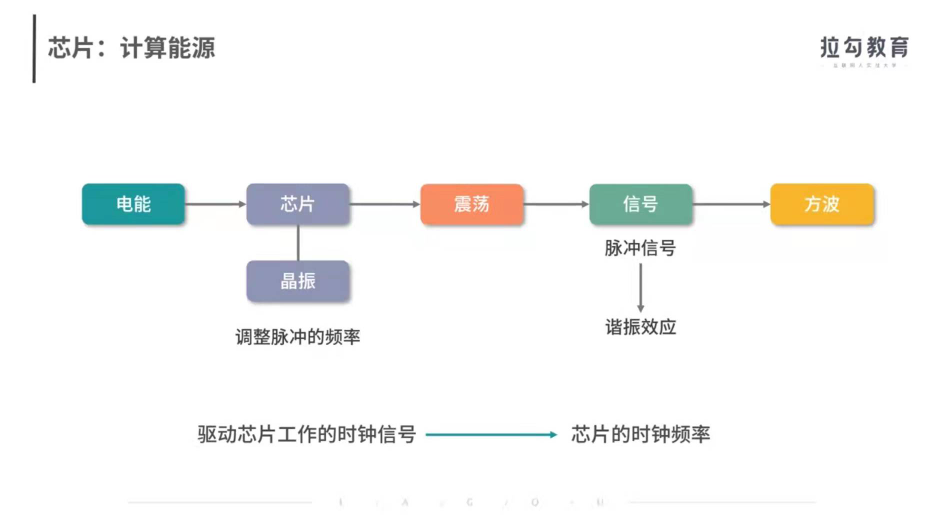
1、芯片是怎么作業的呢?電能供給給芯片,芯片中的一種電子元件晶振(也就是石英晶體)通電后產生震蕩,震蕩會產生頻率穩定的脈沖信號,通常這是一種高頻的脈沖信號,每秒可達百萬次,然后,我們通過諧振效應發放這個信號,形成方波,再通過電子元件調整這種脈沖的頻率,把脈沖信號轉換為我們需要的頻率,這就形成了驅動芯片作業的時鐘信號,這種信號的頻率,我們也稱作芯片的時鐘頻率,最后,時鐘信號驅動著芯片作業,就像人體的脈搏一樣,每一次脈沖到來,都讓芯片的狀態發生一次變化,用這種方法,最終存盤器中的指令被一行行執行,
2、最早在 19 世紀初,德國著名數學家希爾伯特提出:這個世界可以建立一套完善的公理體系,由少數幾個公理出發,推匯出所有的定理和推論,后來哥德爾提出了不完備性定理,反駁了這種觀點:即便在完善的公理體系中仍然可以找到不能被證明也不能被證偽的命題,
3、圖靈發現如果一個問題是可計算的,那么它的解決方案就必須可以被具化成一條條的指令,也就是可以使用圖靈機處理,因此,不能使用圖靈機處理的問題,都是不可計算的問題,
4、不可計算問題,比如 “素數是不是有無窮多個?”盡管我們可以通過有限的步驟計算出下一個素數,但是,我們還是不能回答“素數是不是有無窮多個”這樣的問題,因為要回答這樣的問題,我們會不停地尋找下一個素數,如果素數是無窮的,那么我們的計算就是無窮無盡的,所以這樣的問題不可計算,
5、不可計算問題,比如停機問題,我們無法實作用一個通用程式去判斷另一個程式是否會停止,比如你用運行這段程式來檢查一個程式是否會停止時,你會發現不能因為這個程式執行了 1 天,就判定它不會停止,也不能因為這個程式執行了 10 年,從而得出它不會停止的結論,
6、可計算問題,其計算開銷又分為時間復雜度和空間復雜度,
