前言
只有光頭才能變強,
文本已收錄至我的GitHub精選文章,歡迎Star:https://github.com/ZhongFuCheng3y/3y
在我還不了解分布式和大資料的時候已經聽說過HBase了,但對它一直都半知不解,這篇文章來講講吧,
在真實生活中,最開始聽到這個詞是我的一場面試,當年我還是個『小垃圾』,現在已經是個『大垃圾』了,
面試官當時給了一個場景題問我,具體的題目我忘得差不多了,大概就是考試與試題的一個場景,問我資料庫要如何設計,
我答了關系型資料庫的設計方案,他大概說:這個場景比較復雜多變,為什么不考慮一下HBase這種NoSQL的資料庫來存盤呢?
我就說:“對對對,可以的” (雖然我當時不知道HBase是什么,但是氣勢一定要有,你們說是不是)

最后面試官還是給我發了offer,但我沒去,原因就是離家太遠了,
一、介紹HBase
Apache HBase? is the Hadoop database, a distributed, scalable, big data store.
HBase is a type of "NoSQL" database.
Apache HBase 是 Hadoop 資料庫,一個分布式、可伸縮的大資料存盤,
HBase是依賴Hadoop的,為什么HBase能存盤海量的資料?因為HBase是在HDFS的基礎之上構建的,HDFS是分布式檔案系統,
二、為什么要用HBase
截至到現在,三歪已經學了不少的組件了,比如說分布式搜索引擎「Elasticsearch」、分布式檔案系統「HDFS」、分布式訊息佇列「Kafka」、快取資料庫「Redis」等等...
能夠處理資料的中間件(系統),這些中間件基本都會有持久化的功能,為什么?如果某一個時刻掛了,那還在記憶體但還沒處理完的資料不就涼了?
Redis有AOF和RDB、Elasticsearch會把資料寫到translog然后結合FileSystemCache將資料刷到磁盤中、Kafka本身就是將資料順序寫到磁盤....
這些中間件會實作持久化(像HDFS和MySQL我們本身就用來存盤資料的),為什么我們還要用HBase呢?
雖然沒有什么可比性,但是在學習的時候總會有一個疑問:「既然已學過的系統都有類似的功能了,那為啥我還要去學這個玩意?」
三歪是這樣理解的:
- MySQL?MySQL資料庫我們是算用得最多了的吧?但眾所周知,MySQL是單機的,MySQL能存盤多少資料,取決于那臺服務器的硬碟大小,以現在互聯網的資料量,很多時候MySQL是沒法存盤那么多資料的,
- 比如我這邊有個系統,一天就能產生1TB的資料,這資料是不可能存MySQL的,(如此大的量資料,我們現在的做法是先寫到Kafka,然后落到Hive中)
- Kafka?Kafka我們主要用來處理訊息的(解耦異步削峰),資料到Kafka,Kafka會將資料持久化到硬碟中,并且Kafka是分布式的(很方便的擴展),理論上Kafka可以存盤很大的資料,但是Kafka的資料我們不會「單獨」取出來,持久化了的資料,最常見的用法就是重新設定offset,做「回溯」操作
- Redis?Redis是快取資料庫,所有的讀寫都在記憶體中,速度賊快,AOF/RDB存盤的資料都會加載到記憶體中,Redis不適合存大量的資料(因為記憶體太貴了!),
- Elasticsearch?Elasticsearch是一個分布式的搜索引擎,主要用于檢索,理論上Elasticsearch也是可以存盤海量的資料(畢竟分布式),我們也可以將資料用『索引』來取出來,似乎已經是非常完美的中間件了,
- 但是如果我們的資料沒有經常「檢索」的需求,其實不必放到Elasticsearch,資料寫入Elasticsearch需要分詞,無疑會浪費資源,
- HDFS?顯然HDFS是可以存盤海量的資料的,它就是為海量資料而生的,它也有明顯的缺點:不支持隨機修改,查詢效率低,對小檔案支持不友好,
上面這些技術堆疊三歪都已經寫過文章了,學多了你會發現它們的持久化機制都差不太多,有空再來總結一下,

文中的開頭已經說了,HBase是基于HDFS分布式檔案系統去構建的,換句話說,HBase的資料其實也是存盤在HDFS上的,那肯定有好奇寶寶就會問:HDFS和HBase有啥區別阿?
