傳統的計算機結構中,整個物理記憶體都是一條線上的,CPU訪問整個記憶體空間所需要的時間都是相同的,這種記憶體結構被稱之為UMA(Uniform Memory Architecture,一致存盤結構),但是隨著計算機的發展,一些新型的服務器結構中,尤其是多CPU的情況下,物理記憶體空間的訪問就難以控制所需的時間相同了,在多CPU的環境下,系統只有一條總線,有多個CPU都鏈接到上面,而且每個CPU都有自己本地的物理記憶體空間,但是也可以通過總線去訪問別的CPU物理記憶體空間,同時也存在著一些多CPU都可以共同訪問的公共物理記憶體空間,于是乎這就出現了一個新的情況,由于各種物理記憶體空間所處的位置不同,于是訪問它們的時間長短也就各異,沒法保證一致,對于這種情況的記憶體結構,被稱之為NUMA(Non-Uniform Memory Architecture,非一致存盤結構),事實上也沒有完全的UMA,比如常見的單CPU電腦,RAM、ROM等物理存盤空間的訪問時間并非一致的,只是純粹對RAM而言,是UMA的,此外還有一種稱之為MPP的結構(Massive Parallel Processing,大規模并行處理系統),是由多個SMP服務器通過一定的節點互聯網路進行連接,協同作業,完成相同的任務,從外界使用者看來,它是一個服務器系統,
回歸正題,著重看一下NUMA,由于NUMA存盤結構的引入,這就需要相應的管理機制來支持, linux 2.4版本就已經開始對其支持了,隨著新增管理機制的支持,也隨之引入了Node的概念(存盤節點),把訪問時間相同的存盤空間歸結為一個存盤節點,于是當前分析的3.14.12版本,linux的物理記憶體管理機制將物理記憶體劃分為三個層次來管理,依次是:Node(存盤節點)、Zone(管理區)和Page(頁面),
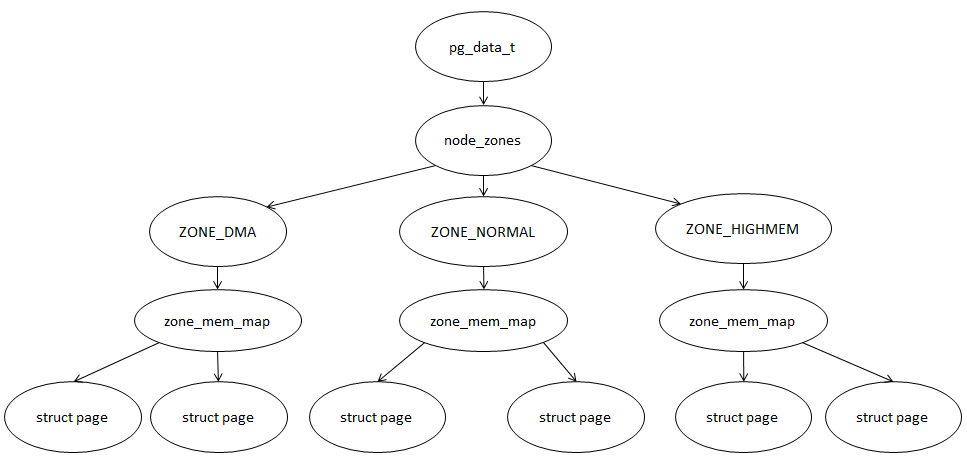
存盤節點的資料結構為pg_data_t,每個NUMA節點都有一個pg_data_t負責記載該節點的記憶體布局資訊,其中pg_data_t結構體中存盤管理區資訊的為node_zones成員,其資料結構為zone,每個pg_data_t都有多個node_zones,通常是三個:ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM,
ZONE_DMA區通常是由于計算機中部分設備無法直接訪問全部記憶體空間而特地劃分出來給該部分設備使用的區,x86環境中,該區通常小于16M,
ZONE_NORMAL區位于ZONE_DMA后面,這個區域被內核直接映射到線性地址的高端部分,x86環境中,該區通常為16M-896M,
ZONE_HIGHMEM區則是系統除了ZONE_DMA和ZONE_NORMAL區后剩下的物理記憶體,這個區不能直接被內核映射,x86環境中,該區通常為896M以后的記憶體,
為什么要有高端記憶體的存在?通常都知道內核空間的大小為1G(線性空間為:3-4G),那么映射這1G記憶體需要多少頁全域目錄項?很容易可以算出來是256項,內核有這么多執行緒在其中,1G夠嗎?很明顯不夠,如果要使用超出1G的記憶體空間怎么辦?如果要使用記憶體,很明顯必須要做映射,那么騰出幾個頁全域目錄項出來做映射?Bingo,就是這樣,那么騰出多少來呢?linux內核的設計就是騰出32個頁全域目錄項,256的1/8,那么32個頁全域目錄項對應多大的記憶體空間?算一下可以知道是128M,也就是說直接映射的記憶體空間是896M,使用超過896M的記憶體空間視為高端記憶體,一旦使用的時候,就需要做映射轉換,這是一件很耗資源的事情,所以不要常使用高端記憶體,就是這么一個由來,
接著看一下記憶體管理框架的初始化實作,initmem_init():
【file:/arch/x86/mm/init_32.c】
#ifndef CONFIG_NEED_MULTIPLE_NODES
void __init initmem_init(void)
{
#ifdef CONFIG_HIGHMEM
highstart_pfn = highend_pfn = max_pfn;
if (max_pfn > max_low_pfn)
highstart_pfn = max_low_pfn;
printk(KERN_NOTICE "%ldMB HIGHMEM available.\n",
pages_to_mb(highend_pfn - highstart_pfn));
high_memory = (void *) __va(highstart_pfn * PAGE_SIZE - 1) + 1;
#else
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE - 1) + 1;
#endif
memblock_set_node(0, (phys_addr_t)ULLONG_MAX, &memblock.memory, 0);
sparse_memory_present_with_active_regions(0);
#ifdef CONFIG_FLATMEM
max_mapnr = IS_ENABLED(CONFIG_HIGHMEM) ? highend_pfn : max_low_pfn;
#endif
__vmalloc_start_set = true;
printk(KERN_NOTICE "%ldMB LOWMEM available.\n",
pages_to_mb(max_low_pfn));
setup_bootmem_allocator();
}
#endif /* !CONFIG_NEED_MULTIPLE_NODES */
將high_memory初始化為低端記憶體頁框max_low_pfn對應的地址大小,接著呼叫memblock_set_node,根據函式命名,可以推斷出該函式用于給早前建立的memblock演算法設定node節點資訊,
memblock_set_node的實作:
【file:/mm/memblock.c】
/**
* memblock_set_node - set node ID on memblock regions
* @base: base of area to set node ID for
* @size: size of area to set node ID for
* @type: memblock type to set node ID for
* @nid: node ID to set
*
* Set the nid of memblock @type regions in [@base,@base+@size) to @nid.
* Regions which cross the area boundaries are split as necessary.
*
* RETURNS:
* 0 on success, -errno on failure.
*/
int __init_memblock memblock_set_node(phys_addr_t base, phys_addr_t size,
struct memblock_type *type, int nid)
{
int start_rgn, end_rgn;
int i, ret;
ret = memblock_isolate_range(type, base, size, &start_rgn, &end_rgn);
if (ret)
return ret;
for (i = start_rgn; i < end_rgn; i++)
memblock_set_region_node(&type->regions[i], nid);
memblock_merge_regions(type);
return 0;
}
memblock_set_node主要呼叫了三個函式做相關操作:memblock_isolate_range、memblock_set_region_node和memblock_merge_regions,
其中memblock_isolate_range:
【file:/mm/memblock.c】
/**
* memblock_isolate_range - isolate given range into disjoint memblocks
* @type: memblock type to isolate range for
* @base: base of range to isolate
* @size: size of range to isolate
* @start_rgn: out parameter for the start of isolated region
* @end_rgn: out parameter for the end of isolated region
*
* Walk @type and ensure that regions don't cross the boundaries defined by
* [@base,@base+@size). Crossing regions are split at the boundaries,
* which may create at most two more regions. The index of the first
* region inside the range is returned in *@start_rgn and end in *@end_rgn.
*
* RETURNS:
* 0 on success, -errno on failure.
*/
static int __init_memblock memblock_isolate_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int *start_rgn, int *end_rgn)
{
phys_addr_t end = base + memblock_cap_size(base, &size);
int i;
*start_rgn = *end_rgn = 0;
if (!size)
return 0;
/* we'll create at most two more regions */
while (type->cnt + 2 > type->max)
if (memblock_double_array(type, base, size) < 0)
return -ENOMEM;
for (i = 0; i < type->cnt; i++) {
struct memblock_region *rgn = &type->regions[i];
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
if (rbase >= end)
break;
if (rend <= base)
continue;
if (rbase < base) {
/*
* @rgn intersects from below. Split and continue
* to process the next region - the new top half.
*/
rgn->base = base;
rgn->size -= base - rbase;
type->total_size -= base - rbase;
memblock_insert_region(type, i, rbase, base - rbase,
memblock_get_region_node(rgn),
rgn->flags);
} else if (rend > end) {
/*
* @rgn intersects from above. Split and redo the
* current region - the new bottom half.