7、在所有可以計算的問題中,像 O(N^1000) 的問題,雖然現在的計算能力不夠,但是相信在遙遠的未來,我們會擁有能力解決,這種我們有能力解決的問題,統稱為多項式時間(Polynomial time)問題,
8、另外,還有一類問題復雜度本身也是指數形式的問題,比如 O(2^N)的問題,這型別的問題隨著規模 N 上升,時間開銷的增長速度和人類計算能力增長速度持平甚至更快,因此雖然這類問題可以計算,但是當 N 較大時,因為計算能力不足,最終結果依然無法被解決,我們記為 NP 問題,
9、圖靈機在計算機科學方面有兩個巨大的貢獻:
- 它清楚地定義了計算機能力的邊界,也就是可計算理論;
- 它定義了計算機由哪些部分組成,程式又是如何執行的;
10、圖靈機的內部構造:

- 圖靈機擁有一條無限長的紙帶,紙帶上是一個格子挨著一個格子,格子中可以寫字符,你可以把紙帶看作記憶體,而這些字符可以看作是記憶體中的資料或者程式;
- 圖靈機有一個讀寫頭,讀寫頭可以讀取任意格子上的字符,也可以改寫任意格子的字符;
- 讀寫頭上面的盒子里是一些精密的零件,包括圖靈機的存盤、控制單元和運算單元;
11、馮諾依曼模型遵循了圖靈機的設計,并提出了用電子元件構造計算機,約定了用二進制進行計算和存盤,并且將計算機結構分為以下五個部分:
- 輸入設備
- 輸出設備
- 記憶體
- 中央處理器
- 總線
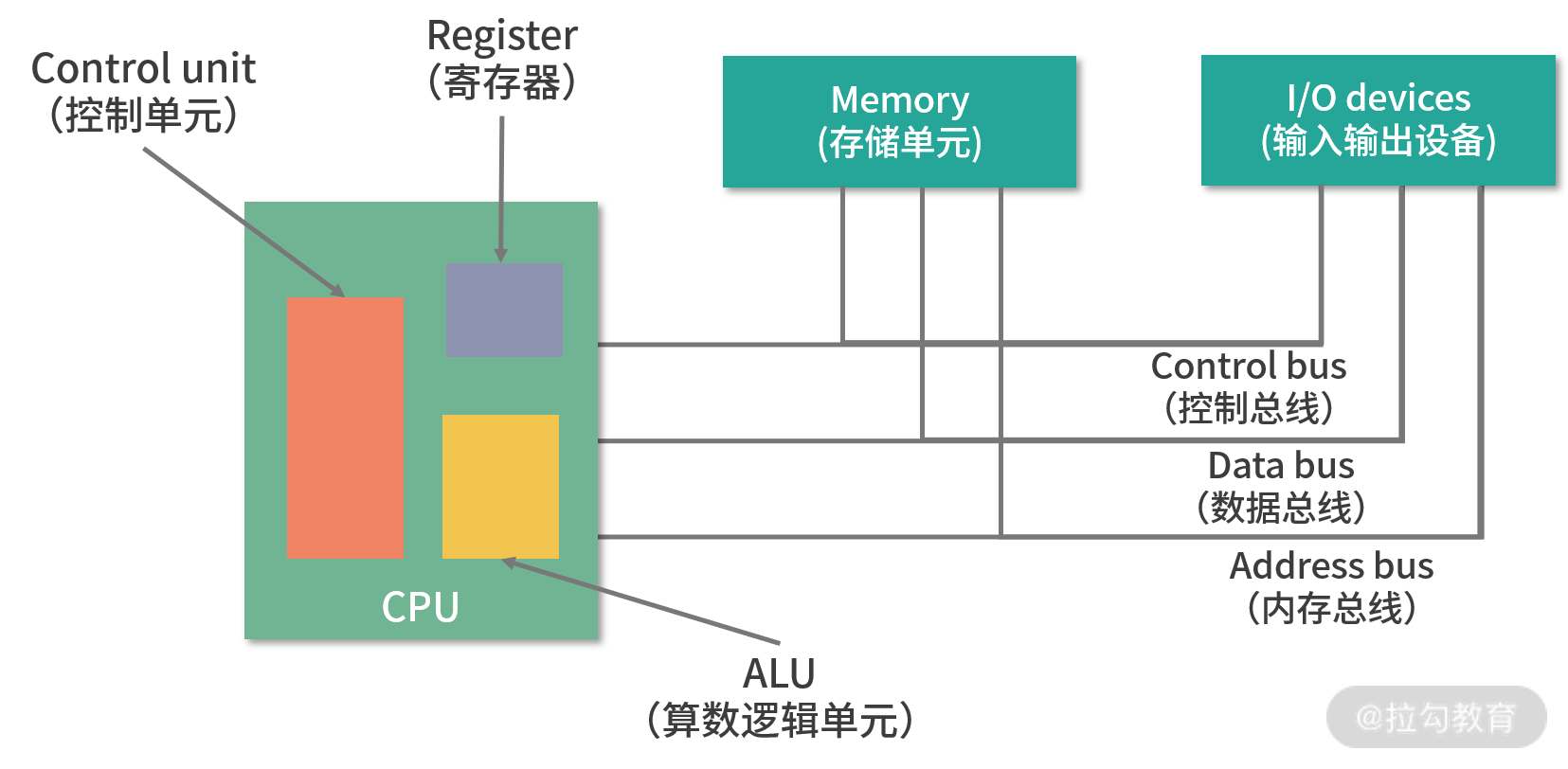
12、馮·諾依曼體系結構的要點是:計算機的數制采用二進制,計算機應該按照程式順序執行,它采用存盤程式方式,指令和資料不加區別,混合存盤在同一個存盤器中,資料和程式在記憶體中是沒有區別的,它們都是記憶體中的資料,當 EIP 指標指向哪,CPU 就加載哪段記憶體中的資料,如果是不正確的指令格式,CPU 就會發生錯誤中斷,
13、馮諾依曼模型中 CPU 負責控制和計算,為了方便計算較大的數值,CPU 每次可以計算多個位元組的資料,