HDFS是檔案系統,而HBase是資料庫,其實也沒啥可比性,「你可以把HBase當做是MySQL,把HDFS當做是硬碟,HBase只是一個NoSQL資料庫,把資料存在HDFS上」,
資料庫是一個以某種有組織的方式存盤的資料集合,
扯了這么多,那我們為啥要用HBase呢?HBase在HDFS之上提供了高并發的隨機寫和支持實時查詢,這是HDFS不具備的,
我一直都說在學習某一項技術之前首先要了解它能干什么,如果僅僅看上面的”對比“,我們可以發現HBase可以以低成本來存盤海量的資料并且支持高并發隨機寫和實時查詢,
但HBase還有一個特點就是:存盤資料的”結構“可以地非常靈活(這個下面會講到,這里如果沒接觸過HBase的同學可能不知道什么意思),
三、入門HBase
聽過HBase的同學可能都聽過「列式存盤」這個詞,我最開始的時候覺得HBase很難理解,就因為它這個「列式存盤」我一直理解不了它為什么是「列式」的,
在網上也有很多的博客去講解什么是「列式」存盤,它們會舉我們現有的資料庫,比如MySQL,存盤的結構我們很容易看懂,就是一行一行資料嘛,
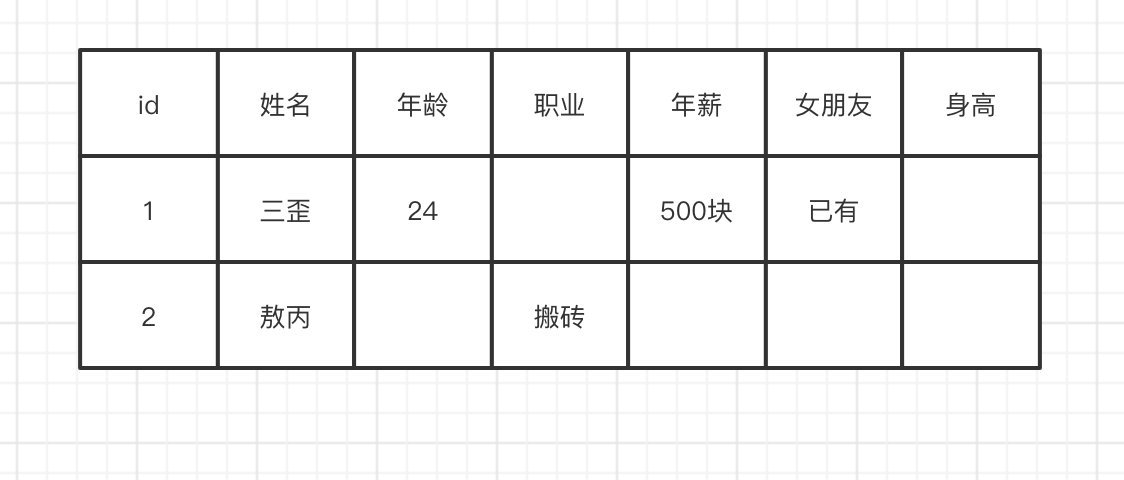
轉換成所謂的列式存盤是什么樣的呢?
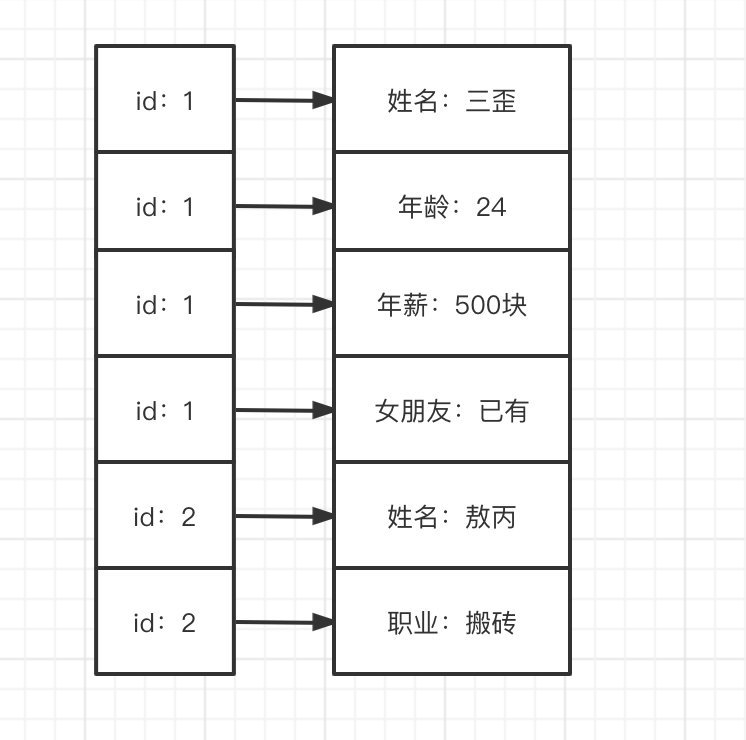
可以很簡單的發現,無非就是把每列抽出來,然后關聯上Id,這個叫列式存盤嗎?我在這打個問號,
轉換后的資料從我的角度來看,資料還是一行一行的,
這樣做有什么好處嗎?很明顯以前我們一行記錄多個屬性(列),有部分的列是空缺的,但是我們還是需要空間去存盤,現在把這些列全部拆開,有什么我們就存什么,這樣空間就能被我們充分利用,
這種形式的資料更像什么?明顯是Key-Value嘛,那我們該怎么理解HBase所謂的列式存盤和Key-Value結構呢?走進三歪的小腦袋,一探究竟,
3.1 HBase的資料模型
在看HBase資料模型的時候,其實最好還是不要用「關系型資料庫」的知識去理解它,
In HBase, data is stored in tables, which have rows and columns. This is a terminology overlap withrelational databases (RDBMSs), but this is not a helpful analogy.
