??MongoSpark為入口類,呼叫MongoSpark.load,該方法回傳一個MongoRDD類物件,Mongo Spark Connector框架本質上就是一個大號的自定義RDD,加了些自定義配置、適配幾種磁區器規則、Sql的資料封裝等等,個人認為相對核心的也就是磁區器的規則實作;弄清楚了其分析器也就搞明白了Mongo Spark Connector ,
當前實作的磁區器(Partitioner):
??MongoPaginateByCountPartitioner 基于總數的分頁磁區器
??MongoPaginateBySizePartitioner 基于大小的分頁磁區器
??MongoSamplePartitioner 基于采樣的磁區器
??MongoShardedPartitioner 基于分片的磁區器
??MongoSinglePartitioner 單磁區磁區器
??MongoSplitVectorPartitioner 基于分割向量的磁區器
??這里根據原始碼簡單介紹MongoSinglePartitioner與MongoSamplePartitioner磁區器,這或許就是用得最多的兩種磁區器,他的默認磁區器(DefaultMongoPartitioner)就是MongoSamplePartitioner磁區器;
該磁區默認的PartitionKey為_id、默認PartitionSizeMB為64MB、默認每個磁區采樣為10;
MongoSamplePartitioner
??該類的核心也是唯一的方法為:partitions方法,下面為該方法的執行流程與核心邏輯;
??1、檢查執行buildInfo指令檢查Mongo版本用于判斷是否支持隨機采樣聚合運算,版本大于3.2, hasSampleAggregateOperator方法,Mongo3.2版本中才新增了資料采樣功能,
??Mongodb中的語法為:
db.cName.aggregate([
{$sample:{ size: 10 } }
])
??上示例N等于10,如果N大于collection中總資料的5%,那么$sample將會執行collection掃描、sort,然后選擇top N條檔案;如果N小于5%,對于wiredTiger而言則會遍歷collection并使用“偽隨機”的方式選取N條檔案,對于MMAPv1引擎則在_id索引上隨機選取N條檔案,
??2、執行collStats,用于獲取集合的存盤資訊,如行數、大小、存盤大小等等資訊;
??matchQuery: 過濾條件
??partitionerOptions: ReadConfig傳進去的分析器選項
??partitionKey: 磁區key,默認為_id
??partitionSizeInBytes: 磁區大小,默認64MB
??samplesPerPartition: 每個磁區默認采樣數量,默認10
??count: 集合總條數
??avgObjSizeInBytes: 物件平均位元組數
??numDocumentsPerPartition: 每個磁區檔案數, ??partitionSizeInBytes / avgObjSizeInBytes:磁區大小/物件平均大小
??numberOfSamples: 采樣數量,samplesPerPartition * count / numDocumentsPerPartition,每個磁區采樣數*集合總數/每個磁區檔案數
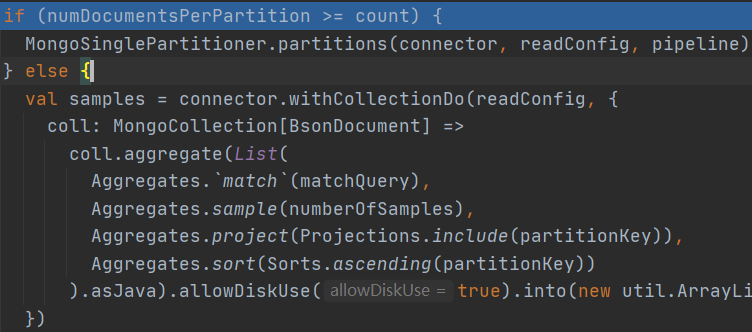
??如每個磁區檔案數大于集合總檔案數,則將直接創建單磁區,不采取采樣資料方式創建磁區,因為此時資料量太少單個磁區已經可以容得下無需多個磁區;
一、創建單磁區
??在MongoSinglePartitioner類中通過PartitionerHelper.createPartitions執行相關邏輯;
??_id作為partitionKey,
