作者:周童
來自酒店搜索報價中心,主要負責酒店報價快取,計算相關系統的開發以及性能優化等作業,熱愛摩旅,
一個習以為常的細節
之前在做 ReentrantLock 相關的試驗,試驗本身很簡單,和本文相關的簡化版如下:**(提示:以下代碼均可左右滑動)

就是通過可重入鎖的保護并行對共享變數進行自增,
突然想到一個問題:共享變數 count 沒有加 volatile 修飾,那么在并發自增的程序當中是如何保持記憶體立即可見的呢?上面的代碼做自增肯定是沒問題的,可見 LOCK 不僅僅保證了獨占性,必定還有一種機制保證了記憶體可見性,
可能很多人和我一樣,對 LOCK 的認知是如此 “理所應當”,以至于從沒有去思考為什么,就好像每天太陽都會從東方升起而不覺得這有什么好質疑的,現在既然問到這兒了,那就準備一探究竟,
幾個概念
Java Memory Model (JMM)
即 Java 記憶體模型,直接參考 wiki 定義:
"The Java memory model describes how threads in the Java programming language interact through memory. Together with the description of single-threaded execution of code, the memory model provides the semantics of the Java programming language."
JMM 定義了執行緒和記憶體之間底層互動的語意和規范,比如多執行緒對共享變數的寫 / 讀操作是如何互相影響,
Memory ordering
Memory ordering 跟處理器通過總線向記憶體發起讀 (load)寫 (store)的操作順序有關,對于早期的 Intel386 處理器,保證了記憶體底層讀寫順序和代碼保持一致,我們稱之為 program ordering,即代碼中的記憶體讀寫順序就限定了處理器和記憶體互動的順序,所見即所得,而現代的處理器為了提升指令執行速度,在保證程式語意正確的前提下,允許編譯器對指令進行重排序,也就是說這種指令重排序對于上層代碼是感知不到的,我們稱之為 processor ordering.
JMM 允許編譯器在指令重排上自由發揮,除非程式員通過 synchronized/volatile/CAS 顯式干預這種重排機制,建立起同步機制,保證多執行緒代碼正確運行,
Happens-before
對于 volatile 關鍵字大家都比較熟悉,該關鍵字確保了被修飾變數的記憶體可見性,也就是執行緒 A 修改了 volatile 變數,那么執行緒 B 隨后的讀取一定是最新的值,然而對于如下代碼有個很容易被忽視的點:

當執行緒 A 執行完 line 2 之后,變數 a 的更新值也一同被更新到記憶體當中,JMM 能保證隨后執行緒 B 讀取到 b 后,一定能夠看到 a = 1,之所以有這種機制是因為 JMM 定義了 happens-before 原則,直接貼資料:
-
Each action in a thread happens-before every action in that thread that comes later in the program order
-
An unlock on a monitor happens-before every subsequent lock on that same monitor
-
A write to a volatile field happens-before every subsequent read of that same volatile
-
A call to Thread.start() on a thread happens-before any actions in the started thread
-
All actions in a thread happen-before any other thread successfully returns from a Thread.join()on that thread
其中第 3 條就定義了 volatile 相關的 happens-before 原則,類比下面的同步機制,一圖勝千言:
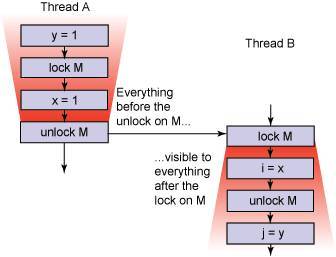
也就是說 volatile 寫操作會把之前的共享變數更新一并發布出去,而不只是 volatile 變數本身,Happens-before 原則會保證 volatile 寫之后,針對同一個 volatile 變數讀,后面的所有共享變數都是可見的,
初步釋疑
Happens-before 正是解釋文章開頭問題的關鍵,以公平鎖為例,我們看看 ReentrantLock 獲取鎖 & 釋放鎖的關鍵代碼:
private volatile int state; // 關鍵 volatile 變數protected final int getState() { return state;}// 獲取鎖protected final boolean tryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); // 重要!!!讀 volatile 變數 ... // 競爭獲取鎖邏輯,省略 }// 釋放鎖protected final boolean tryRelease(int releases) { boolean free = false; ... // 根據狀態判斷是否成功釋放,省略 setState(c); // 重要!!!寫 volatile 變數 return free;}
簡單來說就是對于每一個進入到鎖的臨界區域的執行緒,都會做三件事情:
-
獲取鎖,讀取 volatile 變數;
-
執行臨界區代碼,針對本文是對 count 做自增;
-
寫 volatile 變數 (即發布所有寫操作),釋放鎖,
結合上面 happens-before 概念,那么 count 變數自然就對其它執行緒做到可見了,
事情還沒有結束
我們只是利用 volatile 的 happens-before 原則對問題進行了初步的解釋,happens-before 本身只是一個 JMM 的約束,然而在底層又是怎么實作的呢?這里又有一個重要的概念:記憶體屏障(Memory barriers),
我們可以把記憶體屏障理解為 JMM 賴以建立的底層機制,wiki 定義:
"A memory barrier, also known as a membar, memory fence or fence instruction, is a type of barrier instruction that causes a central processing unit (CPU) or compiler to enforce an ordering constraint on memoryoperations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier."
簡而言之就是記憶體屏障限制死了屏障前后的記憶體操作順序,抽象出來有四種記憶體屏障(因為記憶體 load/store 最多也就四種組合嘛),具體實作視不同的處理器而不同,我們這里看最常見的 x86 架構的處理器: volatile 的 happens-before 原則其實就是依賴的 StoreLoad 記憶體屏障,重點關注 LOCK 指令實作,這和 volatile 的底層實作息息相關,查看下面代碼片段對應的匯編代碼:
volatile 的 happens-before 原則其實就是依賴的 StoreLoad 記憶體屏障,重點關注 LOCK 指令實作,這和 volatile 的底層實作息息相關,查看下面代碼片段對應的匯編代碼:

利用 hsdis 查看對應匯編片段(只包含關鍵部分):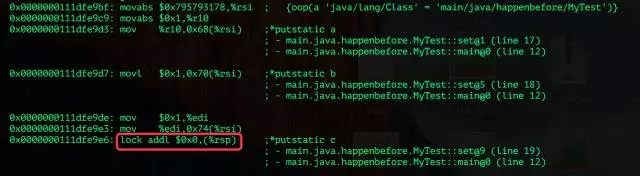 可以看到在 set() 方法對 a,b,c 賦值后,多出了一行 "lock addl $0x0,(%rsp)",這行代碼只是對 stack pointer 加 0,無含義,但通過上文我們得知,x86 架構處理器的 LOCK prefix 指令相當于 StoreLoad 記憶體屏障,LOCK prefix 的指令會觸發處理器做特殊的操作,查看 Intel 64 and IA-32 開發手冊的相關資料:
可以看到在 set() 方法對 a,b,c 賦值后,多出了一行 "lock addl $0x0,(%rsp)",這行代碼只是對 stack pointer 加 0,無含義,但通過上文我們得知,x86 架構處理器的 LOCK prefix 指令相當于 StoreLoad 記憶體屏障,LOCK prefix 的指令會觸發處理器做特殊的操作,查看 Intel 64 and IA-32 開發手冊的相關資料:
"Synchronization mechanisms in multiple-processor systems may depend upon a strong memory-ordering model. Here, a program can use a locking instruction such as the XCHG instruction or the LOCK prefix to ensure that a read-modify-write operation on memory is carried out atomically. Locking operations typically operate like I/O operations in that they wait for all previous instructions to complete and for all buffered writes to drain to memory."
LOCK prefix 會觸發 CPU 快取回寫到記憶體,而后通過 CPU 快取一致性機制(這又是個很大的話題),使得其它處理器核心能夠看到最新的共享變數,實作了共享變數對于所有 CPU 的可見性,
總結
針對本文開頭提出的記憶體可見性問題,有著一系列的技術依賴關系才得以實作:count++ 可見性 → volatile 的 happens-before 原則 → volatile 底層 LOCK prefix 實作 → CPU 快取一致性機制,
補充一下,針對 ReentrantLock 非公平鎖的實作,相比公平鎖只是在爭奪鎖的開始多了一步 CAS 操作,而 CAS 在 x86 多處理器架構中同樣對應著 LOCK prefix 指令,因此在記憶體屏障上有著和 volatile 一樣的效果,
關注公眾號Java技術堆疊回復"面試"獲取我整理的2020最全面試題及答案,
推薦去我的博客閱讀更多:
1.Java JVM、集合、多執行緒、新特性系列教程
2.Spring MVC、Spring Boot、Spring Cloud 系列教程
3.Maven、Git、Eclipse、Intellij IDEA 系列工具教程
4.Java、后端、架構、阿里巴巴等大廠最新面試題
覺得不錯,別忘了點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/141393.html
標籤:Java
上一篇:android studio廣播