HBase里邊也有表、行和列的概念,
- 表沒什么好說的,就是一張表
- 一行資料由一個行鍵和一個或多個相關的列以及它的值所組成
好了,現在比較抽象了,在HBase里邊,定位一行資料會有一個唯一的值,這個叫做行鍵(RowKey),而在HBase的列不是我們在關系型資料庫所想象中的列,
HBase的列(Column)都得歸屬到列族(Column Family)中,在HBase中用列修飾符(Column Qualifier)來標識每個列,
在HBase里邊,先有列族,后有列,
什么是列族?可以簡單理解為:列的屬性類別
什么是列修飾符?先有列族后有列,在列族下用列修飾符來標識一列,
還很抽象是不是?三歪來畫個圖:
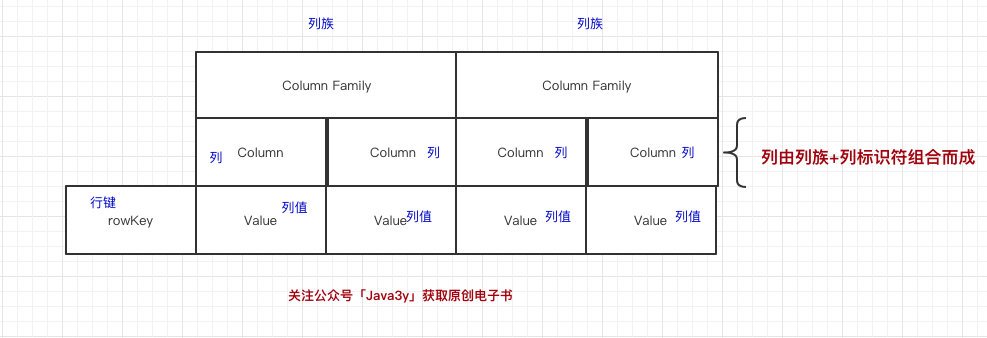
我們再放點具體的值去看看,就更加容易看懂了:

這張表我們有兩個列族,分別是UserInfo和OrderInfo,在UserInfo下有兩個列,分別是UserInfo:name和UserInfo:age,在OrderInfo下有兩個列,分別是OrderInfo:orderId和OrderInfo:money,
UserInfo:name的值為:三歪,UserInfo:age的值為24,OrderInfo:orderId的值為23333,OrderInfo:money的值為30,這些資料的主鍵(RowKey)為1
上面的那個圖看起來可能不太好懂,我們再畫一個我們比較熟悉的:
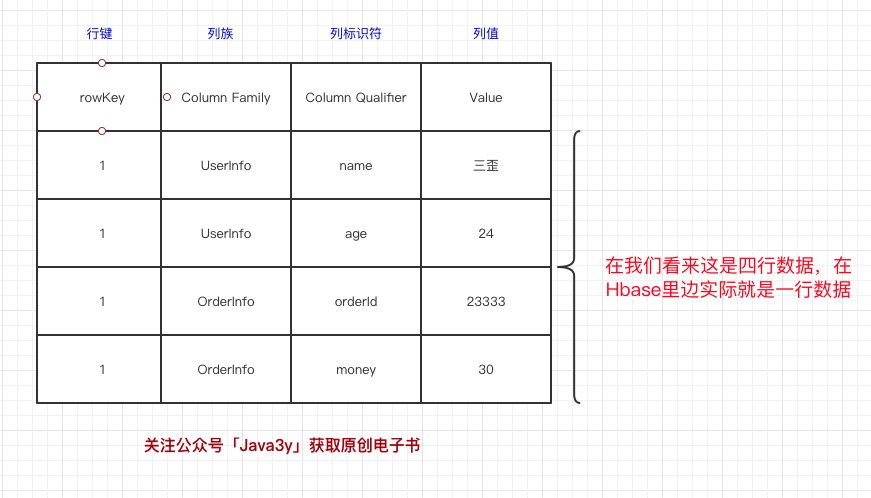
HBase表的每一行中,列的組成都是靈活的,行與行之間的列不需要相同,如圖下:
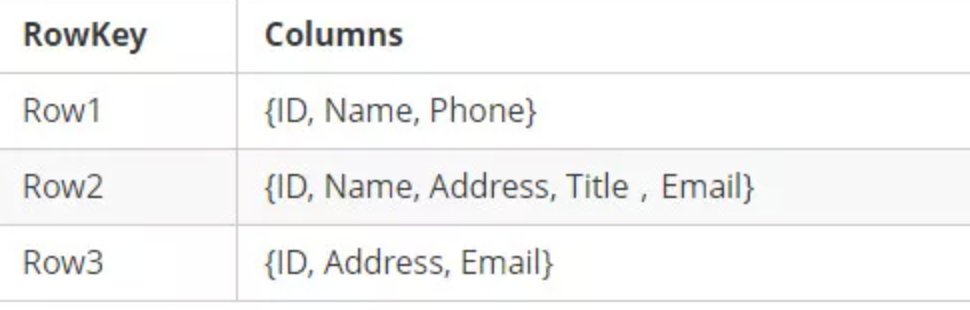

換句話說:一個列族下可以任意添加列,不受任何限制
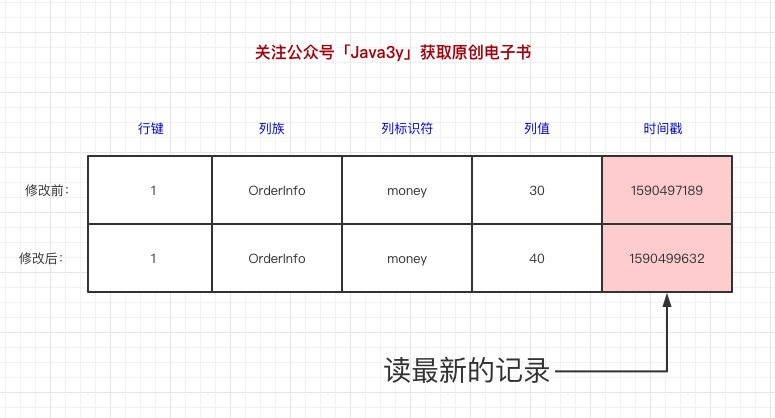
資料寫到HBase的時候都會被記錄一個時間戳,這個時間戳被我們當做一個版本,比如說,我們修改或者洗掉某一條的時候,本質上是往里邊新增一條資料,記錄的版本加一了而已,
比如現在我們有一條記錄:

現在要把這條記錄的值改為40,實際上就是多添加一條記錄,在讀的時候按照時間戳讀最新的記錄,在外界「看起來」就是把這條記錄改了,
3.2 HBase 的Key-Value
HBase本質上其實就是Key-Value的資料庫,上一次我們學Key-Value資料庫還是Redis呢,那在HBase里邊,Key是什么?Value是什么?
