一、讀寫分離背景
分庫分表雖然可以優化資料庫操作,但是要實作高并發,主從架構就應運而生了,資料庫的主從復制架構,將資料庫的寫操作定位到主庫中進行,主庫和從庫之間通過異步復制、半同步復制保持資料一致,所有的讀操作都在主庫的N個從庫上進行,通過負載均衡使得每一次查詢均勻的落在每一個從庫上,
一主n從,做讀寫分離(資料寫入主庫,通過mysql資料同步機制將主庫資料同步到從庫–>程式讀取從庫資料),多個從庫之間可以實作負載均衡,次外,ShardingSphere-ShardingJdbc可手動強制部分讀請求到主庫上,(因為主從同步有延遲,對實時性要求高的系統,可以將部分讀請求也走主庫)
MySQL配置主從同步可參考另一篇博客:https://blog.csdn.net/u014553029/article/details/108832268
二、讀寫分離實作
2.1 環境準備
程式環境:SpringBoot+MyBatis-plus
資料庫環境:
| 資料庫ip | 資料庫 | 作用 |
|---|---|---|
| 127.0.0.1 | ShardingSphere | master |
| 127.0.0.1 | ShardingSphere1 | slave1 |
| 127.0.0.1 | ShardingSphere2 | slave2 |
2.2 添加ShardingSphere依賴
<!--shardingsphere資料分片、脫敏工具-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.0</version>
</dependency>
2.3 配置讀寫分離規則
#### spring ####
spring:
# 配置說明地址 https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-spring-boot/#%E6%95%B0%E6%8D%AE%E5%88%86%E7%89%87
shardingsphere:
