PYTHON 補充知識點
面向物件三大特性:封裝,繼承和多型,
繼承的意義在于兩點:
第一,子類如若繼承自父類,則自動獲取父類所有功能,并且可以在此基礎上再去添加自己獨有的功能,
第二,當子類和父類存在同樣方法時,子類的方法覆寫了父類的代碼,于是子類物件執行的將是子類的方法,即“多型”,
多型到底有什么用呢?在繼承關系里,子類物件的資料型別也可以被當作父類的資料型別,但是反過來不行,那么當我們撰寫一個函式,引數需要傳入某一個型別的物件時,我們根本不需要關心這個物件具體是哪個子類,統統按斬訓類來處理,而具體呼叫誰的多載函式,再具體根據物件確切型別來決定:
class Animal():
def get_name(self):
print("animal")
class Dog(Animal):
def get_name(self):
print("dog")
class Cat(Animal):
def get_name(self):
print("cat")
def run(animal): # 待執行的函式,
animal.get_name()
cat = Cat()
run(cat)
dog = Dog()
run(dog)
>>>cat
>>>dog
當我們再新增子類rabbit,wolf等時,根本不需要改變run函式,這就是著名的開閉原則:即對擴展開放(增加子類),對修改關閉(不需要改變依賴父類的函式引數)
多型存在的三個必要條件:繼承,重寫,父類參考指向子類物件,
對于靜態語言來說,需要傳入引數型別,那么實參則必須是該型別或者子類才可以,而對于動態語言(比如python)來說,甚至不需要非得如此,只需要這個型別里面有個get_name方法即可,這就是動態語言的鴨子特性:只要走路像鴨子,就認為它是鴨子!”這樣的話,多型的實作甚至可以不要求繼承,
裝飾器的使用
裝飾器的本質就是一個Python函式,它可以在其他函式不做任何代碼變化的前提下增強額外功能,裝飾器也回傳一個函式物件,當我們想給很多函式額外添加功能,給每一個添加太麻煩時,就可以使用裝飾器,
比如有幾個函式想給它們添加一個“輸出函式名稱的功能”:
def test():
print("this is test")
print(test.__name__)
test()
但是如果還有其他函式也需要這個功能,那么就要每個都添加一個print,這樣代碼非常冗雜,這時候就可以使用裝飾器,
def log(func):
def wrapper(*args,**kwargs):
print(func.__name__)
return func(*args,**kwargs)
return wrapper
@log # 裝飾器
def test():
print("this is test")
test()
當把@log加到test的定義處時相當于執行了:
test = log(test)
于是乎再執行test()其實就wrapper(),可以得到原本函式的功能以及新添加的功能,非常方便,
還可以定義一個帶引數的裝飾器,這給裝飾器帶來了更大的靈活性:
def log(text):
def decorator(func):
def wrapper(*args, **kwargs):
print(text)
return func(*args, **kwargs)
return wrapper
return decorator
@log("ahahahahaha") # 帶引數的裝飾器
def test():
print("this is test")
這樣就相當于執行了:
test = log("ahahahahaha")(test)
還有一點,雖然裝飾器非常方便,但是這樣使用會導致test的原資訊丟失(比如上面的代碼test.__name__會變成"wrapper"而不是"test"),這樣的話需要匯入一個functool包,然后在wrapper函式前面加上一句@functools.wraps(func)就可以了:
def log(text):
def decorator(func):
@functools.wraps(func) # 加上一句
def wrapper(*args, **kwargs):
print(text)
return func(*args, **kwargs)
return wrapper
return decorator
@log("ahahahahaha")
def test():
print("this is test")
最后,如果一個函式使用多個裝飾器進行裝飾的話,則需要根據邏輯確定裝飾順序,
Python中的多繼承與MRO
Python是允許多繼承的(即一個子類有多個父類),多重繼承的作用主要在于給子類拓展功能:比如dog和cat都是mamal類的子類,它們擁有mamal的功能,如果想給它們添加“runnable”的功能,只需要再繼承一個類runnable即可,這個額外功能的類一般都會加一個“Mixin”后綴作為區分,表示這個類是拓展功能用的:
class Dog(mamal,RunableMixIn,CarnivorousMixIn)
pass
使用Mixin的好處在于不用設計復雜的繼承關系即可拓展類的功能,
多繼承會產生一個問題:如果同時有多個父類都實作了一個方法,那么子類應該呼叫誰的方法呢?這就涉及到MRO(方法決議順序),