我們看一下下面的HBaseKey-Value結構圖:
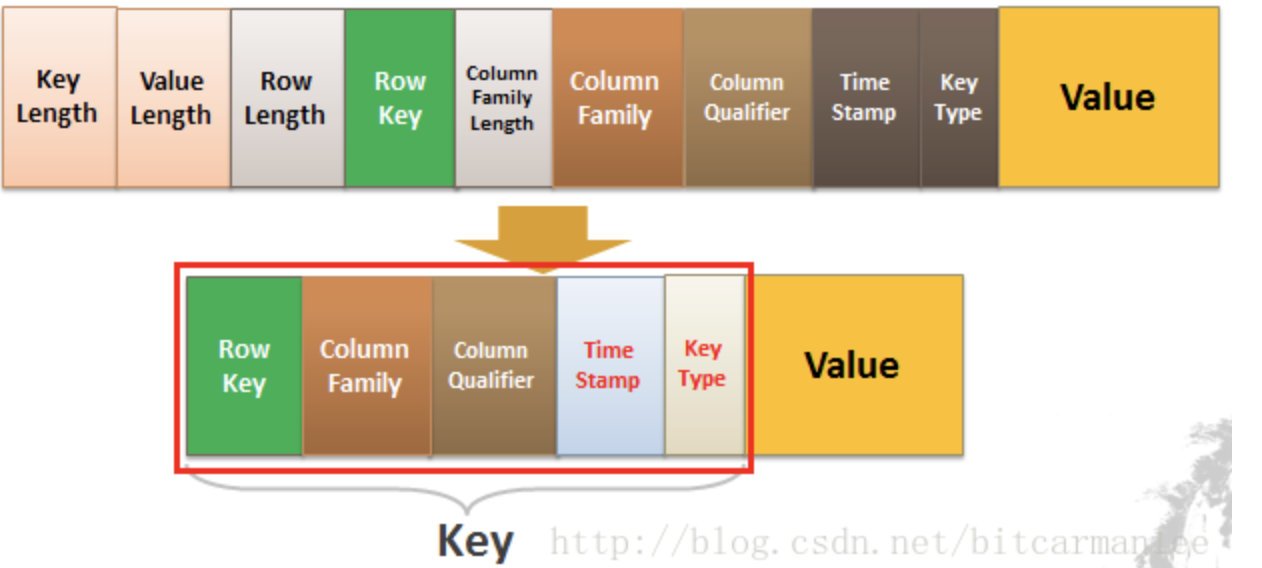
Key由RowKey(行鍵)+ColumnFamily(列族)+Column Qualifier(列修飾符)+TimeStamp(時間戳--版本)+KeyType(型別)組成,而Value就是實際上的值,
對比上面的例子,其實很好理解,因為我們修改一條資料其實上是在原來的基礎上增加一個版本的,那我們要準確定位一條資料,那就得(RowKey+Column+時間戳),
KeyType是什么?我們上面只說了「修改」的情況,你們有沒有想過,如果要洗掉一條資料怎么做?實際上也是增加一條記錄,只不過我們在KeyType里邊設定為“Delete”就可以了,
3.3 HBase架構
扯了這么一大堆,已經說了HBase的資料模型和Key-Value了,我們還有一個問題:「為什么經常會有人說HBase是列式存盤呢?」
其實HBase更多的是「列族存盤」,要談列族存盤,就得先了解了解HBase的架構是怎么樣的,
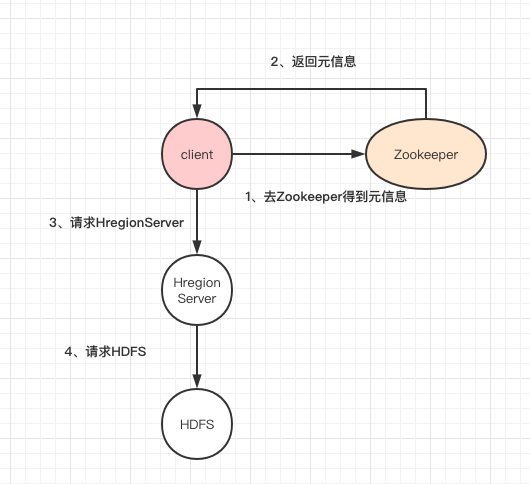
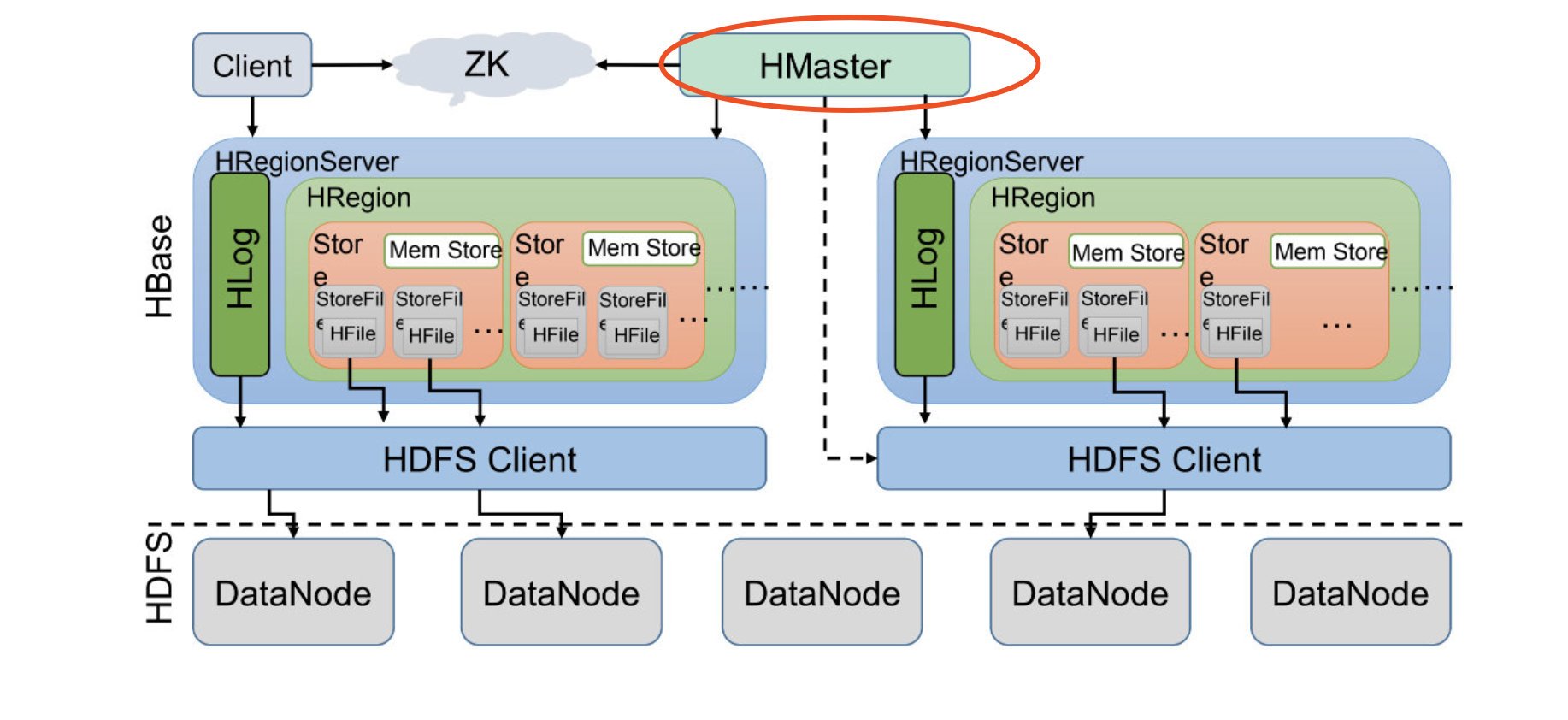
我們先來看看HBase的架構圖:
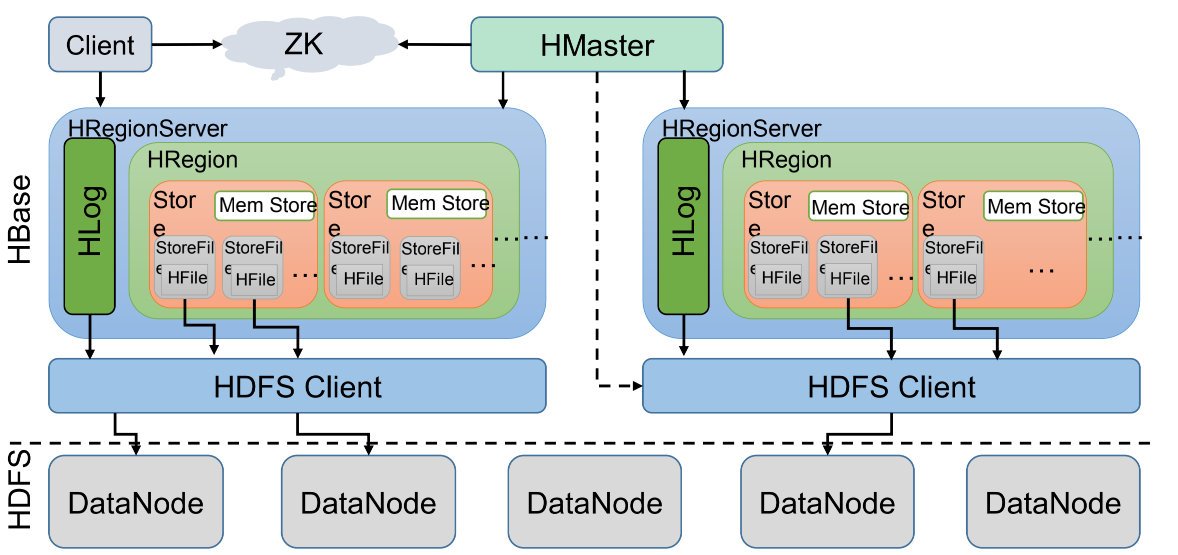
1、Client客戶端,它提供了訪問HBase的介面,并且維護了對應的cache來加速HBase的訪問,
2、Zookeeper存盤HBase的元資料(meta表),無論是讀還是寫資料,都是去Zookeeper里邊拿到meta元資料告訴給客戶端去哪臺機器讀寫資料