- 如果 CPU 每次可以計算 4 個 byte(暫存器),那么我們稱作 32 位 CPU;
- 如果 CPU 每次可以計算 8 個 byte(暫存器),那么我們稱作 64 位 CPU;
14、64 位的 CPU 和 32 位比較有哪些優勢?
- 64 位 CPU 可以執行更大數字的運算,這個優勢在普通應用上不明顯,但是對于數值計算較多的應用就非常明顯;
- 64 位 CPU 可以尋址更大的記憶體空間,但是也會受到地址總線條數的限制,比如和 64 位 CPU 配套作業的地址總線只有 40 條,那么可以尋址的范圍就只有 1T,也就是 2^40,
15、CPU 離記憶體太遠,需要一種離自己近的存盤來存盤將要被計算的數字,這種存盤就是暫存器,暫存器就在 CPU 里,離控制單元和邏輯運算單元非常近,因此速度很快,
16、CPU 和記憶體以及其他設備之間,也需要通信,因此我們用一種特殊的設備進行控制,就是總線,總線分成 3 種:
- 地址總線,專門用來指定 CPU 將要操作的記憶體地址;
- 資料總線,用來讀寫記憶體中的資料,
- 控制總線,用來發送和接收關鍵信號,比如后面我們會學到的中斷信號,還有設備復位、就緒等信號,都是通過控制總線傳輸,
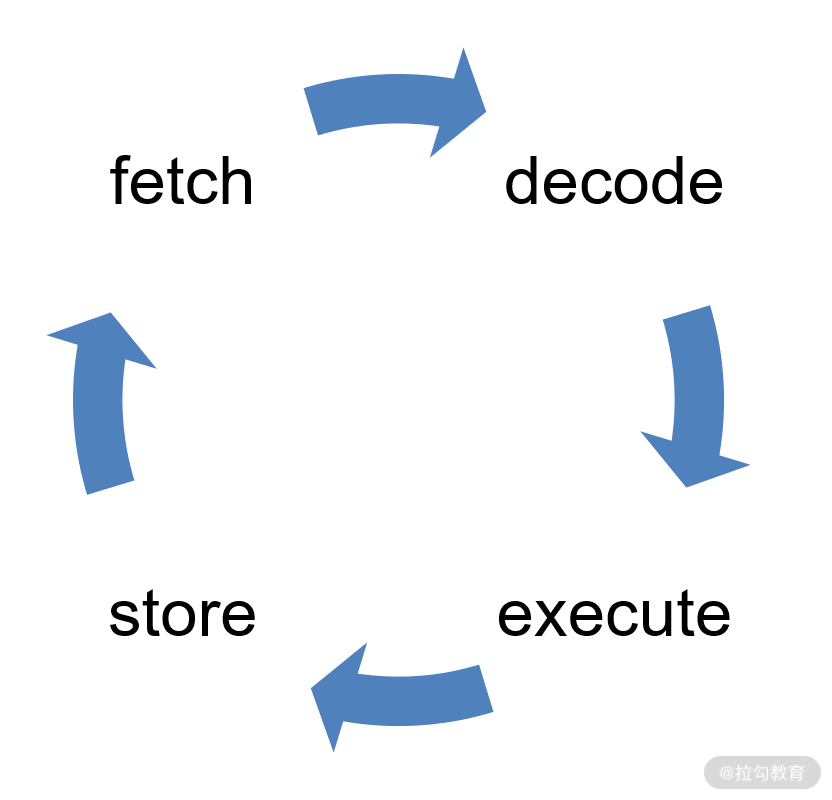
17、CPU 的指令周期:
- 首先 CPU 通過 PC 指標讀取對應記憶體地址的指令,我們將這個步驟叫做 Fetch,就是獲取的意思,
- CPU 對指令進行解碼,我們將這個部分叫做 Decode,
- CPU 執行指令,我們將這個部分叫做 execute,
- CPU 將結果存回暫存器或者將暫存器存入記憶體,我們將這個步驟叫做 Store,
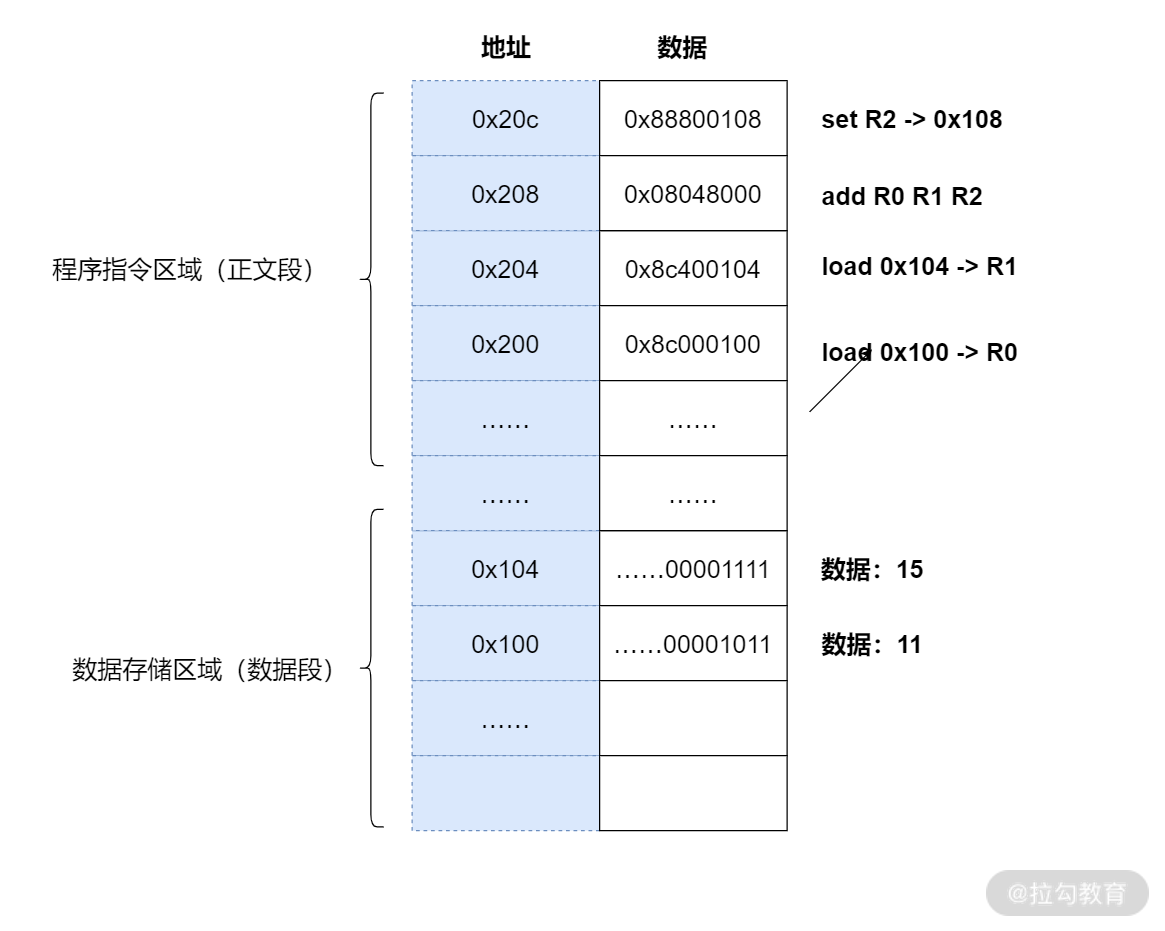