在Python3之后,MRO使用的都是C3演算法(不區分經典類和新式類,全部都是新式類),C3演算法首先使用深度優先演算法,先左后右,得到搜索路徑后,只保留“好的結點”,好的結點指的是:該節點之后沒有任何節點繼承自這個節點,
比如說下圖:
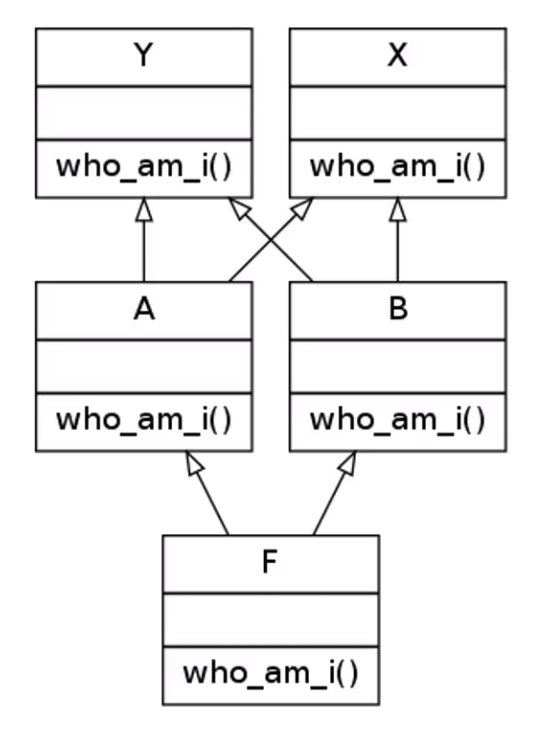
按照深度優先,從左至右的順序應該是F,A,Y,X,B,Y,X,其中第一個Y和第一個X后面B也繼承自Y,X,于是把它們去掉,最終路徑是:F,A,B,Y,X
在MRO中,使用super方法也要注意:假設有類A,B,C,A繼承自B和C,如果B中使用了Super重寫了一個方法,這個方法會在C中去尋找(盡管C并不是B的父類):
class B:
def log(self):
print("log B")
def go(self):
print("go B")
super(B, self).go()
self.log()
class C:
def go(self):
print("go C")
class A(B, C):
def log(self):
print("log A")
super(A,self).log()
if __name__ == "__main__":
a = A()
# 1.a物件執行go,先找自己有沒有go,自己沒有按照MRO去找B
# 2.B中找到了go并執行,super順位查找到c的go,執行,
# 3.然后執行self.log,因為self此時是A物件,于是首先找到A中的log函式執行
# 4.再次執行super函式,此時順位查找到B,執行B.log
a.go()
"結果"
go B
go C
log A
log B
行程與執行緒
以前的單核CPU也可以進行多任務,方法是任務1一會兒,任務2一會兒,任務3一會兒......因為CPU速度很快,所以看起來像是執行了多任務,其實就是交替執行任務,
真正的并行需要在多核CPU上進行,但實際開發中的任務數量一定比核數量要多,所以每個核依舊是在交替執行任務,
行程:對于作業系統來說,一個任務就是一個“行程”,打開一個檔案,程式等都是打開一個“行程”,
當一個程式在硬碟上運行起來,會在記憶體中形成一個獨立的記憶體體,這個記憶體體中有自己獨立的地址空間,有自己的堆,作業系統會以行程為最小的資源分配單位,
執行緒:執行緒是作業系統調度執行的最小單位,有時一個行程會有多個子任務:比如一個word檔案它同時進行打字、編排、拼寫檢查等任務,這些子任務被稱為“執行緒”,每個行程至少要有一個執行緒,和行程一樣,真正的多執行緒只能依靠多核CPU來實作,
行程與執行緒的區別:行程是擁有資源的獨立單位,執行緒不擁有系統資源,但可以訪問自己所隸屬的行程的資源,在系統開銷方面,行程的創建與撤銷都需要系統都要為之分配和回收資源,它的開銷要比執行緒大,
多行程的優點是穩定性高,因為一個行程掛了,其他行程還可以繼續作業,(主行程不能掛,但是由于主行程負責分配任務,所以掛的概率很低),而執行緒呢,由于多執行緒共享一個行程的記憶體,所以一個執行緒掛了全體一起掛,并且多執行緒在操作共享資源時容易出錯(死鎖等問題)
一個執行緒只能屬于一個行程,而一個行程可以有多個執行緒,但至少有一個執行緒;
資源分配給行程,同一行程的所有執行緒共享該行程的所有資源;
處理機分給執行緒,即真正在處理機上運行的是執行緒;
執行緒在執行程序中,需要協作同步,不同行程的執行緒間要利用訊息通信的辦法實作同步
無論是多行程還是多執行緒,一旦任務數量多了效率都會急劇下降,因為切換任務不僅僅是直接去執行就好了,這中間還需要保存現場、創建新環境等一系列操作,如果任務數量一多會有很多時間浪費在這些準備作業上面,
實作多任務主要有三種辦法:
- 多個行程,每個行程僅有一個執行緒
- 一個行程,行程中有多個執行緒
- 多行程多執行緒(過于復雜,不推薦)
同時執行多個任務的時候,任務之間是要互相協調的,有時任務2必須要等任務1結束之后去執行,有時任務3和4不能同時執行......所以多行程和多執行緒撰寫架構要相對更復雜,
任務型別主要分為IO密集型和計算密集型”,計算密集型任務主要是需要大量計算,比如計算圓周率,對視頻解碼等,計算密集型任務主要消耗的是CPU資源(不適合Python這種運算效率低的腳本語言撰寫代碼,適合C語言);而IO密集型任務主要是IO操作,CPU消耗很少,大部分時間都消耗在等待IO,(適合開發效率高的腳本語言)
對于計算密集型任務來說,如果多行程多執行緒任務遠遠大于核數,那么效率反而會急劇下降;而對于IO密集型任務來說,多行程多執行緒可能會好一些,但還是不夠好,
利用異步IO可以實作單行程單執行緒執行多任務,利用異步IO可以顯著提升作業系統的調度效率,對應到Python語言,異步IO被稱為協程,
協程:比執行緒更加輕量級的“微執行緒”,協程不被作業系統內核管理,而是由用戶自己執行,這樣的好處就是極大的提升了調度效率,不會像執行緒那樣切換浪費資源,
子程式在所有語言里都是層級呼叫(堆疊實作),即A呼叫B,B又呼叫C,C完了B完了最后A才能完,一個執行緒就是呼叫一個子程式,而協程不同,用戶可以任意在執行A時暫停去執行B,過一會兒再來執行A,
協程的優勢在于:由于是程式自己控制子程式切換,所以相比執行緒可以節省大量不必要的切換,對于IO密集型任務來說協程更優,而且不需要執行緒的鎖機制,
協程是在單執行緒上執行的,那么如何利用多核CPU呢?方法就是多行程+協程,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/144572.html
標籤:Python