3、HRegionServer它是處理客戶端的讀寫請求,負責與HDFS底層互動,是真正干活的節點,
總結大致的流程就是:client請求到Zookeeper,然后Zookeeper回傳HRegionServer地址給client,client得到Zookeeper回傳的地址去請求HRegionServer,HRegionServer讀寫資料后回傳給client,
3.4 HRegionServer內部
我們來看下面的圖:
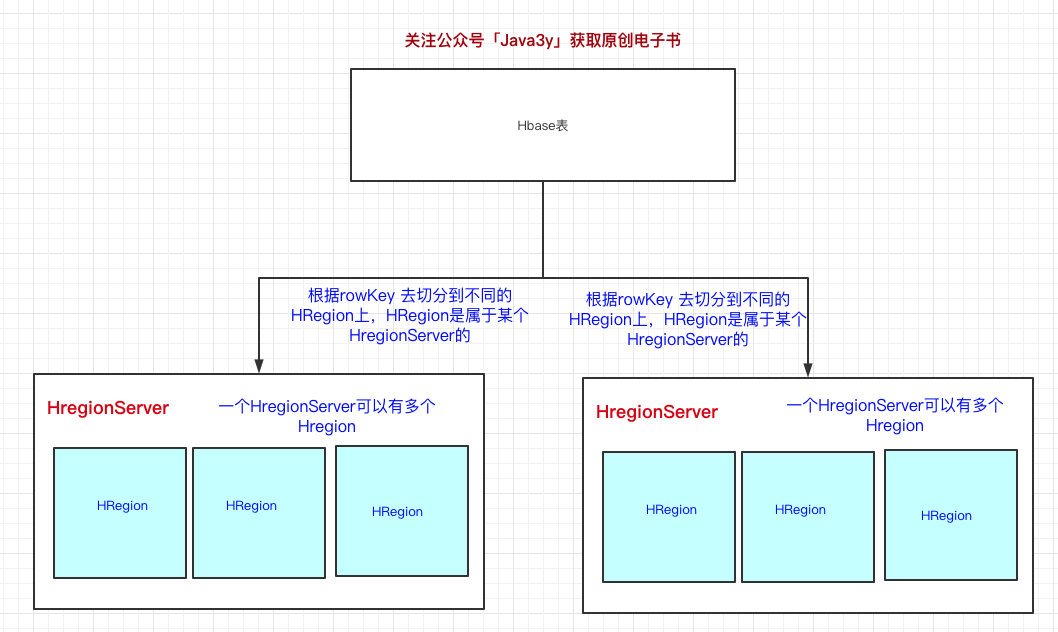
前面也提到了,HBase可以存盤海量的資料,HBase是分布式的,所以我們可以斷定:HBase一張表的資料會分到多臺機器上的,那HBase是怎么切割一張表的資料的呢?用的就是RowKey來切分,其實就是表的橫向切割,
說白了就是一個HRegion上,存盤HBase表的一部分資料,
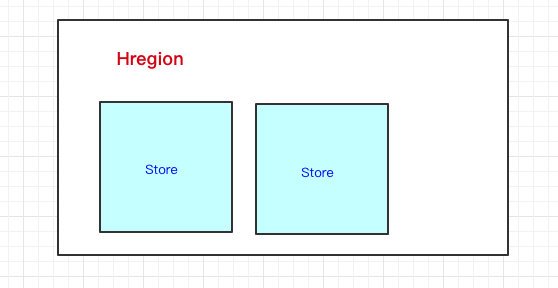
HRegion下面有Store,那Store是什么呢?我們前面也說過,一個HBase表首先要定義列族,然后列是在列族之下的,列可以隨意添加,
一個列族的資料是存盤在一起的,所以一個列族的資料是存盤在一個Store里邊的,
看到這里,其實我們可以認為HBase是基于列族存盤的(畢竟物理存盤,一個列族是存盤到同一個Store里的)
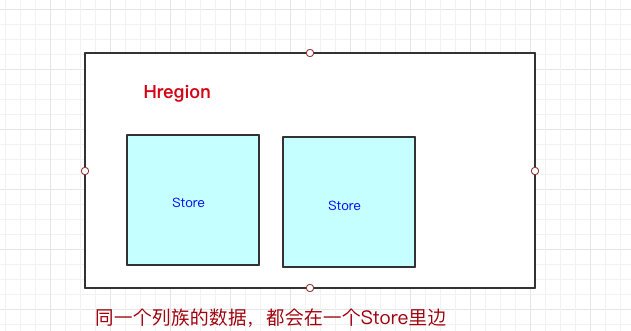
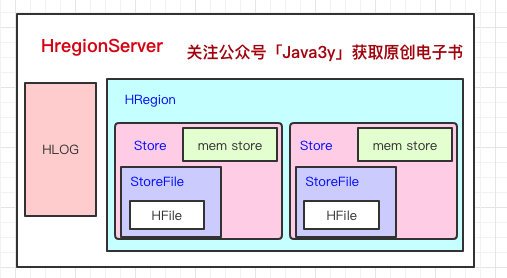