18、一段代碼 a = 11 + 15,它是怎么被 CPU 執行的呢?首先,這是一段高級語言,要被先編譯成機器能識別的低級指令,這些指令和資料會被存盤到專門的區域;然后 PC 會指向最開始的指令,依次執行:
- 0x200 位置的 load 指令將地址 0x100 中的資料 11 匯入暫存器 R0;
- 0x204 位置的 load 指令將地址 0x104 中的資料 15 匯入暫存器 R1;
- 0x208 位置的 add 指令將暫存器 R0 和 R1 中的值相加,存入暫存器 R2;
- 0x20c 位置的 store 指令將暫存器 R2 中的值存回資料區域中的 0x1108 位置,
19、CPU 指令從功能上來劃分,大概可以分為以下 5 類:
- I/O 型別的指令,比如處理和記憶體間資料交換的指令 store/load 等;再比如將一個記憶體地址的資料轉移到另一個記憶體地址的 mov 指令,
- 計算型別的指令,最多只能處理兩個暫存器,比如加減乘除、位運算、比較大小等,
- 跳轉型別的指令,用處就是修改 PC 指標,比如編程中大家經常會遇到需要條件判斷+跳轉的邏輯,比如 if-else,swtich-case、函式呼叫等,
- 信號型別的指令,比如發送中斷的指令 trap,
- 閑置 CPU 的指令 nop,一般 CPU 都有這樣一條指令,執行后 CPU 會空轉一個周期,
20、CPU 是用石英晶體產生的脈沖轉化為時鐘信號驅動的,每一次時鐘信號高低電平的轉換就是一個周期,我們稱為時鐘周期,CPU 的主頻,說的就是時鐘信號的頻率,比如一個 1GHz 的 CPU,說的是時鐘信號的頻率是 1G,
21、平時你編程做的事情,用機器指令也能做,所以從計算能力上來說它們是等價的,最終這種計算能力又和圖靈機是等價的,如果一個語言的能力和圖靈機等價,我們就說這個語言是圖靈完備的語言,現在市面上的絕大多數語言都是圖靈完備的語言,但也有一些不是,比如 HTML、正則運算式和 SQL 等,