*/
rgn->base = end;
rgn->size -= end - rbase;
type->total_size -= end - rbase;
memblock_insert_region(type, i--, rbase, end - rbase,
memblock_get_region_node(rgn),
rgn->flags);
} else {
/* @rgn is fully contained, record it */
if (!*end_rgn)
*start_rgn = i;
*end_rgn = i + 1;
}
}
return 0;
}
該函式主要做分割操作,在memblock演算法建立時,只是判斷了flags是否相同,然后將連續記憶體做合并操作,而此時建立node節點,則根據入參base和size標記節點記憶體范圍將記憶體劃分開來,如果memblock中的region恰好以該節點記憶體范圍末尾劃分開來的話,那么則將region的索引記錄至start_rgn,索引加1記錄至end_rgn回傳回去;如果memblock中的region跨越了該節點記憶體末尾分界,那么將會把當前的region邊界調整為node節點記憶體范圍邊界,另一部分通過memblock_insert_region()函式插入到memblock管理regions當中,以完成拆分,
順便看一下memblock_insert_region()函式:
【file:/mm/memblock.c】
/**
* memblock_insert_region - insert new memblock region
* @type: memblock type to insert into
* @idx: index for the insertion point
* @base: base address of the new region
* @size: size of the new region
* @nid: node id of the new region
* @flags: flags of the new region
*
* Insert new memblock region [@base,@base+@size) into @type at @idx.
* @type must already have extra room to accomodate the new region.
*/
static void __init_memblock memblock_insert_region(struct memblock_type *type,
int idx, phys_addr_t base,
phys_addr_t size,
int nid, unsigned long flags)
{
struct memblock_region *rgn = &type->regions[idx];
BUG_ON(type->cnt >= type->max);
memmove(rgn + 1, rgn, (type->cnt - idx) * sizeof(*rgn));
rgn->base = base;
rgn->size = size;
rgn->flags = flags;
memblock_set_region_node(rgn, nid);
type->cnt++;
type->total_size += size;
}
這里一個memmove()將后面的region資訊往后移,另外呼叫memblock_set_region_node()將原region的node節點號保留在被拆分出來的region當中,
而memblock_set_region_node()函式實作僅是賦值而已:
【file:/mm/memblock.h】
static inline void memblock_set_region_node(struct memblock_region *r, int nid)
{
r->nid = nid;
}
至此,回到memblock_set_node()函式,里面接著memblock_isolate_range()被呼叫的memblock_set_region_node()已知是獲取node節點號,而memblock_merge_regions()則前面已經分析過了,是用于將region合并的,
最后回到initmem_init()函式中,memblock_set_node()回傳后,接著呼叫的函式為sparse_memory_present_with_active_regions(),
這里sparse memory涉及到linux的一個記憶體模型概念,linux內核有三種記憶體模型:Flat memory、Discontiguous memory和Sparse memory,其分別表示:
- Flat memory:顧名思義,物理記憶體是平坦連續的,整個系統只有一個node節點,
- Discontiguous memory:物理記憶體不連續,記憶體中存在空洞,也因而系統將物理記憶體分為多個節點,但是每個節點的內部記憶體是平坦連續的,值得注意的是,該模型不僅是對于NUMA環境而言,UMA環境上同樣可能存在多個節點的情況,
- Sparse memory:物理記憶體是不連續的,節點的內部記憶體也可能是不連續的,系統也因而可能會有一個或多個節點,此外,該模型是記憶體熱插拔的基礎,
看一下sparse_memory_present_with_active_regions()的實作:
【file:/mm/page_alloc.c】
/**
* sparse_memory_present_with_active_regions - Call memory_present for each active range
* @nid: The node to call memory_present for. If MAX_NUMNODES, all nodes will be used.
*
* If an architecture guarantees that all ranges registered with
* add_active_ranges() contain no holes and may be freed, this
* function may be used instead of calling memory_present() manually.
*/
void __init sparse_memory_present_with_active_regions(int nid)
{
unsigned long start_pfn, end_pfn;
int i, this_nid;
for_each_mem_pfn_range(i, nid, &start_pfn, &end_pfn, &this_nid)
memory_present(this_nid, start_pfn, end_pfn);
}
里面的for_each_mem_pfn_range()是一個旨在回圈的宏定義,而memory_present()由于實驗環境中沒有定義CONFIG_HAVE_MEMORY_PRESENT,所以是個空函式,暫且擱置不做深入研究,
最后看一下initmem_init()退出前呼叫的函式setup_bootmem_allocator():
【file:/arch/x86/mm/init_32.c】
void __init setup_bootmem_allocator(void)
{
printk(KERN_INFO " mapped low ram: 0 - %08lx\n",
max_pfn_mapped<<PAGE_SHIFT);
printk(KERN_INFO " low ram: 0 - %08lx\n", max_low_pfn<<PAGE_SHIFT);
}
原來該函式是用來初始化bootmem管理演算法的,但現在x86的環境已經使用了memblock管理演算法,這里僅作保留列印部分資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/36199.html
標籤:嵌入式