Store里邊有啥?有Mem Store、Store File、HFile,我們再來看看里邊都代表啥含義,
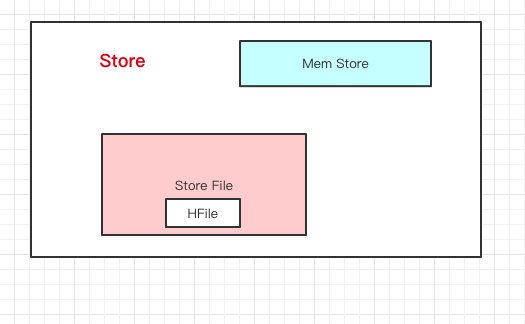
HBase在寫資料的時候,會先寫到Mem Store,當MemStore超過一定閾值,就會將記憶體中的資料刷寫到硬碟上,形成StoreFile,而StoreFile底層是以HFile的格式保存,HFile是HBase中KeyValue資料的存盤格式,
所以說:Mem Store我們可以理解為記憶體 buffer,HFile是HBase實際存盤的資料格式,而StoreFile只是HBase里的一個名字,
回到HRegionServer上,我們還漏了一塊,就是HLog,
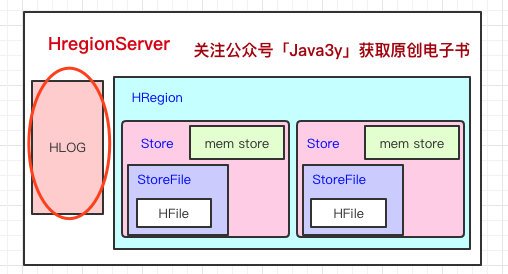
這里其實特別好理解了,我們寫資料的時候是先寫到記憶體的,為了防止機器宕機,記憶體的資料沒刷到磁盤中就掛了,我們在寫Mem store的時候還會寫一份HLog,
這個HLog是順序寫到磁盤的,所以速度還是挺快的(是不是有似曾相似的感覺)...
稍微總結一把:
- HRegionServer是真正干活的機器(用于與hdfs互動),我們HBase表用RowKey來橫向切分表
- HRegion里邊會有多個Store,每個Store其實就是一個列族的資料(所以我們可以說HBase是基于列族存盤的)
- Store里邊有Men Store和StoreFile(HFile),其實就是先走一層記憶體,然后再刷到磁盤的結構
3.5 被遺忘的HMaster
