗掉一個檔案名,不影響另一個檔案名的訪問,當鏈接數變為0時,該檔案才算真正洗掉,
這里需要注意目錄檔案的鏈接數!
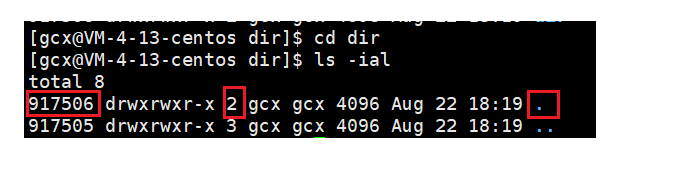
創建一個目錄檔案,輸入ls -il命令后,會看到如下現象:

該目錄檔案的鏈接數居然是2!這是為什么?當我們進入dir,并創建一個目錄檔案后,會發現,“."的inode和dir的inode是一樣的,也就是說dir目錄下的“."是dir的硬鏈接,這是因為創建目錄時,默認會生成兩個目錄項,".“和"..",”." 代表當前檔案,".." 代表上一級檔案,
如果此時我們在dir下再創建一個目錄,會發現dir的鏈接數變為3,這是因為新創建的檔案dir/dir1中包含”.." ,該檔案名也是dir的硬鏈接,
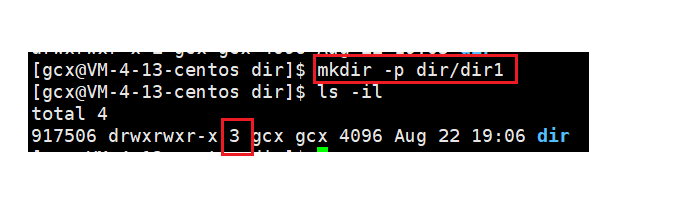
綜上,任何一個目錄的"硬鏈接"總數,總是等于2加上它的子目錄總數(含隱藏目錄),
2.4.2 軟鏈接
軟鏈接類似于Windows下的快捷方式,Linux下通常會將一些目錄層次較深的檔案鏈接到一個更易訪問的目錄中,
用ln -s 命令創建一個檔案的軟鏈接:ln -s 源文檔案或目錄 目標檔案或目錄
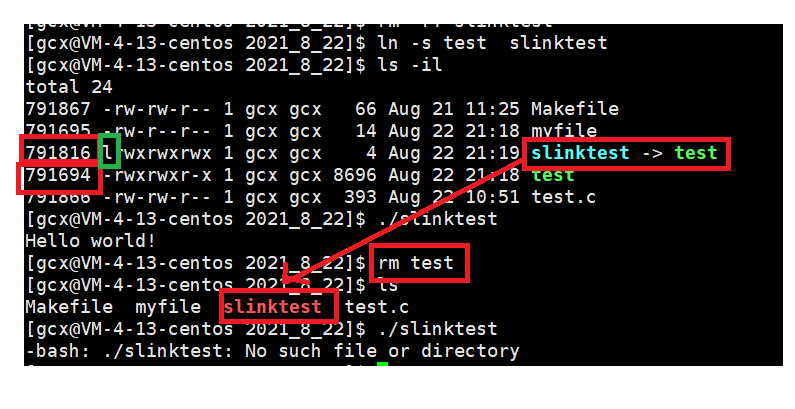
可以看到創建test的軟鏈接slinktest后,slinktest的inode號與test的inode號不一樣,這說明軟鏈接本身也是一個檔案,且檔案型別為l,test的鏈接數始終為1,當洗掉test后,執行slinktest會報出No such file or directory的錯誤,也就是說,軟鏈接依賴于原檔案存在,
硬鏈接和軟鏈接最大的不同在于:
- 軟鏈接指向的是原檔案的檔案名而不是inode,保存了其代表的檔案的絕對路徑,不會改變原檔案的鏈接數,洗掉原檔案,軟鏈接將不能使用,
- 而硬鏈接指向的原檔案的inode,只有當鏈接數變為0是,整個檔案才能被真正洗掉,
3.動靜態庫
在學習動靜態庫前,我們需要先明白什么是庫,庫(Library)就是一段編譯好的二進制代碼,加上頭檔案后就可以供別人使用,一般有兩種情況會用到庫:
- 第一種情況是某些代碼需要給別人使用,但是我們不希望別人看到原始碼,就編譯好并以庫的形式進行封裝,只暴露出頭檔案,別人要使用,只需要加上頭檔案即可,
- 第二種是在實際工程中,編譯一個大型專案往往要花費很多時間,因為很多檔案都需要從源檔案編譯,鏈接,對于某些不會進行大的改動的代碼,我們想減少編譯的時間,就可以把它打包成庫,因為庫是已經編譯好的二進制了,編譯的時候只需要 Link 一下,不會浪費編譯時間,
那么,我們必須明白一個概念——目標檔案,目標檔案有三種形式:
- 可執行目標檔案,即我們通常所認識的,可直接運行的二進制檔案,
- 可重定位目標檔案,包含了二進制的代碼和資料,可以與其他可重定位目標檔案鏈接,并創建一個可執行目標檔案,
- 共享目標檔案,它是一種在加載或者運行時進行鏈接的特殊可重定位目標檔案,當程式執行到一定程度,需要呼叫該目標檔案中的某個介面時,才會將該目標檔案與運行中的檔案鏈接,
通過上面的表述,我們發現鏈接的方式有兩種:一種是提前鏈接好,生成可執行目標檔案;另一種是運行程序中才鏈接,前者被稱為靜態鏈接,后者被稱為動態鏈接,于是便產生了兩種庫——靜態庫與動態庫,
靜態庫在Linux中前綴為lib,后綴為.a,因此一個靜態庫的名字為libxxx.a,動態庫在Linux中前綴為lib,后綴為.so,則一個動態庫的名字為libxxx.so,
靜態庫(.a):程式在編譯鏈接的時候把庫的代碼鏈接到可執行檔案中,程式運行的時候將不再需要靜態庫 ,
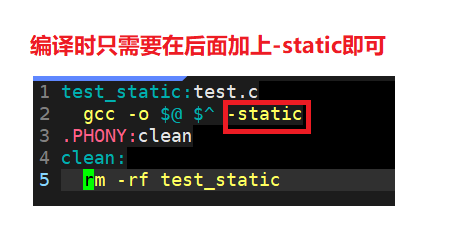
當我們make后,會發現報如下錯誤:
/usr/bin/ld: cannot find -lc
collect2: error: ld returned 1 exit status
make: *** [test_static] Error 1
不要著急,這是因為我們沒有安裝靜態庫!