二、通過采樣資料創建磁區
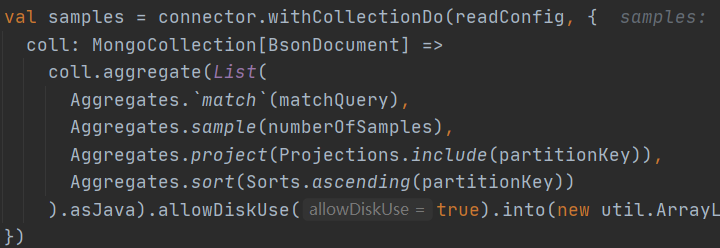
??指定采樣條件、采樣資料量、PartitionKey、排序條件等,獲取采樣資料;
集合拆分:
def collectSplit(i: Int): Boolean = (i % samplesPerPartition == 0) || !matchQuery.isEmpty && i == count – 1
右側邊界:
val rightHandBoundaries = samples.zipWithIndex.collect {
case (field, i) if collectSplit(i) => field.get(partitionKey)
}
??獲取右側邊界,使用采樣資料陣列索引對每個磁區采樣數求余等于0對采樣資料進行過濾取右側邊界(如匹配條件不為空則再取最后一條資料);
??如采樣得到62條資料,并且沒有存在匹配條件,根據上述的采樣資料過濾條件最后取得7條資料,分別為資料陣列索引為0、索引為10、20、30、40、50、60的7條資料,資料的值為PartitionKey默認就是集合中_id欄位的值;
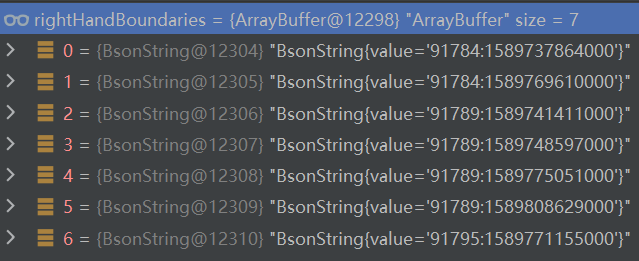
創建磁區(Partitions)
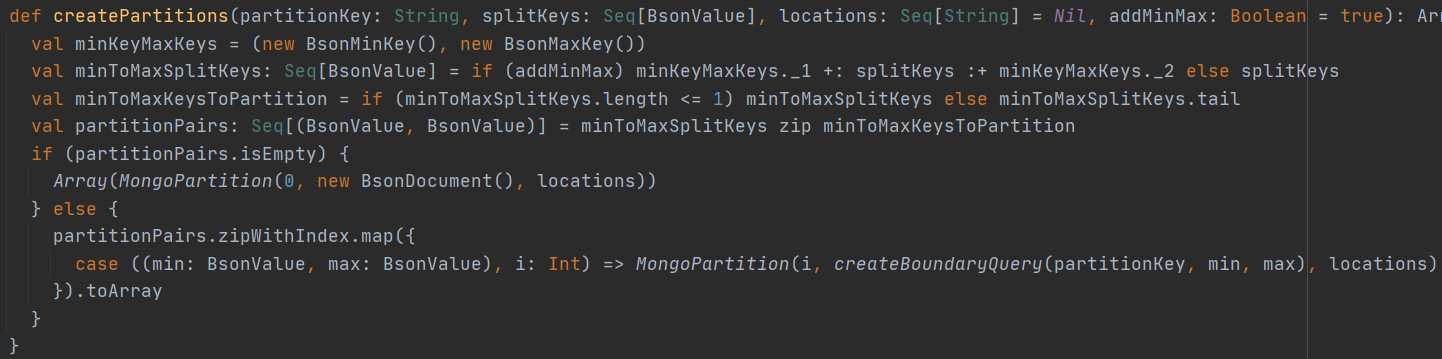
??獲取得到PartitionKey、rightHandBoundaries后就可以呼叫PartitionerHelper.createPartitions創建Partition;下面為創建Partition的具體邏輯;
??使用PartitionKey創建查詢邊界,每個磁區具有不同的查詢邊界,有最大、最小邊界; 此處創建磁區Partition并在每個磁區中指定了查詢邊界;
??上面獲取得到了7條資料,此處將創建8個磁區;下面給出了簡單資料用于說明該磁區邊界條件的基本邏輯與實作;
??1、創建Min、1、3、5、7、9、11、13、Max的序列
??2、創建1、3、5、7、9、11、13、Max序列
??3、使用zip將兩個序列拉鏈式的合并:合并后的資料為:
??4、Min,1、1,3、3,5、5,7、7,9、9,11、11,13、13,Max
??Partition的邊界條件將使用上面的邊界條件,8條資料八個Partition一個對應;
??0 Partition的邊界條件為:小于1
??1 Partition的邊界條件為:大于等于1 小于 3
??2 Partition的邊界條件為:大于等于3 小于 5
??3 Partition的邊界條件為:大于等于5 小于 7
??4 Partition的邊界條件為:大于等于7小于 9
??5 Partition的邊界條件為:大于等于9 小于 11
??6 Partition的邊界條件為:大于等于11 小于 13
??7 Partition的邊界條件為:大于等于13
??上面的8個Partition為8個MongoPartition物件,每個物件的index、查詢邊界與上面所說的一一對應;
??在MongoRDD類的compute方法中可以看到根據對應的磁區與上面創建磁區時所建立的邊界條件用于計算(從Mongo中獲取對應資料);
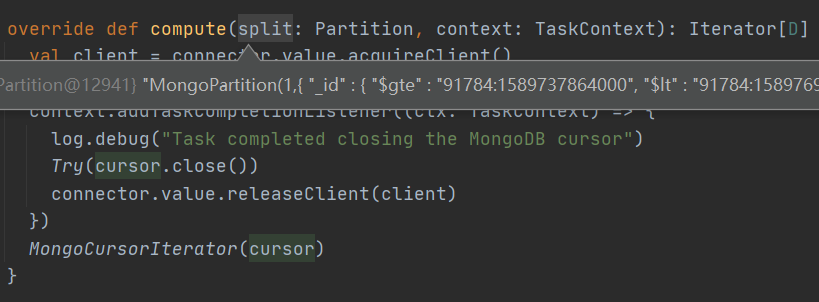
MongoSinglePartitioner
??創建單磁區磁區器時,直接呼叫PartitionerHelper.createPartitions方法創建磁區,該類并無其他邏輯,并且固定的PartitionKey為_id,右側邊界條件為空集合,然后創建id為0的MongoPartition物件,并無查詢邊界;
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/156150.html
標籤:Java