我們在上面的圖會看到有個Hmaster,它在HBase的架構中承擔一種什么樣的角色呢?讀寫請求都沒經過Hmaster呀,
那HMaster在HBase里承擔什么樣的角色呢??
HMasteris the implementation of the Master Server. The Master server is responsible for monitoring all RegionServer instances in the cluster, and is the interface for all metadata changes.
HMaster會處理 HRegion 的分配或轉移,如果我們HRegion的資料量太大的話,HMaster會對拆分后的Region重新分配RegionServer,(如果發現失效的HRegion,也會將失效的HRegion分配到正常的HRegionServer中)
HMaster會處理元資料的變更和監控RegionServer的狀態,
四、RowKey的設計
到這里,我們已經知道RowKey是什么了,不難理解的是,我們肯定是要保證RowKey是唯一的,畢竟它是行鍵,有了它我們才可以唯一標識一條資料的,
在HBase里邊提供了三種的查詢方式:
- 全域掃描
- 根據一個RowKey進行查詢
- 根據RowKey過濾的范圍查詢
4.1 根據一個RowKey查詢
首先我們要知道的是RowKey是會按字典序排序的,我們HBase表會用RowKey來橫向切分表,
無論是讀和寫我們都是用RowKey去定位到HRegion,然后找到HRegionServer,這里有一個很關鍵的問題:那我怎么知道這個RowKey是在這個HRegion上的?