輸入如下指令:sudo yum install glibc-static即可解決,接下來編譯,會發現出現了我們想要的test_static,發現沒有,通過靜態庫生成的目標檔案非常大!還請大家忍一下,
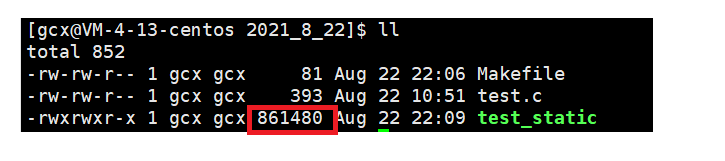
這是因為通過靜態庫生成的可執行檔案時,在鏈接的程序中將靜態庫中需要的部分都“拷貝”到了最終的可執行檔案中,因此這個可執行檔案在一個沒有其需要的庫的linux系統中也能正常運行,
動態庫(.so):程式在運行的時候才去鏈接動態庫的代碼,多個程式共享使用庫的代碼, 一般默認生成的可執行程式都是動態的,動態庫體積小,運行時加載,只有一份,可以看到,動態鏈接生成的test的大小只有靜態鏈接生成的test_static的百分之一左右!
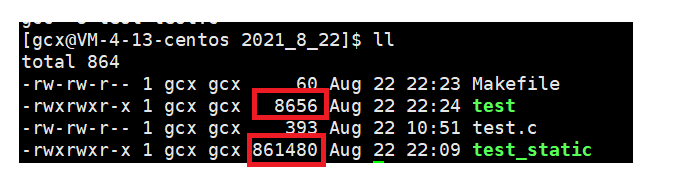
- 一個與動態庫鏈接的可執行檔案僅僅包含它用到的函式入口地址的一個表,而不是外部函式所在目標檔案的整個機器碼,
- 在可執行檔案開始運行以前,外部函式的機器碼由作業系統從磁盤上的該動態庫中復制到記憶體中,這個程序稱為動態鏈接(dynamic linking),
- 動態庫可以在多個程式間共享,所以動態鏈接使得可執行檔案更小,節省了磁盤空間,作業系統采用虛擬記憶體機制允許物理記憶體中的一份動態庫被要用到該庫的所有行程共用,節省了記憶體和磁盤空間,
可以通過file命令查看檔案的鏈接資訊:

通過以上描述,我們可以看出動態庫與靜態庫有以下區別:
- 可執行檔案大小不同,動態庫比靜態庫小得多,
- 擴展性不同,如果靜態庫中某個函式的實作變了,那么這個可執行檔案必須重新編譯,比較耗時,而動態庫只需要更新動態庫本身,不需要重新編譯可執行檔案,
- 加載速度不同,由于靜態庫在運行時才鏈接,因此從時間效率上會稍慢一些,不過由于程式運行的區域性原理,時間損失并不會很多,
- 依賴性不同,靜態鏈接的可執行檔案不需要依賴其他的內容即可運行,而動態鏈接的可執行檔案必須依賴動態庫的存在,一般情況下,系統中有大量的動態庫,不會有太大問題,
總結
學習完系統IO后,我們再來思考最后一個問題,
當檔案打開加載進記憶體后,該檔案在記憶體中的位置為什么不放在inode中,而是存放在file結構體中?
Linux中的檔案是能夠共享的,假如把檔案位置存放在索引節點中,則如果有兩個或更多個行程同時打開同一個檔案時,它們將去訪問同一個索引節點,如果一個行程對該檔案進行寫操作,而另一個同時進行讀操作,顯然,這是不被允許的,
另一方面,打開檔案時有如下特點,
- 一個檔案不僅可以被不同的行程分別打開,而且也可以被同一個行程先后多次打開,
- 一個行程如果先后多次打開同一個檔案,則每一次打開都要分配一個新的檔案描述符,并且指向一個新的file結構,
引入file結構體有利于檔案的共享,當兩個行程共享同一個檔案時,兩個行程的fd可以指向同一個file結構體,file結構體中記錄著檔案的在記憶體中的偏移量,當一個行程進行寫操作后,檔案的偏移量可能發生改變,此時只需要修改file結構體中的偏移量,當該行程寫結束,另一個行程需要進行寫操作時,是在新的偏移量的基礎上進行寫操作,這樣防止了第二個行程重寫第一個行程的輸出內容,
行程可以共享同一個打開的檔案,那行程之間是否能夠進行通信呢?答案是肯定的,下一章我們將會講述《Linux系統編程之行程通信》,如果覺得有用,歡迎您一鍵三連!
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/351895.html
標籤:其他