心累的時候不妨停下來休息一下,好好收拾一下情緒在繼續前進
Federation架構設計
1. NameNode架構的局限性
(1)Namespace(命名空間)的限制
? 由于NameNode在記憶體中存盤所有的元資料(metadata),因此單個NameNode所能存盤的物件(檔案+塊)數目受到NameNode所在JVM的heap size的限制,50G的heap能夠存盤20億(200million)個物件,這20億個物件支持4000個DataNode,12PB的存盤(假設檔案平均大小為40MB),隨著資料的飛速增長,存盤的需求也隨之增長,單個DataNode從4T增長到36T,集群的尺寸增長到8000個DataNode,存盤的需求從12PB增長到大于100PB,
(2)隔離問題
由于HDFS僅有一個NameNode,無法隔離各個程式,因此HDFS上的一個實驗程式就很有可能影響整個HDFS上運行的程式,
(3)性能的瓶頸
? 由于是單個NameNode的HDFS架構,因此整個HDFS檔案系統的吞吐量受限于單個NameNode的吞吐量,
2.HDFS Federation架構設計
能不能有多個NameNode
| NameNode | NameNode | NameNode |
|---|---|---|
| 元資料 | 元資料 | 元資料 |
| Log | machine | 電商資料/話單資料 |
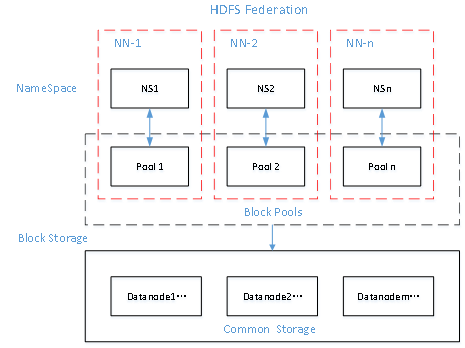
3.HDFS Federation應用思考
不同應用可以使用不同NameNode進行資料管理,圖片業務、爬蟲業務、日志審計業務
Hadoop生態系統中,不同的框架使用不同的NameNode進行管理NameSpace,(隔離性)
但是呢,僅限于超大型公司,超大型資料量使用,中小型公司不用考慮這樣的架構,畢竟服務器開銷很大
相關資料

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/141395.html
標籤:Java