# 資料庫
datasource:
# 資料庫的別名
names: ds0,ds1,ds2
# 主庫1 ,master資料庫
ds0:
### 資料源類別
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shardingsphere?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&serverTimezone=GMT%2B8
username: root
password: 123456
# 從庫1 ,slave資料庫
ds1:
### 資料源類別
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shardingsphere1?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&serverTimezone=GMT%2B8
username: root
password: 123456
# 從庫2 ,slave資料庫
ds2:
### 資料源類別
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shardingsphere2?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&serverTimezone=GMT%2B8
username: root
password: 123456
# *** 資料庫分庫分表配置 start
masterslave:
# 查詢時的負載均衡演算法,目前有2種演算法,round_robin(輪詢)和random(隨機),
# 演算法介面是io.shardingjdbc.core.api.algorithm.masterslave.MasterSlaveLoadBalanceAlgorithm,
# 實作類有RandomMasterSlaveLoadBalanceAlgorithm 和 RoundRobinMasterSlaveLoadBalanceAlgorithm,
load-balance-algorithm-type: round_robin
name: dataSource
# 主資料源名稱
master-data-source-name: ds0
# 從資料源名稱,多個用逗號隔開
slave-data-source-names: ds1,ds2
# *** 資料庫分庫分表配置 end
props:
# 列印SQL
sql.show: true
check:
table:
metadata: true
# 是否在啟動時檢查分表元資料一致性
enabled: true
query:
with:
cipher:
column: true
2.4 測驗讀寫分離效果
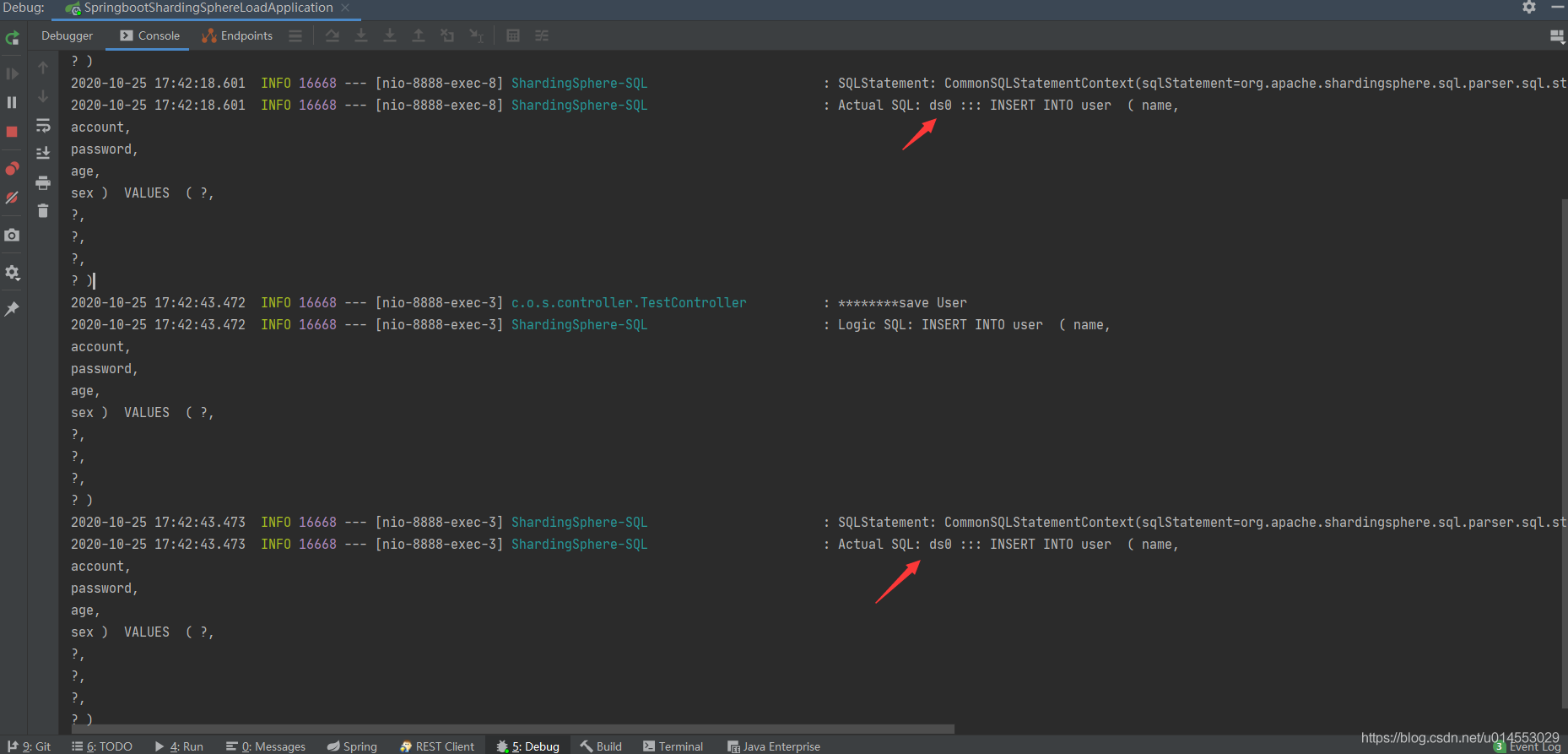
(1)寫入資料,都是寫主庫:
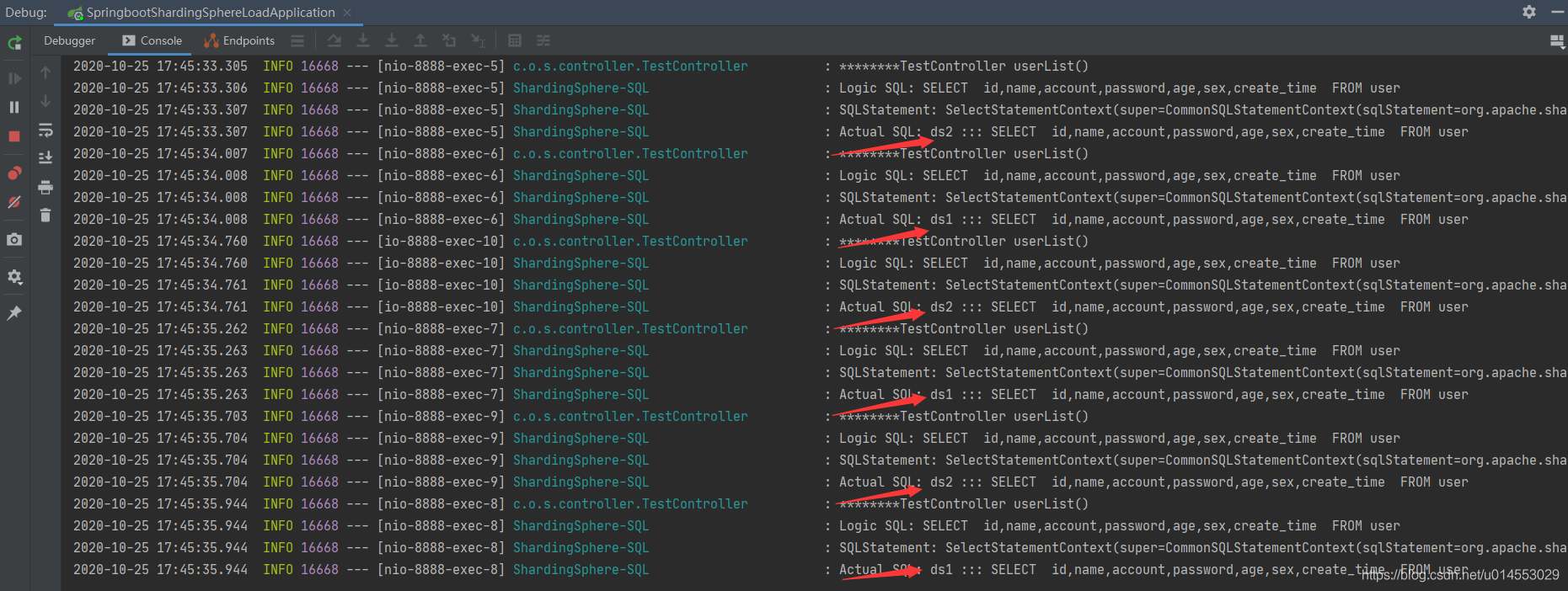
(2)讀取資料,根據規則負載從從庫選擇讀取;
2.5 強制讀取主庫資料
讀延遲問題解決方案:
剛插入一條資料,然后馬上就要去讀取,這個時候有可能會讀取不到?歸根到底是因為主節點寫入完之后資料是要復制給從節點的,讀不到的原因是復制的時間比較長,也就是說資料還沒復制到從節點,你就已經去從節點讀取了,肯定讀不到,mysql5.7 的主從復制是多執行緒了,意味著速度會變快,但是不一定能保證百分百馬上讀取到,這個問題我們可以有兩種方式解決:
(1)業務層面妥協,是否操作完之后馬上要進行讀取
(2)對于操作完馬上要讀出來的,且業務上不能妥協的,我們可以對于這類的讀取直接走主庫,當然Sharding-JDBC也是考慮到這個問題的存在,所以給我們提供了一個功能,可以讓用戶在使用的時候指定要不要走主庫進行讀取,在讀取前使用下面的方式進行設定就可以了:
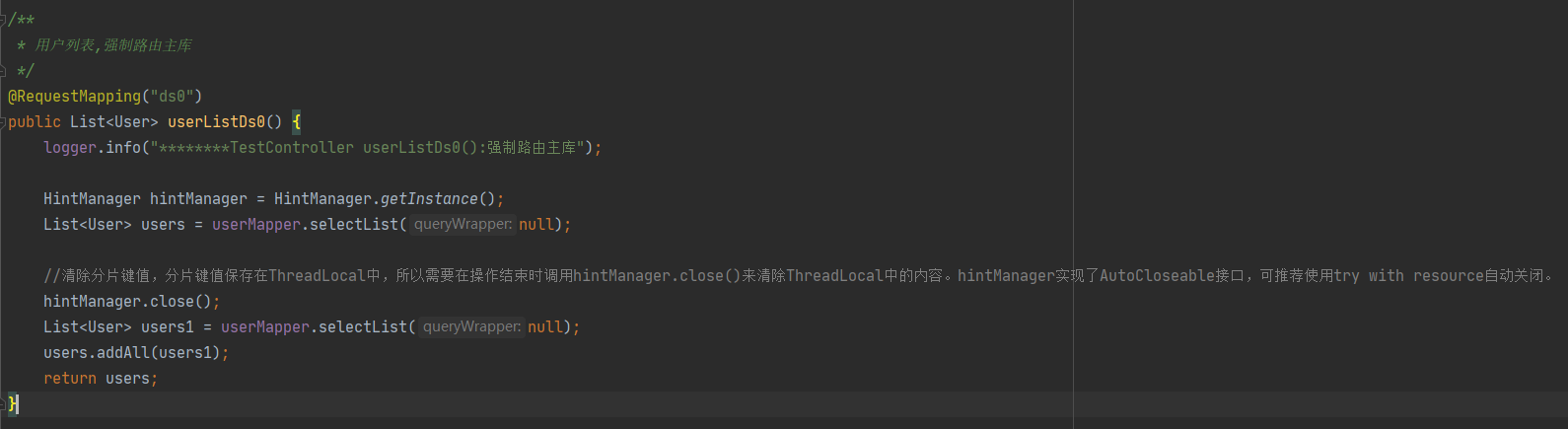
/**
* 用戶串列,強制路由主庫
*/
@RequestMapping("ds0")
public List<User> userListDs0() {
logger.info("********TestController userListDs0():強制路由主庫");
HintManager hintManager = HintManager.getInstance();
List<User> users = userMapper.selectList(null);
//清除分片鍵值,分片鍵值保存在ThreadLocal中,所以需要在操作結束時呼叫hintManager.close()來清除ThreadLocal中的內容,hintManager實作了AutoCloseable介面,可推薦使用try with resource自動關閉,
hintManager.close();
List<User> users1 = userMapper.selectList(null);
users.addAll(users1);
return users;
}
強制路由到主庫:
強制讀取主庫結果:
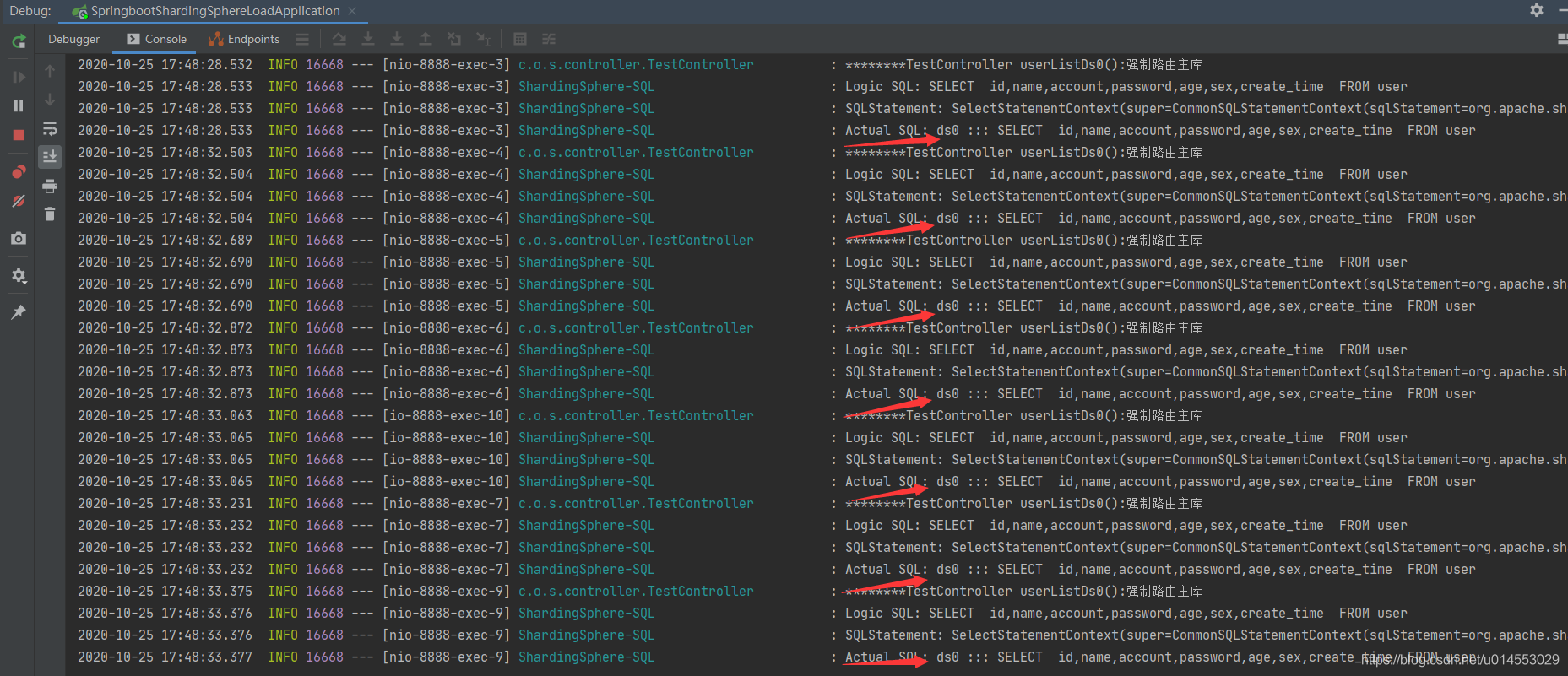
從上圖可以看出,我們設定的強制讀取主庫之后,每次查詢都是去獲取主庫的資料,
官網傳送門:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/usage/read-write-splitting/
原始碼傳送門:https://github.com/oycyqr/springboot-learning-demo/tree/master/springboot-shardingsphere-load
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/192921.html
標籤:java