HRegion上有兩個很重要的屬性:start-key和end-key,
我們在定位HRegionServer的時候,實際上就是定位我們這個RowKey在不在這個HRegion的start-key和end-key范圍之內,如果在,說明我們就找到了,
這個時候會帶來一個問題:由于我們的RowKey是以字典序排序的,如果我們對RowKey沒有做任何處理,那就有可能存在熱點資料的問題,
舉個例子,現在我們的RowKey如下:
java3y111
java3y222
java3y333
java3y444
java3y555
aaa
bbb
java3y777
java3y666
java3y...
Java3yxxx開頭的RowKey很多,而其他的RowKey很少,如果我們有多個HRegion的話,那么存盤Java3yxxx的HRegion的資料量是最大的,而分配給其他的HRegion數量是很少的,
關鍵是我們的查詢也幾乎都是以java3yxxx的資料去查,這會導致某部分資料會集中在某臺HRegionServer上存盤以及查詢,而其他的HRegionServer卻很空閑,
如果是這種情況,我們要做的是什么?對RowKey散列就好了,那分配到HRegion的時候就比較均勻,少了熱點的問題,
HBase優化手冊:
建表申請時的預磁區設定,對于經常使用HBase的小伙伴來說,HBase管理平臺里申請HBase表流程必然不陌生了,
'給定split的RowKey組例如:aaaaa,bbbbb,ccccc;或給定例如:startKey=00000000,endKey=xxxxxxxx,regionsNum=x'
第一種方式:
是自己指定RowKey的分割點來劃分region個數.比如有一組資料RowKey為[1,2,3,4,5,6,7],此時給定split RowKey是3,6,那么就會劃分為[1,3),[3,6),[6,7)的三個初始region了.如果對于RowKey的組成及資料分布非常清楚的話,可以使用這種方式精確預磁區.
第二種方式 :
如果只是知道RowKey的組成大致的范圍,可以選用這種方式讓集群來均衡預磁區,設定始末的RowKey,以及根據資料量給定大致的region數,一般建議region數最多不要超過集群的rs節點數,過多region數不但不能增加表訪問性能,反而會增加master節點壓力.如果給定始末RowKey范圍與實際偏差較大的話,還是比較容易產生資料熱點問題.
最后:生成RowKey時,盡量進行加鹽或者哈希的處理,這樣很大程度上可以緩解資料熱點問題.
4.2根據RowKey范圍查詢
上面的情況是針對通過RowKey單個查詢的業務的,如果我們是根據RowKey范圍查詢的,那沒必要上面那樣做,
HBase將RowKey設計為字典序排序,如果不做限制,那很可能類似的RowKey存盤在同一個HRegion中,那我正好有這個場景上的業務,那我查詢的時候不是快多了嗎?在同一個HRegion就可以拿到我想要的資料了,
舉個例子:我們會間隔幾秒就采集直播間熱度,將這份資料寫到HBase中,然后業務方經常要把主播的一段時間內的熱度給查詢出來,
我設計好的RowKey,將該主播的一段時間內的熱度都寫到同一個HRegion上,拉取的時候只要訪問一個HRegionServer就可以得到全部我想要的資料了,那查詢的速度就快很多,
最后
最后三歪再來帶著大家回顧一下這篇文章寫了什么:
- HBase是一個NoSQL資料庫,一般我們用它來存盤海量的資料(因為它基于HDFS分布式檔案系統上構建的)
- HBase的一行記錄由一個RowKey和一個或多個的列以及它的值所組成,先有列族后有列,列可以隨意添加,
- HBase的增刪改記錄都有「版本」,默認以時間戳的方式實作,
- RowKey的設計如果沒有特殊的業務性,最好設計為散列的,這樣避免熱點資料分布在同一個HRegionServer中,
- HBase的讀寫都經過Zookeeper去拉取meta資料,定位到對應的HRegion,然后找到HRegionServer
參考資料:
- https://blog.csdn.net/bitcarmanlee/article/details/78979836
- https://hbase.apache.org/book.html#arch.overview
- https://zhuanlan.zhihu.com/p/54184168
- 硬核干貨長文!Hbase來了解一下不?
- https://www.jianshu.com/p/569106a3008f
- 趣談Hbase架構
- https://www.cnblogs.com/BIG-BOSS-ZC/p/11807304.html
- 一條資料的HBase之旅,簡明HBase入門教程-開篇
- https://chenhy.com/post/hbase-quickstart/
- https://www.cnblogs.com/zmoumou/p/10292676.html
- https://www.cnblogs.com/duanxz/p/3154487.html
- https://www.jianshu.com/p/4e412f48e820
- HBase 基本入門篇
- 什么是列式存盤?
各類知識點總結
下面的文章都有對應的原創精美PDF,在持續更新中,可以來找我催更~
- 92頁的Mybatis
- 129頁的多執行緒
- 141頁的Servlet
- 158頁的JSP
- 76頁的集合
- 64頁的JDBC
- 105頁的資料結構和演算法
- 142頁的Spring
- 58頁的過濾器和監聽器
- 30頁的HTTP
- 42頁的SpringMVC
- Hibernate
- AJAX
- Redis
- ......
涵蓋Java后端所有知識點的開源專案(已有8K+ star):
- GitHub
- Gitee訪問更快
給三歪點個贊,對三歪真的非常重要!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/174390.html
標籤:Java
上一篇:JAVA基礎入門到精通(階段一)