阿里云的課程有邏輯回歸的內容的,學一下,
原理
分類變數:又稱定性變數或離散變數,觀察個體只能屬于互不相容的類別中的一組,一般用非數字表達,與之相對的是定量變數或連續變數,變數具有數值特征,
常見的有有序變數(年齡等級,收入等級等),名義變數(性別,天氣,職業等),
自變數包含分類變數:名義變數通常使用虛擬變數(啞變數),有序變數通過選取連續函式構建位置結構模型或者規則結構模型,
因變數包含分類變數:通常不滿足回歸分析的基本假設,通常使用新的回歸方法,
問題:誤差項非正態分布;誤差項零均值異方差;回歸方程有限制,
改進:①回歸函式改用限制在[0,1]之間的連續曲線,而不再是直線回歸方程,常用的是logistic函式(或稱sigmoid函式),其形式為f(x) = 1/(1+1/e**-x)
因變數取值為0,1,不適合直接作為回歸的因變數,改用因變數取值為1的概率π作為回歸因變數,因此也叫線性概率模型,
使用logit變換可以將logistic函式變換為線性函式,
用最大似然法估計引數值,
求解用到了梯度法,
梯度:是一個向量,表示某一函式在該點處的方向導數沿著該方向取得最大值,即函式在該點處沿著該方向變化最快,變化率最大,
梯度下降法:一種最優化演算法,也稱為最速下降法,沿著負梯度方向去減小函式值從而接近目標值,求最小值,
梯度上升法:一種最優化演算法,也稱最速上升法,沿著梯度方向去增加函式值從而接近目標值,求最大值,又有批量梯度上升法,隨機梯度上升法等,小批量梯度上升法,
回圈終止條件:設定回圈閾值,當兩次迭代值之差小于閾值時停止,或者定義最大回圈次數,到達后即終止,
邏輯回歸的基本假設
①因變數是二分類的分類變數,或某事件的發生率,并且是數值型變數,
②殘差和因變數都要服從二項分布,二項分布對應的是分類變數,所以不是正態分布,進而不是用最小二乘法,而是最大似然法來解決方程估計和檢驗問題,
③自變數和logistic概率是線性關系,
④各觀測物件之間相互獨立,共線性問題會影響邏輯回歸的引數估計和預測,
對于多分類變數,也可以轉化為多個二項邏輯回歸解決,還可以使用softmax作為損失函式,將輸出映射到(0,1),
用sklearn自帶的iris資料集實測一下,
代碼見https://github.com/zwdnet/MyQuant/blob/master/20/logist.py
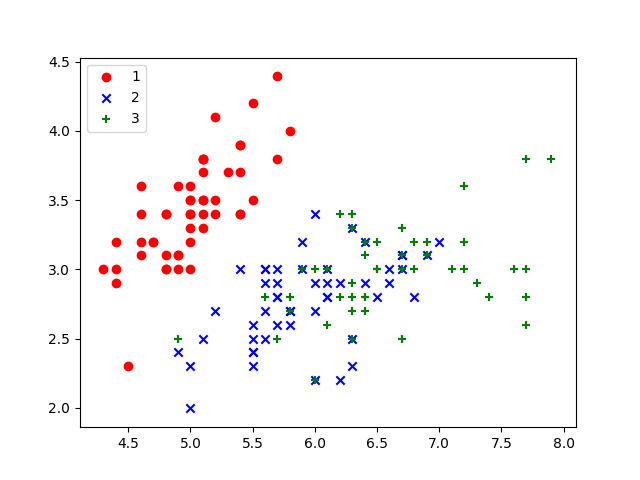
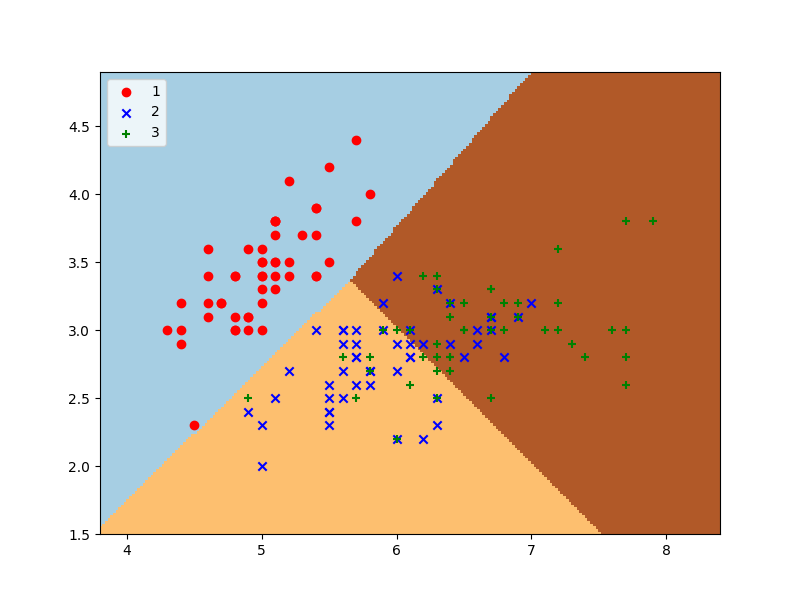
模型的評估、診斷與調優
構造統計量,用卡方檢驗,回歸系數的檢驗構造Wald統計量,用卡方檢驗,或者計算擬合優度,自變數篩選與線性回歸類似,前進法,后退法,逐步回歸法,
除了與線性回歸共有的問題,邏輯回歸還有過離散,空單元,完全分類等特有的問題,
sklearn貌似還是不能進行統計檢驗,看看分數吧,
0.8066666666666666 還不錯,
我發文章的四個地方,歡迎大家在朋友圈等地方分享,歡迎點“在看”,
我的個人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客園博客地址: https://www.cnblogs.com/zwdnet/
我的微信個人訂閱號:趙瑜敏的口腔醫學學習園地
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/189225.html
標籤:Python
下一篇:web自動化之三大等待