22、我們把存盤器分成幾個級別:
-
暫存器:訪問速度非常快,一般要求在
半個 CPU 時鐘周期內完成,讀寫數量通常在幾十到幾百之間,每個暫存器可以用來存盤一定位元組(byte)的資料(32 位 CPU 存盤 4 個位元組;64 位 CPU 存盤 8 個位元組), -
L1-Cache:L1- 快取在 CPU 中,相比暫存器,雖然它的位置距離 CPU 核心更遠,但造價更低,通常 L1-Cache 大小在幾十 Kb 到幾百 Kb 不等,讀寫速度在
2~4 個 CPU 時鐘周期, -
L2-Cache:L2- 快取也在 CPU 中,位置比 L1- 快取距離 CPU 核心更遠,它的大小比 L1-Cache 更大,具體大小要看 CPU 型號,有 2M 的,也有更小或者更大的,速度在
10~20 個 CPU 周期, -
L3-Cache:L3- 快取同樣在 CPU 中,位置比 L2- 快取距離 CPU 核心更遠,大小通常比 L2-Cache 更大,讀寫速度在
20~60 個 CPU 周期,L3 快取大小也是看型號的,比如 i9 CPU 有 512KB L1 Cache;有 2MB L2 Cache; 有16MB L3 Cache, -
記憶體:記憶體的主要材料是半導體硅,是插在主板上作業的,因為它的位置距離 CPU 有一段距離,所以需要用總線和 CPU 連接,因為記憶體有了獨立的空間,所以體積更大,造價也比上面提到的存盤器低得多,現在有的個人電腦上的記憶體是 16G,但有些服務器的記憶體可以到幾個 T,記憶體速度大概在
200~300 個 CPU 周期之間, -
SSD 和硬碟:SSD 也叫固態硬碟,結構和記憶體類似,但是它的優點在于斷電后資料還在,記憶體、暫存器、快取斷電后資料就消失了,記憶體的讀寫速度比 SSD 大概快 10~1000 倍,以前還有一種物理讀寫的磁盤,我們也叫作硬碟,它的速度比記憶體慢 100W 倍左右,因為它的速度太慢,現在已經逐漸被 SSD 替代,
