我們在爬取網站的時候,都會遵守 robots 協議,在爬取資料的程序中,盡量不對服務器造成壓力,但并不是所有人都這樣,網路上仍然會有大量的惡意爬蟲,對于網路維護者來說,爬蟲的肆意橫行不僅給服務器造成極大的壓力,還意味著自己的網站資料泄露,甚至是自己刻意隱藏在網站的隱私的內容也會泄露,這也就是反爬蟲技術存在的意義,
開始
先從最基本的requests開始,requests是一常用的http請求庫,它使用python語言撰寫,可以方便地發送http請求,以及方便地處理回應結果,這是一段抓取敢闖網內容的代碼,
import requests
from lxml import etree
url = 'https://www.darecy.com/'
data = https://www.cnblogs.com/darecy/p/requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
這就是最簡單的完整的爬蟲操作,通過代碼發送網路請求,然后決議回傳內容,分析頁面元素,得到自己需要的東西,
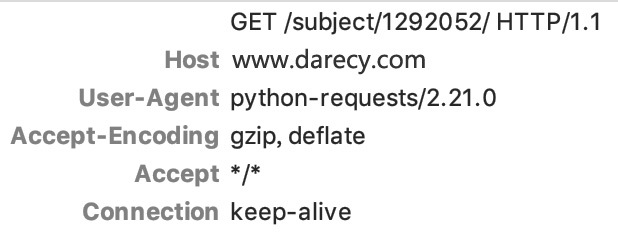
這樣的爬蟲防起來也很容易,使用抓包工具看一下剛才發送的請求,再對比一下瀏覽器發送的正常請求,可以看到,兩者的請求頭差別非常大,尤其requests請求頭中的user-agent,赫然寫著python-requests,這就等于是告訴服務端,這條請求不是真人發的,服務端只需要對請求頭進行一下判斷,就可以防御這一種的爬蟲,
當然requests也不是這么沒用的,它也支持偽造請求頭,以user-agent為例,對剛才的代碼進行修改,就可以很容易地在請求頭中加入你想要加的欄位,偽裝成真實的請求,干擾服務端的判斷,
import requests
from lxml import etree
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
url = 'https://www.darecy.com/'
data = https://www.cnblogs.com/darecy/p/requests.get(url,headers=headers).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
提高
現階段,就網路請求的內容上來說,爬蟲腳本已經和真人一樣了,那么服務器就要從別的角度來進行防御,
有兩個思路,第一個,分析爬蟲腳本的行為模式來進行識別和防御,
爬蟲腳本通常會很頻繁的進行網路請求,針對這種行為模式,服務端就可以對訪問的 IP 進行統計,如果單個 IP 短時間內訪問超過設定的閾值,就給予封鎖,這確實可以防御一批爬蟲,但是也容易誤傷正常用戶,并且爬蟲腳本也可以繞過去,
這時候的爬蟲腳本要做的就是ip代理,每隔幾次請求就切換一下ip,防止請求次數超過服務端設的閾值,設定代理的代碼也非常簡單,
import requests
proxies = {
"http" : "http://108.108.108.108:8899" # 代理ip
}
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
url = 'https://www.darecy.com/'
res = requests.get(url = http_url, headers = headers, proxies = proxies)
第二個思路,通過做一些只有真人能做的操作來識別爬蟲腳本,最典型的就是以12306為代表的驗證碼操作,
增加驗證碼是一個既古老又相當有效果的方法,能夠讓很多爬蟲望風而逃,當然這也不是萬無一失的,經過多年的發展,用計算機視覺進行一些影像識別已經不是什么新鮮事,訓練神經網路的門檻也越來越低,并且有許多開源的計算機視覺庫可以免費使用,
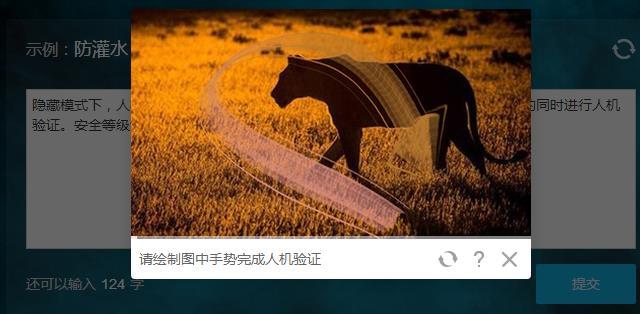
再專業一點的話,還可以加上一些影像預處理的操作,比如降噪和二值化,提高驗證碼的識別準確率,當然要是驗證碼原本的干擾線, 噪點都比較多,甚至還出現了人類肉眼都難以辨別的驗證碼,計算機識別的準確度也會相應下降一些,但這種方法對于真實的人類用戶來說實在是太不友好了,屬于是殺敵一千自損八百的做法,
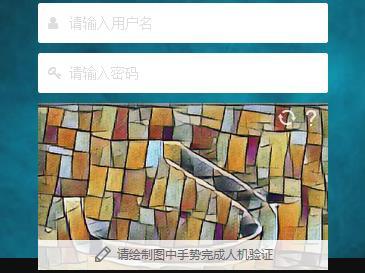
進階
驗證碼的方法雖然防爬效果好,開發人員在優化驗證操作的方面也下了很多工夫,如今,很多的人機驗證操作已經不再需要輸入驗證碼,有些只要一下點擊就可以完成,有些甚至不需要任何操作,在用戶不知道的情況下就能完成驗證,這里其實包含了不同的隱形驗證方法,
有些則更加高級一些,通過檢測出用戶的瀏覽習慣,比如用戶常用 IP 或者滑鼠移動情況等,然后自行判斷人機操作,這樣就用一次點擊取代了繁瑣的驗證碼,而且實際效果還更好,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/146929.html
標籤:Python
上一篇:第一個爬蟲和測驗
下一篇:Python哈希表和決議式