23、當 CPU 需要記憶體中某個資料的時候,如果暫存器中有這個資料,我們可以直接使用;如果暫存器中沒有這個資料,我們就要先查詢 L1 快取;L1 中沒有,再查詢 L2 快取;L2 中沒有再查詢 L3 快取;L3 中沒有,再去記憶體中拿,
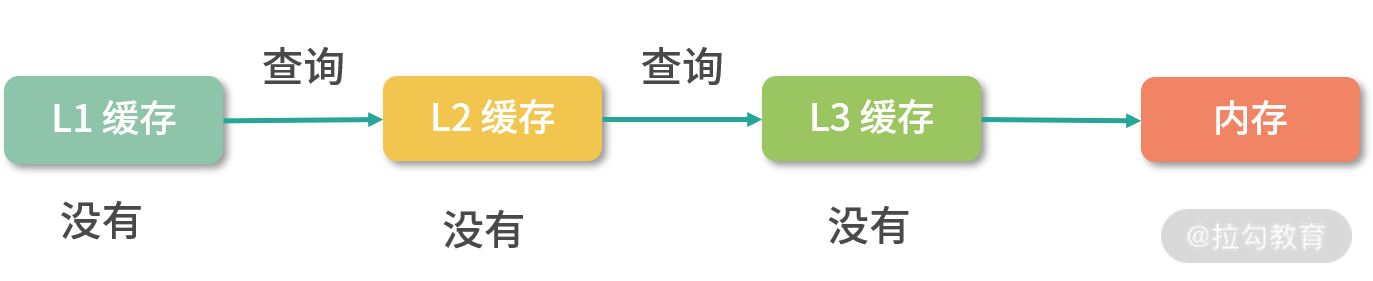
24、CPU 會把記憶體中的指令預讀幾十潭訓者上百條到讀寫速度較快的 L1- 快取中,因為 L1- 快取的讀寫速度只有 2~4 個時鐘周期,是可以跟上 CPU 的執行速度的,這里又產生了另一個問題:如果資料和指令都存盤在 L1- 快取中,如果資料快取覆寫了指令快取,就會產生非常嚴重的后果,因此,L1- 快取通常會分成兩個區域,一個是指令區,一個是資料區,(L2/L3 不需要劃分指令區和資料區,因為它們不需要協助處理指令預讀的事情)
25、據統計,L1 快取的命中率在 80% 左右,L1/L2/L3 加起來的命中率在 95% 左右,因此,CPU 快取的設計還是相當合理的,只有 5% 的記憶體讀取會穿透到記憶體,95% 都能讀取到快取, 這也是為什么程式語言逐漸取消了讓程式員操作暫存器的語法,因為快取保證了很高的命中率,多余的優化意義不大,而且很容易出錯,
26、SSD、記憶體和 L1 Cache 相比速度差多少倍?因為記憶體比 SSD 快 10~1000 倍,L1 Cache 比記憶體快 100 倍左右,因此 L1 Cache 比 SSD 快了 1000~100000 倍,所以你有沒有發現 SSD 的潛力很大,好的 SSD 已經接近記憶體了,只不過造價還略高,這個問題告訴我們,不同的存盤器之間性能差距很大,構造存盤器分級很有意義,分級的目的是要構造快取體系,
27、假設有一個二維陣列,總共有 1M 個條目,如果我們要遍歷這個二維陣列,應該逐行遍歷還是逐列遍歷?
【決議】 二維陣列本質還是 1 維陣列,只不過進行了腳標運算,比如說一個 N 行 M 列的陣列,第 y 行第 x 列的坐標是: x + y*M,因此當行坐標增加時,記憶體空間是跳躍的,列坐標增加時,記憶體空間是連續的,
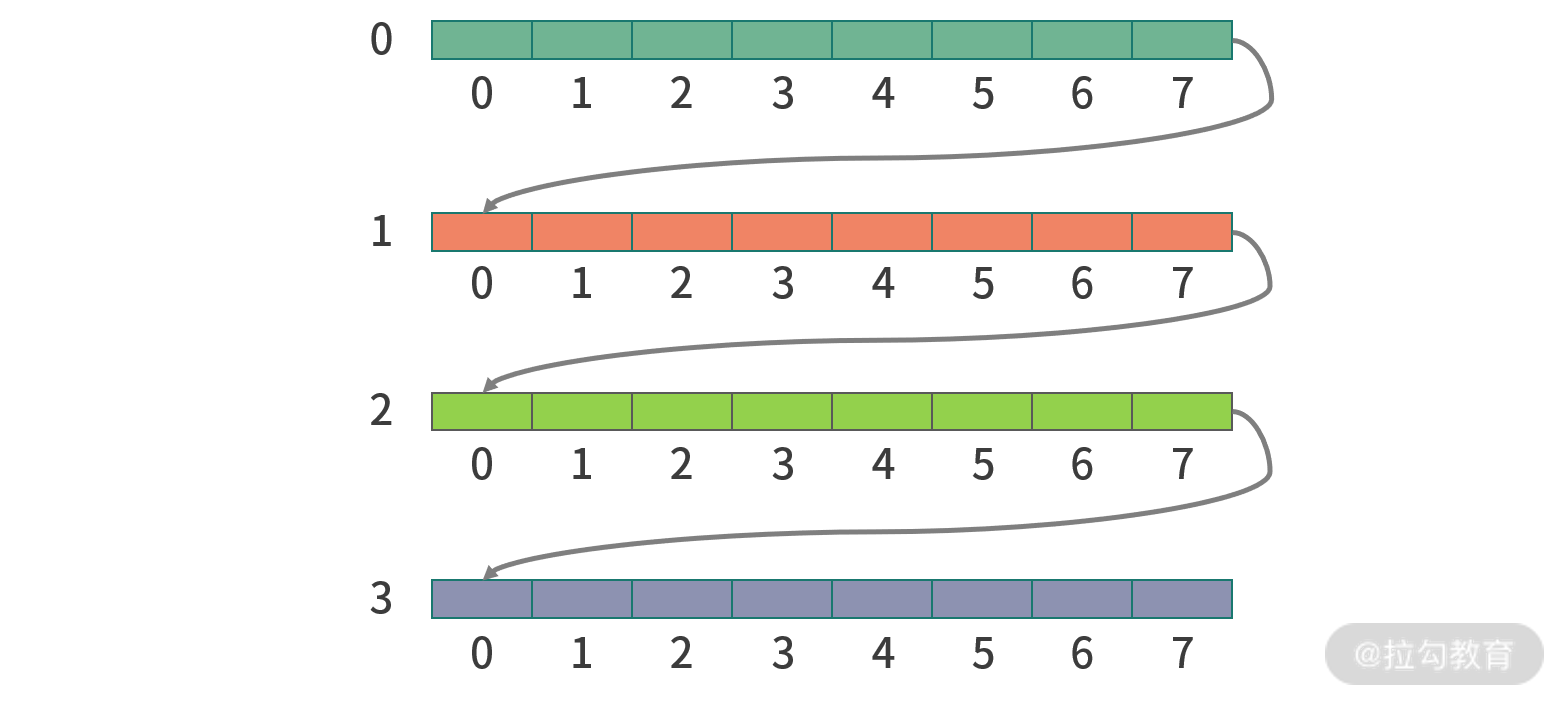
當 CPU 遍歷二維陣列的時候,會先從 CPU 快取中取資料,關鍵因素在于現在的 CPU 設計不是每次讀取一個記憶體地址,而是讀取每次讀取相鄰的多個記憶體地址(記憶體速度 200~300 CPU 周期,預讀提升效率),所以這相當于機器和人的約定,如果程式員不按照這個約定,就無法利用預讀的優勢,
另一方面當讀取記憶體地址跳躍較大的時候,會觸發記憶體的頁面置換,
28、怎么用非遞回演算法實作斐波那契數列?
public class Call {
public static void main(String[] args) {
int fib = fib(4);
System.out.println(fib);
int fib2 = fib2(4);
System.out.println(fib2);
}
static int fib(int n) {
if (n == 1 || n == 2) {
return n;
}
return fib(n - 1) + fib(n - 2);
}
private static int fib2(int n) {
if (n == 1 || n == 2) {
return n;
}
//初始化資料
int[] stack = new int[n];
int point = n - 3;
stack[n - 1] = 1;
stack[n - 2] = 2;
//陣列模擬出堆疊入堆疊
while (point >= 0) {
stack[point] = stack[point + 1] + stack[point + 2];
point--;
}
return stack[0];
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/397113.html
標籤:Linux
下一篇:linux行程間的管道通信